What are vision language models (VLMs)?
Vision language models (VLMs) are a type of artificial intelligence (AI) model that can understand and generate text about images. They do this by combining computer vision and natural language processing models. VLMs can take image inputs and generate text outputs. They can, for example, be used to answer questions about images, perform image captioning, and match images and text.
VLMs combine machine vision and semantic processing techniques to make sense of the relationship in and between objects in images. This means combining various visual machine learning (ML) algorithms with large language models (LLMs). Example VLMs include OpenAI's GPT-4, Google Gemini and open source Large Language and Vision Assistant (LLaVA).
VLMs, sometimes called large vision language models, are among the earliest multimodal AI techniques used to train models across various types of data, such as text, images, audio and other formats. The multimodal distinction contrasts with early single-modality LLMs, like OpenAI's GPT series, Google Gemini and Meta's open source Llama.
Early work focused on photos and artwork due to the availability of images with captions for training. However, VLMs also show promise in interpreting other kinds of graphical data, such as electrocardiogram graphs, machine performance data, organizational charts, business process models and virtually any other data type that experts can label. VLMs help connect machine vision models to people's questions about images.
This article is part of
What is GenAI? Generative AI explained
Why are VLMs important?
Traditional ML and AI models focused on one task. They could often be trained to perform well on simple visual tasks, such as recognizing characters in printed documents, identifying faulty products or recognizing faces. However, they frequently struggled with the larger context.
VLMs help bridge the gap between visual representations and how humans are used to thinking about the world. This is where the scale space concept comes into play. Humans are experts at jumping across different levels of abstraction. We see a small pattern and can quickly understand how it might connect to the larger context in which this image forms a part. VLMs represent an important aspect of automating some of this process.
For example, when we see a car with a dent sitting in the middle of the road and an ambulance nearby, we instantly know that a crash probably occurred even though we didn't see it. We start to imagine stories about how it could have happened, look for evidence that supports our hypothesis and think about how we might avoid a similar fate. Sometimes, people write stories about these experiences that can help train an LLM. A VLM can help connect the dots between stories humans write about car crashes and ambulances with images of them.
As another example, when humans look at an image of a person holding a ball with their arm raised and a nearby dog looking up, we know they're playing fetch. We also write many stories involving humans, balls and dogs. VLMs trained on these stories and images of people holding circular shapes connect the dots among balls, humans, dogs and the game fetch to discern a similar interpretation. They can also help interpret many other things that people often describe about images in captions to connect what might be apparent in an image within a larger context.
Analytics tools commonly transform raw data into various charts, graphs and maps to help see patterns and interpret the meaning of data. VLMs use this significant analytics and presentation infrastructure to automate the interpretation of these graphics. They can also connect the visual patterns to the way experts might talk about the data to help democratize and simplify the understanding of complex data streams through a conversational interface.
How VLMs work: Core concepts
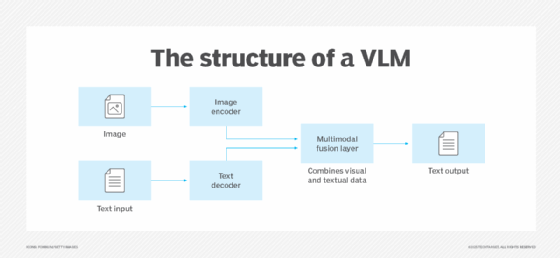
The basic core concept of VLMs is to create a joint representation of visual and textual data in a single embedding space. Various preprocessing and intermediate training steps are commonly involved before joining visual and language elements in training the VLM. This requires more work than training LLMs, which can start with a large text collection. Vision Transformers (ViTs) are sometimes used in this preprocessing step to learn the relationships between visual elements but not the words that describe them. VLMs use ViTs and other preprocessing techniques to connect visual elements such as lines, shapes and objects to linguistic elements. This lets them make sense of, generate and translate between visual and textual data.
The following three elements are essential in a VLM:
- Machine vision. Translates raw pixels into representations of the lines, shapes and forms of objects in visual imagery, such as determining if an image has a cat or a dog.
- LLMs. Processes and contextualizes text, essentially connecting the dots between concepts expressed across different contexts, such as how we might interact with dogs versus cats.
- Fusing aspects. Automates the process of labeling parts of an image and connecting them to words in an LLM, such as describing a dog as sitting, eating, chasing squirrels or walking with its owner.
Limitations of VLMs
Despite the progress VLMs have made in AI, they still have the following limitations:
- Model complexity. Language and vision models are individually complex; combining them increases their complexity.
- Bias. VLMs can inherit biases from their training data. This can lead to the model memorizing incorrect patterns and not learning the actual differences between images.
- Lack of understanding. VLMs don't truly understand the content they learn, as they rely on patterns in data instead of reasoning. This can lead to a VLM failing to capture more nuanced or ambiguous relationships between visual and textual data.
- Hallucinations. VLMs can generate confident-sounding wrong answers, called hallucinations, to questions if it doesn't know a specific answer.
