What is boosting in machine learning?
Boosting is a technique used in machine learning that trains an ensemble of so-called weak learners to produce an accurate model, or strong learner. Learn how it works.

What is boosting in machine learning?
Boosting in machine learning is a technique for training a collection of machine learning algorithms to work better together to increase accuracy, reduce bias and reduce variance. When the algorithms harmonize their results, they are called an ensemble. The boosting process can work well even when each algorithm can only do one thing well.
The main idea behind boosting is to iteratively train weak models on different subsets of the training data; subsequent models are designed to focus more on the examples that the previous models struggled to classify correctly. By doing so, boosting aims to gradually improve the overall predictive accuracy of the model.
"Boosting's ability to sequentially learn from mistakes and focus on challenging examples sets it apart from other ensemble methods," said Marinela Profi, global product market strategy lead for AI and generative AI at SAS.
In boosting, each algorithm separately is considered a weak learner since individually it is not strong enough to make accurate predictions. For example, a dog classification algorithm that decides dog-ness is based on a protruding nose might misidentify a pug as a cat. Bias, in this context, does not pertain to any racial, sexual or other religious factor but rather to the algorithm's narrow focus on a property that does not align with its existing training data, leading to an inability to generalize that the flat-nosed pug is in fact a dog. Variance refers to the algorithm's ability to generalize even when only looking at some subset of the data -- paws, heads or tails, in this case. The algorithm that mistook the pug for a cat based on its snout has a high variance.
 Marinela Profi
Marinela Profi
When an algorithm that is good at detecting snouts is lined up with algorithms that are good at detecting other specific dog properties such as fur, legs or ears, the ensemble is better at discriminating dogs of all species. For instance, in the dog classifier example, a common way of building an object recognition algorithm is to train a neural network to discern animal characteristics such as paws, snouts, fur and faces from subsets of pixels. These subsets are then fed into a decision-tree algorithm, which arrives at a decision from a progression of yes-or-no questions about the data. A decision-tree algorithm that misidentifies dogs with certain novel characteristics -- a weak learner -- becomes what is known as a strong learner when combined with other algorithms that can correctly classify the breeds it misses.
One important characteristic of boosting is that it applies various techniques to balance out the outputs of the different models. If a snout detector model misses out on a picture of a pug, then boosting encourages the other models to compensate.
How does boosting work?
The boosting process works in a mostly serialized manner. Adjustments are made incrementally at each step of the process before moving on to the next algorithm. However, approaches such as XGBoost train all algorithms in parallel, and then the ensemble is updated at the next step (see Figure 1).
Profi likes to think of boosting as a process in which misclassified examples are given higher weights, which enables subsequent models to concentrate on these challenging instances, like the cute pug nose.
"At each iteration, the weak learner is fitted to the training data, and the weights are adjusted accordingly to prioritize the misclassified samples," she said. The final model is an aggregation of all the weak learners, with each learner's contribution weighted based on its performance. These kinds of capabilities are built into most ML training tools to help automate the process.
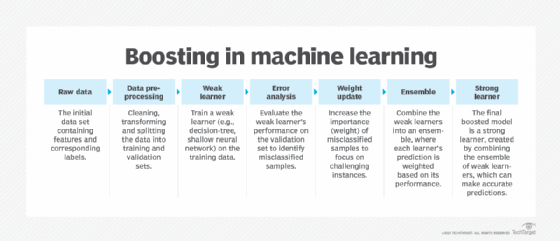
Why is boosting important?
The fundamental reason boosting is important is that it enables data scientists to develop robust models resilient to different types of data. While humans might easily recognize pictures of chihuahuas, greyhounds and pugs as dogs, machine learning algorithms need a bit of help.
"By focusing on difficult examples, boosting helps to tackle complex decision boundaries and capture intricate patterns within the data," Profi explained. In addition, boosting is not as susceptible to overfitting. For example, it can help train a model to recognize that while a fox moves like a cat, it is, in fact, part of the dog family, a canine. This feature makes boosting particularly useful when dealing with noisy or imbalanced data sets.
