Breaking the cycle of algorithmic bias in AI systems
As powerful organizations begin to integrate models such as GPT-4, ensuring fair and equitable access to resources of all kinds requires open discourse about algorithmic bias in AI.
Bias is often viewed as a human problem: the product of imperfect brains, rather than supposedly impartial AI systems. But AI models not only reflect human biases, they can amplify them at a massive scale, in ways that are challenging to detect and prevent.
Even prior to the launch of ChatGPT, more than a third of organizations were already using AI and another 42% were exploring doing so, according to a 2022 IBM report. But in the same survey, nearly three-quarters of the respondents said they hadn't taken steps to reduce unintended bias in their models. This growing adoption, combined with the lack of attention to algorithmic bias in AI, worries experts.
"Right now, we have systems that are massively discriminating against marginalized people within the U.S. and in other parts of the world based on AI, and I think we're not really addressing that," said Jesse McCrosky, principal data scientist and head of sustainability and social change at Thoughtworks and co-author of a recent Mozilla Foundation report on AI transparency.
Because governments and corporations increasingly use AI to make critical decisions, developing AI responsibly is also critical. Preventing algorithmic bias means considering fairness and discrimination throughout model development -- and continuing to do so well after deployment.
What causes algorithmic bias in AI?
Bias in AI systems starts at the data level. "To build better systems, we need to focus on data quality and solve that first, before we send models to production," said Miriam Seoane Santos, a developer advocate at YData and machine learning (ML) researcher.
The performance of an AI system depends heavily on the underlying data used in model training, meaning that the final model will reflect biases in that data and how it was collected. A model trained on a data set with insufficient data representing minority groups will yield worse outcomes for those groups.
We are the ones collecting the data. We are the ones deciding what goes or doesn't go into the development of the system.
Miriam Seoane SantosDeveloper advocate, YData
"An area that's increasingly being looked into [in responsible AI] is data curation itself: making sure that you have representative data for all groups and that it's being collected in an ethical way," said Perry Abdulkadir, an algorithmic fairness and data science consultant at SolasAI.
Santos mentioned a 2018 paper by researchers Joy Buolamwini and Timnit Gebru, who found that facial recognition systems identified light-skinned male faces far more accurately than dark-skinned female faces. Deploying such a model in a self-driving car, for example, could be catastrophic, Santos said: The software's failure to recognize a Black pedestrian in a crosswalk would directly endanger that person's life.
These findings underscore the importance of human oversight by diverse teams throughout model development. "It's not exactly that the data itself is dirty in some way," Santos said. "It also has to do with human aspects. We are the ones collecting the data. We are the ones deciding what goes or doesn't go into the development of the system."
Understanding how to handle sensitive data
Issues also arise around data collected for use in AI systems that reveal characteristics such as race, age and gender.
Some teams concerned about algorithmic bias might choose to remove or obscure these attributes, hoping to minimize their influence over model decisions. But simply hiding or attempting to ignore such information isn't necessarily possible or desirable.
In certain contexts, that data is necessary to build an accurate and ethical model. Santos, whose background is in biomedical engineering, gave the example of a model used to predict breast cancer, for which factors including an individual's age and medical history could be highly relevant.
If the data set doesn't adequately represent categories such as younger women, "your healthcare accuracy will be very biased toward one of the subgroups," she said. "And this can have real consequences for people trying to get fair treatment or personalized treatment."
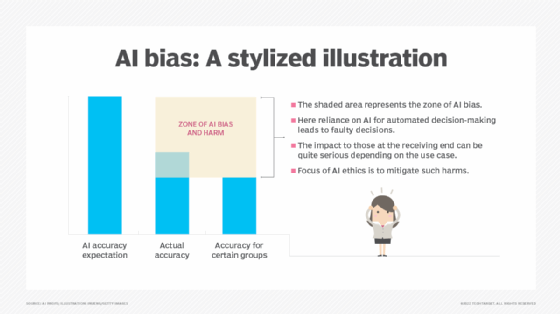
Overreliance on AI for automated decision-making can cause serious harm, especially to underrepresented groups.
"Oftentimes, in these AI and ML models, disparities will arise in sort of counterintuitive ways," Abdulkadir said. "There may be features that you think would be extremely problematic, which it turns out are not actually necessarily driving disparity, and vice versa."
For example, gathering information such as physical address or ZIP code could be perfectly legitimate for certain use cases. But that information can also indirectly reveal an individual's race due to historical patterns such as redlining.
