Basic disassembly: Decoding the opcode
Programmers can find benefit from disassembling object code–a lost art that begins with understanding the opcode.

Disassembling object code is a disappearing art. However, it is still a valuable skill for technicians who have to look through dumps, even if he or she can access the original source. This tip is a short introduction intended to jump-start the beginner on decoding the instruction operation code (opcode).
In this tip, I reference the z/Architecture Principles of Operations (PROPS) and the z/Architecture Reference Summary. The page numbers mentioned later are from those documents and may change with subsequent versions of the manuals. This tip also assumes some working knowledge of Z-machine architecture and assembly language.
The basics
Disassembly begins with decoding the instruction opcode. The opcode is part of the machine language instruction that defines the operation being performed, and often includes one or more operands which the instruction will work upon.
You can find a list of instruction formats in the Architecture Reference Summary. The PROPS lists the format with each instruction in chapters seven through 11.
The instruction format is drawn as a rectangle that is broken into boxes representing fields. Below the left side of each box is the field’s beginning bit offset. Inside the box is a label describing what the field represents. For example, Op Code or Op represents the opcode. Labels beginning with R denote a general register specification and M represents masks. L fields are lengths. Some instructions have other designations, such as B for base and X for index registers, along with D for offset. The processor adds the two registers and offset together to come up with an operand memory address.
The letter I stands for immediate operands, where the data is part of the instruction itself. These types of instructions tend to be faster, because the CPU doesn’t have to fetch the operand from memory.
The subscript after each label tells you which operand the field represents. For example, in a load register (LR), instruction data moves from the second operand (R2) to the first (R1).
Note that object code length fields are one less than the length coded in the Assembler source. You can see this in the move character (MVC) instruction, where the target length will be eight in the source code, but seven in the generated machine instruction. This small adjustment allows instructions to extend their reach. It’s easy to understand if this all sounds a bit confusing. Higher-level languages are often much easier to read and follow than the arcane, low-level coding used in assembler. Proficiency takes practice, so take the time to become familiar with the Z architecture. Although training can be expensive, a good assembler book will provide a grounding that can be expanded with experience.
Finally, note that older, more basic instructions contain the opcode in their first byte. Newer instructions’ opcode may be split between operands. You can easily identify the new instruction types, because the opcode listed in the manuals will be longer than one byte.
An example
A common debugging technique involves going to the instruction that the program status word (PSW) points to at the time of an error and working backward to find out how the program got there. Below is an example of a typical subroutine entry sequence, as it might appear in a dump after a storage protection exception (0C4) ABEND. We want to disassemble this bit of code to see what went wrong.
For the purposes of demonstration, we’ll assume the PSW pointed to the instruction highlighted in yellow.
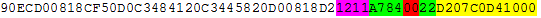
The table in the PROPS’ third section of appendix B (page B-41) lists instructions by opcode. The first byte of the instruction is x’D2,’ and it corresponds to a MVC instruction, as shown in the third column. The last column points to the instruction description (pages 7-232).
The format diagram at the beginning of the MVC doc allows us to break down the instruction as follows:
- 1 byte opcode (x’D2’)
- 1 byte length (x’07’)
- 1 byte base register for the first operand (x’C’ for register 12)
- 3 byte offset from first the base register (x’0D4’)
- 1 byte base register second operand (x’1’ for register 1)
- 3 byte offset from the second base register (x’000’)
So, this instruction wanted to copy 8 bytes of data from offset +0 from register one to the memory +D4 from register 13. Or, as originally coded:
MVC 212(8,12),0(1)
Since the 0C4 occurred on this move instruction, we may assume one of the base registers, 12 or 1, was invalid. For our purposes, we can see from the registers at the time of the error that register 1 was high values (x’FFFFFFFF’), which is an invalid source address. Now we need to figure out how it got that way.
Next, we have to move back to the previous instruction. Since the minimum instruction length is a halfword, we go back two bytes from the previous instruction’s address, which puts us at x’00’ (in red).
Zero is not a valid opcode, which means we have to retreat two more bytes (in green) to the x’A7’. Unfortunately, appendix B’s opcode table (page B-44) lists 18 three-nibble operation codes beginning with x’A7,’ meaning this is a split opcode instruction. However, it looks like all of the A7 opcodes have a common RI-type format. Going to the first section of the architecture summary, we see that all the RI format instruction’s OPCODEs are split between the first byte and the fourth nibble. For our instruction, we can combine the first byte’s A7 with the x’4’ in the fourth nibble to create an operation code of A74, which represents a branch relative on condition (BRC) instruction. Following the RI-c format, it breaks down as follows:
- 1 byte operations code (x’A7’)
- 1 nibble condition code mask (x’8), which will be tested against the condition code to see if the CPU should take the branch.
- 1 nibble opcode (x’4’)
- 2 byte immediate field (x’0022’). The CPU doubles this value to find the branch’s target address relative to the current instruction’s location.
Sadly, we can’t know what this branch is for until we understand the comparison that preceded it. Backing up two more bytes brings us to an x’12’ (in purple). Trusty appendix B equates the x’12’ with a load and test register (LTR) instruction. The instruction description (pages 7-29) and format diagram break the instruction down as follows:
- 1 byte opcode (‘x12’)
- 1 nibble first register operand (x’F’)
- 1 nibble second register operand (x’F’)
Or, as originally coded:
LTR 15,15
When the first and second registers are the same for this instruction, the programmer probably intended to test the register contents and branch if they are zero. With this assumption, we can consult the extended mnemonic section (page 43 in the summary) and infer the original branch instruction may have been coded as jump on zero (JZ), which brings the three instruction sequence to (comments added for clarity):
LTR 1,1 Is register 1 zero?
JZ *+68 No, go to recovery routine
MVC 212(8,12),48(1) Yes, copy data at R1
Since this is subroutine entry logic, we understand that, by convention, register 1 should point to a parameter passed by the calling program. However, in this case, the caller passed a bad parameter address (high values) that caused the 0C4.
Decoding
Distinguishing opcodes from data and operands sometimes makes disassembly difficult. However, there are several common-sense rules for staying on track.
First, most programmers and compilers pool literals and constants into easily identifiable sections of a program. Therefore, it’s usually not worthwhile to disassemble a stretch of memory containing human-readable messages or strings.
While system-level code and applications mostly use the same instructions, there is a subset of opcodes that are considered “privileged” and reserved for executive software. If you’re debugging an ordinary COBOL program, but find yourself looking up privileged or semi-privileged instructions in Chapter 10 of the PROPS, you may be off.
Another sanity check involves watching the logic flow. Once you understand the basic operation of machine instructions, you can tell how they might apply to an overarching algorithm. In other words, you might not be on the right track if the decoded instructions appear to be loading registers at random or branching with a preceding test.
If the going gets too complicated, there are a variety of disassemblers available in the form of freeware at CBTTAPE.org, and commercially. Remember, however, that disassemblers aren’t as good as humans at applying a little common sense and may sometimes misinterpret object code and point in the wrong direction.
About the expert: Robert Crawford has been a systems programmer for 29 years. While specializing in CICS technical support he has also worked with VSAM, DB2, IMS and assorted other mainframe products. He has programmed in Assembler, Rexx, C, C++, PL/1 and COBOL. The latest phase in his career finds him an operations architect responsible for establishing mainframe strategy and direction for a large Insurance company. He lives and works with his family in south Texas.