- Generalization limitations. VLMs might struggle to generalize previously unseen data.
- Computational resources. The training and deployment of VLMs require a significant amount of computational resources.
- Ethical implications. The process of obtaining and using data for training is controversial if the data used is gathered from individuals without their consent.
VLM architectures and training techniques
VLMs need much data to learn about the world, starting with pairs of images and text descriptions. Popular open source data sets for various VLM tasks include LAION-5B, Public MultiModal Dataset, Visual Question Answering and ImageNet. Before training, a data collection method should be established, keeping in mind the following three tips:
- Finding data for novel tasks can be tricky, and data scientists must be cautious about bias, particularly when there's an imbalance of samples that relate to the real world. This can be critical when enterprise developers seek data for a particular use case that can vary across different contexts.
For example, there are many images, captions and stories about rabbits on the internet. But these might vary by geography. In the U.S., the stories might be about pets and the Easter Bunny, while in Australia, they might be about wild rabbits as pests and the endangered Easter Bilby. A similar problem could show up in the way different business units or types of experts talk about images. A VLM trained on only one set of stories and captions might struggle when used across various regions, business units, disciplines or teams.
- It's also important to incorporate different image descriptions within the training data. For example, one description might label the animals in the image, another might mention a ball and raised arm, while a third description might include the game fetch. More nuanced descriptions might talk about the types of grass, clouds in the sky, the outfit a person is wearing or the brand of leash used on the dog. The challenge is curating a selection of training data that might discuss these various image aspects.
- The training process must also help distinguish between similar-looking but different things. For example, a pug has a cat-like face, but humans can quickly identify a picture of it as a dog. Models, therefore, need to be trained on many images of dogs and cats with unusual shapes, sizes and forms.
There are many approaches to training a VLM once a team has curated a relevant data set. The process sometimes starts with a pretraining step that maps visual data to text descriptions, which is later fused to an existing LLM. In other cases, the VLM is trained directly on paired images and text data, which can require more time and computing resources but might deliver better results. In both approaches, the base model is adjusted through an iterative process of answering questions or writing captions. Based on how well the model performs, the strength of the connections within the answers -- known as neural weights -- is adjusted to reduce mistakes. These can sometimes be combined to enhance accuracy, improve performance or reduce model size. The following are a few examples of different learning models.
Contrastive learning
Models like OpenAI's Contrastive Language-Image Pre-training (CLIP) learn to discern similarities and differences between pairs of images like dogs and cats and then apply text labels to similar images fed into an LLM. Open source LLaVA uses CLIP as part of a pretraining step, which is then connected to a version of the Llama LLM.
PrefixLM
Models like SimVLM and VirTex directly train a transformer across sections of an image and a sentence stub, or prefix, that's good at predicting the next set of words in an appropriate caption.
Multimodal fusing with cross attention
Models like VisualGPT, VC-GPT and Flamingo fuse visual elements to the attention mechanism in an existing LLM.
Masked language modeling and image-text matching
Models like BridgeTower, FLAVA, LXMERT and VisualBERT combine algorithms that predict masked words with other algorithms that associate images and captions.
Knowledge distillation
Models like ViLD distill a larger teacher model with high accuracy into a more compact student model with fewer parameters that runs faster and cheaper but retains similar performance.
Metrics for evaluating VLMs
Evaluating the performance of a VLM is a highly subjective process that can vary across individuals, their expertise and task type. Researchers have developed a variety of metrics that can help automate and standardize the evaluation of VLM performance across different kinds of tasks. Popular metrics include the following:
- Bilingual Evaluation Understudy. BLEU compares the number of words in a machine translation to a human-curated reference translation.
- Consensus-based Image Description Evaluation. CIDEr compares machine descriptions to a reference description curated by a consensus of human evaluators.
- Metric for Evaluation of Translation with Explicit Ordering. METEOR measures the precision, order, recall and human quality assessments of descriptions or translations.
- Recall-Oriented Understudy for Gisting Evaluation. ROUGE compares the quality of a VLM-generated description to human summaries.
VLM use cases
Some of the many applications of VLMs include the following:
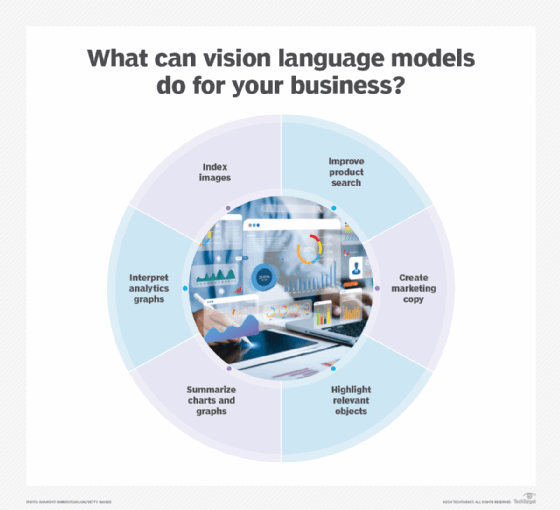
- Captioning images. Automatically creates descriptions of images, aiding efforts to index and search through a large library of imagery.