"In our models [at FICO], there's no way we allow that ZIP code type of information, because it's a clear proxy for race and income," said Scott Zoldi, chief analytics officer at FICO. "We just have to say, yes, you might be able to get a better model, but it would propagate the same bias that we have in society today."
Some proxies might be less immediately obvious. Abdulkadir gave the example of convenience store purchasing behavior, which is sometimes used in lending models as an indicator of risk: A person with high convenience store spending might frequently buy items such as alcohol and lottery tickets, the thinking goes, which could suggest lower creditworthiness.
"Setting aside how tenuous that connection might be in the first place," Abdulkadir said, "that sort of logic breaks down very quickly when you look at the sociological story of why people visit convenience stores."
Taking a human inventory of the data and potential problems that could arise is an important first step to creating a fair model. After that initial review, development teams can look into potentially problematic features in greater depth, including determining whether they're functioning as proxies for protected characteristics.
Santos emphasized the importance of involving diverse teams in this process and in treating algorithmic bias considerations as a standard part of evaluating models. "Look for issues like imbalanced data, subgroup protection, finding the best fairness metrics to give feedback to your system," she said. "Instead of focusing only on performance, try different metrics."
In addition to considering these factors when designing and analyzing models, an essential part of improving algorithmic fairness is improving transparency, interpretability and accountability once a model is deployed. "After the model is in production, you have to guarantee that the system can somehow be audited so that it will adjust," Santos said. "Not a one-shot and one-time-only thing, but it can receive feedback when its predictions are not fair or are erroneous in some way."
AI models generate predictions in complicated ways, using complex interactions among hundreds or thousands of features. Understanding why a model made a given prediction can thus be difficult for even the model's developers, a phenomenon known as the black box problem -- and that phenomenon is exacerbated when businesses avoid transparency due to competitive pressures.
"Our governments, our regulatory bodies, our civil society, our researchers, our journalists [need] to be able to have meaningful conversations about what sort of society we're building as we release these technologies," McCrosky said. "But I think it's very difficult to have those conversations when so much of the work happens in a black box or behind closed doors. ... I think there really is a moral imperative for greater transparency."
Responsible AI is emerging as a necessary discipline in light of increasing large-scale deployments of complex and powerful AI systems.
Changing that calls for more open approaches to model development and analysis. Zoldi, who is optimistic about blockchain as a way to immutably record the process of model development, said he's considering open sourcing parts of the blockchain-based model development standard used at FICO to promote auditability.
"[The blockchain] stores all the learnings and knowledge of what variables have been accepted in the past, which ones are problematic, which ones are not allowed," Zoldi said. "Because we don't want people to reinvent things that we've already outlawed or determined not acceptable to use."
Improving transparency and interpretability should include making room for feedback, Santos said. Often, the individuals affected by AI models' decisions have no way to understand or push back against those outcomes, despite how significant the consequences can be.
"For them, it means having or not having the loan, getting or not getting the job, having to face the end-of-life decision or get access to that particular new treatment," Santos said. In such cases, "you need to be able to get those results given to you and a basic explanation of why -- some basic information on what data are they collecting about you that made the results what they are."
The evolving landscape of responsible AI
The conversation around algorithmic bias in AI isn't new. Researchers such as Gebru and Buolamwini, among many others, have raised AI ethics issues for years.
But historically, voicing such concerns hasn't always been well received. In 2020, Google terminated Gebru following a dispute over a research paper she wrote regarding concerns of algorithmic bias in large language models such as GPT-3.
More recently, big tech companies including Microsoft, Meta and Twitter have laid off AI ethics staff amid steeply rising interest in deploying AI and ML. "That Microsoft one -- they don't want to hear that their investment in OpenAI may not be right," Zoldi said, "whereas you need to hear that."
Regardless, increasingly widespread use of AI systems and looming AI regulations mean that the conversation might be harder for companies to avoid moving forward. "The technology is getting to the point that it's actually forcing these conversations to be taken more seriously and to move faster," McCrosky said -- although he noted that, often, "things move too fast for regulatory processes to keep up in time these days."
Particularly in tightly regulated industries such as banking and healthcare, corporate interests in responsible AI tend to be driven by regulatory requirements and the bottom line. But experts are also hopeful about the emergence of more sincere ethical commitments.
Acknowledging that compliance and reputational risk play important roles in business decisions, Abdulkadir said he's also seen more genuine interest in AI ethics at the individual level, including a willingness to go beyond what's legally required. Zoldi described a similar change over the course of his time serving on an advisory board for the nonprofit FinRegLab.
"Even on the Hill, this concept of interpretability was being embraced," Zoldi said. "So I think people are getting it. I'm just hoping that in a few more years, we'll get there."