Types of boosting in machine learning
There are many types of boosting in machine learning. But three of the most popular include the following:
- AdaBoost is an adaptive boosting technique in which the weights of data are adjusted based on the success of each (weak learner) algorithm and passed to the next weak learner to correct. An algorithm that missed a pug's nose in detecting dogs would emphasize the importance of using other features as identifiers for the next algorithm in the chain.
- Gradient boosting is another popular technique in which new algorithms are dynamically crafted on the fly in response to the detection of errors in previous algorithms.
- XGBoost trains an ensemble of algorithms at once and in parallel, and then the weights are adjusted and fed back to all of them collectively to improve the accuracy of the whole. Each algorithm is trained separately across multiple CPUs or GPUs, which reduces the training time and improves performance.
Benefits of boosting
The following are the top benefits of boosting:
- It can use hyperparameter tuning options baked into many common algorithms.
- It can reduce the bias of any one algorithm.
- It can reduce the number of variables or dimensions required to make a decision or prediction, speeding computation.
Drawbacks of boosting
While boosting is a powerful machine learning tool that turns weak learners into strong learners, it does have some drawbacks:
- In some cases, boosting can overfit data, making it hard to extend to new use cases.
- The sequential nature of boosting makes it harder to scale or run for real-time analysis.
- Accuracy can sometimes suffer with outliers outside of the norm.
Boosting vs. bagging
Boosting is one of many tools for getting a bunch of individual algorithms to work well together. Another popular ensemble technique for getting weak learners to work well together is called bagging.
Bagging improves the coordination of multiple weaker algorithms in parallel. Essentially, the training data is divided up, each model is trained in parallel, and then the results are combined into a stronger model.
 Bret Greenstein
Bret Greenstein
"The major difference really lies in the independent training strategy that bagging deploys," said Bret Greenstein, partner and generative AI leader at PwC. However, there are other differences between bagging and boosting involving their respective strategies for sampling the training data and combining the resulting models into a single prediction.
Greenstein has found that both approaches are useful in improving a machine learning model's overall performance to create a more stable model. However, boosting techniques can still be vulnerable to overfitting.
Profi, who is fond of boosting, likes that each model learns from the mistakes of previous models, with a higher emphasis on misclassified examples. She also finds that boosting can help reduce bias, whereas bagging reduces variance. Additionally, boosting assigns weights to training examples, whereas bagging treats all examples equally.
Examples of boosting in different industries
Boosting is widely used across different industries to improve the performance of machine learning ensembles.
 Mona Chadha
Mona Chadha
Mona Chadha, director of category management at AWS, often sees the techniques used for classification tasks, churn prediction, fraud detection and predicting campaign effectiveness.
"Boosting is often recommended when you have a large number of observations in training data, and data has a mixture of numerical and categorical features or just numeric features," she said.
Boosting's ability to produce more accurate predictions, personalized recommendations and improved decision-making have proven useful in a number of industries, according to Profi.
For example, in finance, boosting algorithms are employed for credit scoring, fraud detection and stock market prediction, she explained. In e-commerce, boosting helps in personalized recommendations and customer segmentation, enabling businesses to deliver targeted advertisements and improve customer satisfaction.
Boosting also plays a significant role in healthcare with disease diagnosis and patient risk assessment. "By using boosting algorithms, medical professionals can make more informed decisions and improve patient outcomes," she said.
Greenstein finds boosting helpful in any situation where a single model is underperforming due to poor predictive performance or difficulty generalizing during training time. "Boosting and bagging offer a next step of escalation after initial model experiments produce less than sufficient results," he said.
Editor's note: This article was updated in July 2024 to improve the reader experience.
George Lawton is a journalist based in London. Over the last 30 years he has written more than 3,000 stories about computers, communications, knowledge management, business, health and other areas that interest him.