- Visual question answering. Helps uncover insights in images for users with different levels of expertise to improve understanding and analysis.
- Visual summarization. Writes a brief summary of visual information in an org chart, medical image or equipment repair process.
- Image text retrieval. Helps users find images of things that relate to their query, such as finding a product using a different set of words than its official product description.
- Image generation. Helps someone create a new image in a particular style based on a text prompt.
- Image annotation. Highlights sections of an image with colors and labels to indicate areas relating to a query.
Brief history of VLMs
The history of VLMs is rooted in developments in machine vision and LLMs and the relatively recent integration of these disciplines.
Machine vision research dates to the early 1970s when researchers began exploring various ways to extract edges, label lines, identify objects or classify conditions. Throughout the 1980s and 1990s, researchers investigated how scale space -- a way of representing images at different levels of detail -- could help align views of things across various scales. This led to the development of algorithms that could connect multiple levels of abstraction. For example, this might help create imagery of cells, organs and body parts in medicine. Similar relationships exist across business processes, biology, physics and the built environment. This refers to the human-made settings that enable activities, such as urban planning and public infrastructure.
Later, researchers started developing feature-based methods that helped characterize defects based on images of products passing down an assembly line. However, this was an expensive and manual process. Innovations in convolutional neural networks and their training process helped automate much of this work.
On the language side, work in the early 1960s focused on improving various techniques to analyze and automate logic and the semantic relationships between words. Innovations in recurrent neural networks (RNNs) helped automate much of the training and development of linguistic algorithms in the mid-1980s. However, they struggled with long sentences or long sequences. Later innovations, such as long short-term memory, a special type of RNN, extended these limits.
The next wave of advances came in the 2010s with the development of generative AI (GenAI) algorithms that addressed various ways to represent reality in intermediate forms that could be adjusted to create new content or discern subtle patterns. Diffusion models were good at physics and image problems that involved adding and removing noise. Generative adversarial networks were good at creating realistic images by setting up a competition between generating and discriminating algorithms. Variational autoencoders found better ways to represent probability distributions best suited for sequential data.
The big breakthrough was the introduction of the transformer model by a team of Google researchers in 2017. This lets a new generation of algorithms simultaneously consider the relationship between multiple elements in longer sentences, paragraphs and, later on, books. More importantly, it paved the way for automating the training of algorithms that could learn the connections between semantic elements that reflect how humans interpret the world and the raw sights, sounds and text they're presented.
It took another four years for multimodal algorithms to take hold in the research community, as not many computer scientists considered capturing the world in terms of noise, neural networks or probability fields.
In 2021, OpenAI introduced its foundation model CLIP, which suggested how LLM innovations might be combined with other processing techniques.
Stability AI -- in conjunction with researchers from Ludwig Maximilian University of Munich and Runway AI -- introduced Stable Diffusion in 2022, combining LLMs and diffusion models to generate creative imagery. Since then, various other research and commercial projects have explored how transformer models could be combined with GenAI techniques and traditional ML approaches to connect visual and language domains.

Future of VLMs
VLMs, like LLMs, are still prone to hallucination, so guardrails are currently required with high-stakes decisions. A VLM might tell a trained radiologist where to look in an image, but it shouldn't be fully trusted to make a diagnosis independently. Similarly, a VLM might help frame important questions about the business, but subject matter experts should be consulted before rushing to any major decision.
Additionally, VLMs currently generate their results based on the complex relationships captured in the weight of billions of features. This can make it difficult to decipher how they arrived at a particular decision or adjust them when mistakes are made.
Ongoing research is looking at combining different metrics that can improve performance across multiple types of tasks. For example, a newer Attribution, Relation and Order benchmark measures visual reasoning skills better than traditional metrics developed for machine translation. More work is also required to develop better metrics for various use cases in medicine, industrial automation, warehouse management and robotics.
Zero-shot learning will also likely improve over time. Large VLMs already have some degree of zero-shot learning capability, which enables them to generalize to unseen tasks with minimal additional training. As this improves, VLMs will become more versatile and applicable to different settings.
Despite the many challenges, VLMs represent an exciting opportunity to apply GenAI techniques to visual information. Researchers, vendors and enterprise data scientists continue to find ways to improve their performance, apply them to existing business workflows, and improve the user experience for employees and customers.
Training AI models can be a complex task. Learn more about how to train LLMs on your own data.
Continue Reading About What are vision language models (VLMs)?
Dig Deeper on Artificial intelligence platforms
-
![]()
Generative models: VAEs, GANs, diffusion, transformers, NeRFs
By: Chris Tozzi
-
![]()
Explore real-world use cases for multimodal generative AI
By: George Lawton
-
![]()
What is Gemma? Google's open sourced AI model explained
By: Sean Kerner
-
![]()
SLM series - Cloudinary: The role of SLMs in visual media
By: Adrian Bridgwater



