Data science's ongoing battle to quell bias in machine learning
Machine learning expert Ben Cox of H2O.ai discusses the problem of bias in predictive models that confronts data scientists daily and his techniques to identify and neutralize it.

Bias in machine learning models can lead to false, unintended and costly outcomes for unknowing businesses planning their future and victimized individuals planning their lives. This universal and inherent problem and the techniques to solve it weigh on the minds of data scientists working to achieve fair, balanced and realistic insights.
Planner, builder, tester and manager of machine learning models, Benjamin Cox contends daily with the issues surrounding bias in machine learning and its deleterious effects. As director of product marketing at H2O.ai, Cox leads responsible AI research and thought leadership. He also co-founded the AI innovation lab at Ernst & Young and has led teams of data scientists and machine learning engineers at Nike and NTT Data.
"I became deeply passionate about the field of responsible AI after years working in data science and realizing there was a considerable amount of work that needed to be done to prevent machine learning from perpetuating and driving systemic and economic inequality in the future," he said. "In a perfect world, instead of allowing algorithms to perpetuate historical human bias, we can use them to identify that bias and strip it out and prevent it."
In this interview, Cox discusses his daily encounter with bias in machine learning models and shares the steps he and his team take to identify and neutralize it.
Beyond awareness of inherent bias in collected and processed data, what tools and techniques can data scientists and managers use to recognize, reduce and overcome data bias that can corrupt machine learning data sets and outputs?
Ben Cox: Data bias is tricky because it can arise from so many different things. As you have keyed into, there should be initial considerations of how the data is being collected and processed to see if there are operational or process oversight fixes that exist that could prevent human bias from entering in the data creation phase.

The next thing I like to look at is data imbalances between classes, features, etc. Oftentimes, models can be flagged as treating one group unfairly, but the reason is there is not a large enough population of that class to really know for certain. Obviously, we shouldn't use models on people when there's not enough information about them to make good decisions.
Then I would check to see which inputs are correlated with protected variables and with the training label. This is a big red flag. Additionally, all of the classic descriptive statistics and exploratory data analysis exercises like checking for anomalies, outliers and potentially corrupt data.
I think about it like this: Say in a credit decision model, ethnicity or race should not be used in the predictive model and we have some base feature like 9-digit zip code, which has a 95% correlation to a specific ethnicity -- which can and does happen. This feature -- zip code -- can act as a proxy for that protected attribute -- ethnicity or race. This gets especially true if we are using feature engineering and you can create interaction features between zip code, income, age, education, etc. Basically, if we say ethnicity is not to be used to drive credit decisions, we also need to make sure the model isn't just reverse engineering ethnicity by way of other attributes.
How can interpretability and explainability reduce bias in predictive outcomes?
Cox: Machine learning interpretability [is about] how transparent model architectures are and increasing how intuitive and understandable machine learning models can be. It is one of the components that we believe makes up the larger picture of responsible AI.
Put simply, it's really hard to mitigate risks you don't understand, which is why this work is so critical. By using things like feature importance, Shapley values, surrogate decision trees, we are able to paint a really good picture of why the model came to the conclusion it did -- and if the reason it came to that conclusion violates regulatory rules or makes common business sense.
That said, we typically want to use traditional tests that can work on black-box models to find bias. We use interpretability to diagnose and fix bias.
Will new technologies like augmented and automated machine learning that alter the amount of human influence in building, running, monitoring and adjusting predictive models ease or complicate bias?
Cox: This is something of a double-edged sword because, depending on how it's deployed, it could be either. For us specifically, we automate the entire machine learning interpretability dashboard toolkit and model documentation so users can very easily analyze what the autoML system developed. I believe these two should go hand in hand because otherwise deploying autoML systems without trying to figure out what the algorithms are doing could drive risk.
At times, is bias in some form a necessary element in formulating a realistic and useful machine learning model, depending on the application?
Cox: The statistical definition of bias is different than the definition of bias we use conversationally. The answer to this question is yes, we need to use the signal driving features to form our predictions, but we as practitioners have to make sure what is driving signal isn't problematic.
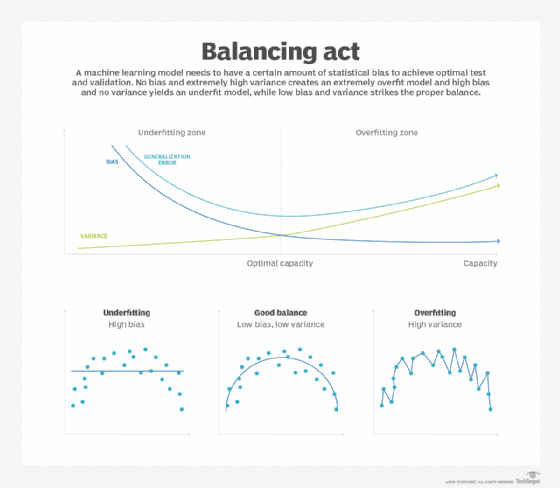
So when I say 'good bias' or 'machine learning bias' as a statistician, I am referring to mean-variance trade-off, a concept taught in machine learning often. Basically, the idea is that we need our model to have an amount of statistical bias to find the optimal test and validation out-of-sample performing model. If we have no bias but extremely high variance, we have essentially created an extremely overfit model. This is some of the nuances of data science and understanding the underlying business problem you are trying to solve when you think about how to tune these models based on various levers.
To be clear though, this is not saying some amount of human bias against a protected class is good.
What role has bias in machine learning algorithms played in COVID-19 predictive model outcomes, insights and actions -- for better or worse -- over the past several months?
Cox: I think there was a significant amount of talk around 'COVID-19 is breaking all the models,' but that is a little deceiving. Models performing worse under extreme volatility and uncertainty is somewhat standard, but what COVID-19 may have done is really shine a light on models that were very overfitted to extremely linear and stable market scenarios.
Hopefully, what practitioners take away from these anomalous situations is aiming to build the most interpretable with the highest predictive power. The balance between signal and stability is key for creating models that are more resilient to shocks.
What else can be done to eliminate bias in machine learning models?
Cox: One exercise that I think is really, really insightful is to do a review of the models' false positives and false negatives -- in addition to traditional disparate impact testing. Looking under the hood at case-by-case examples and general profiles of missed predictions can be tremendously informative to what profiles tend to cause the model to miss.
Another forward-looking solution is machine learning models that learn to balance accuracy and bias automatically. But we really like to have a broader conversation about the people, process and technology components that go into the larger responsible AI lifecycle. It requires good operational practices not just technological tools at hand.
Dig Deeper on Machine learning platforms
-
![]()
Large Language Model Diagnoses, Triages Without Introducing Biases
By: Shania Kennedy
-
![]()
Deterioration Index Model Modestly Predicts Patient Outcomes
-
![]()
Omitting Race, Ethnicity from Risk Models May Lead to Health Disparities
By: Shania Kennedy
-
![]()
Machine-Learning Models Can Accurately Predict Hypertension Risk
By: Shania Kennedy



