What is pipelining?
Pipelining is the process of a computer processor executing computer instructions as separate stages. The pipeline is a logical pipeline that lets the processor perform an instruction in multiple steps. Several instructions can be in the pipeline simultaneously in different stages. The processing happens in a continuous, orderly, somewhat overlapped manner.
In computing, pipelining is also known as pipeline processing. It is sometimes compared to a manufacturing assembly line in which different product parts are assembled simultaneously, even though some parts might have to be assembled before others. Even with some sequential dependency, many operations can proceed concurrently, facilitating time savings.
Consider a car factory. Without pipelines, the factory can only work on one car at a time. With an assembly line, different stations can work on different cars simultaneously. One car can have the engine installed, another the doors put on, while a third is painted. Working this way greatly increases the number of cars that can be finished.
Computer processor pipelines work like factory assembly lines. Consider the simple instruction "add A + B and put the result in C." First, the memory management unit (MMU) gets the value A and value B. Then, the arithmetic-logic unit (ALU) adds them together. Lastly, the MMU stores the new value in C. While the ALU adds A and B, the MMU can work on another operation, like getting value D.
Pipelining creates and organizes a pipeline of instructions the processor can execute in parallel.
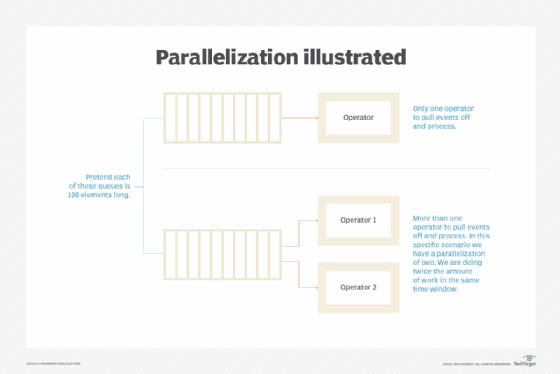
Creating parallel operators to process events is efficient. The pipeline is divided into logical stages connected to each other to form a pipelike structure. Instructions enter from one end and exit from the other.
Pipelining is an ongoing, continuous process in which new instructions, or tasks, are added to the pipeline, and completed tasks are removed at a specified time after processing completes. The processor executes all the tasks in the pipeline in parallel, giving them the appropriate time based on their complexity and priority. Any tasks or instructions that require processor time or power due to their size or complexity can be added to the pipeline to speed up processing.
How pipelining works
Without a pipeline, a processor would get the first instruction from memory and perform the operation it calls for. It would then get the next instruction from memory and so on. While fetching the instruction, the arithmetic part of the processor is idle; it must wait until it gets the next instruction. This delays processing and introduces latency.
With pipelining, the next instructions can be fetched while the processor is performing arithmetic operations. These instructions are held in a buffer or register close to the processor until the operation for each instruction is performed. This staging of instruction fetching happens continuously, increasing the number of instructions completed in a given period.
Within the pipeline, each task is subdivided into multiple successive subtasks. A pipeline phase is defined for each subtask to execute its operations. Each stage or segment receives its input from the previous stage, then transfers its output to the next. The process continues until the processor has executed all instructions and all subtasks are completed.
In the pipeline, each segment consists of an input register that holds data and a combinational circuit that performs operations. The output of the circuit is applied to the input register of the next segment. Here are the steps in the process:
Types of pipelines
There are two types of pipelines in computer processing.
Instruction pipeline
The instruction pipeline represents the stages in which an instruction is moved through the various segments of the processor: fetching, buffering, decoding and executing. One segment reads instructions from memory, while simultaneously, previous instructions execute in other segments. Since these processes happen in an overlapping manner, system throughput increases. The pipeline's efficiency can be increased by dividing the instruction cycle into equal-duration segments.
Arithmetic pipeline
The arithmetic pipeline represents the parts of an arithmetic operation that can be broken down and overlapped as performed. It can be used for arithmetic operations, like floating-point operations, multiplication of fixed-point numbers, etc. Registers store any intermediate results that are then passed to the next stage.
Advantages of pipelining
The biggest advantage of pipelining is reducing the processor's cycle time. It can process more instructions simultaneously, while reducing the delay between completed instructions. Although pipelining doesn't reduce the time taken to perform an instruction -- this would still depend on its size, priority and complexity -- it increases throughput. Pipelined processors usually operate at a higher clock frequency than the RAM clock frequency. This makes the system more reliable and supports global implementation.
Possible issues in pipelines
While useful, processor pipelines are prone to certain problems that can affect system performance and throughput.
Data dependencies
A data dependency happens when an instruction in one stage depends on the results of a previous instruction, but that result is not yet available. This occurs when the needed data has not yet been stored in a register by a preceding instruction because that instruction has not yet reached that step in the pipeline.
Since the required instruction has not been written yet, the following instruction must wait until the required data is stored in the register. This waiting causes the pipeline to stall. Meanwhile, several empty instructions, or bubbles, go into the pipeline, further slowing it down.
The data dependency problem can affect any pipeline. However, it affects long pipelines more than shorter ones because in the former, it takes longer for an instruction to reach the register-writing stage.
Branching
Branch instructions can be problematic in a pipeline if a branch is conditional on the results of an instruction that has not yet completed its path through the pipeline. If the present instruction is a conditional branch, and its result will lead to the next instruction, the processor might not know the next instruction until the current instruction is processed. That's why it cannot decide which branch to take -- the required values are not written into the registers.
Other possible issues during pipelining
Pipelines can also suffer from problems related to timing variations and data hazards. Delays can occur due to timing variations among pipeline stages. This is because different instructions have different processing times. Data-related problems arise when multiple instructions are in partial execution and they all reference the same data, leading to incorrect results. A third problem is interrupts, which affect instruction execution by adding unwanted instructions into the instruction stream.
Security implications in pipelining
Pipelining tries to keep as much data as possible moving through the processor at once. Sometimes, data from different programs is in different stages of the pipeline at the same time. Attackers can try to abuse this to gain unauthorized data access. Some examples of this are the hardware vulnerabilities Spectre and Meltdown, which could enable attackers to abuse speculative execution to access data in the pipeline before it completes execution.
Downfall attacks read processor pipeline caches when they should not be able to. Intel refers to these types of attacks as microarchitectural data sampling, or MDS.
Superpipelining and superscalar pipelining
Superpipelining and superscalar pipelining are ways to increase processing speed and throughput.
Superpipelining means dividing the pipeline into shorter stages, which increases its speed. The instructions occur at the speed at which each stage is completed. For example, in a pipeline with seven stages, each stage takes about one-seventh of the amount of time required by an instruction in a nonpipelined processor or single-stage pipeline. In theory, it could be seven times faster than a pipeline with one stage and is definitely faster than a non-pipelined processor.
Superscalar pipelining means multiple pipelines work in parallel. This can be done by replicating the internal components of the processor, which enables it to launch multiple instructions in some or all of its pipeline stages.
CPU and GPU pipelining
Any processor type, including central processing units (CPUs) and graphics processing units (GPUs), can use instruction pipelining. Because of the differences in the design, the pipelines are tuned differently. Here are the key differences:
CPU pipelines
- Highly parallel in pipeline units and execution.
- General use for many function types.
- Deep, multistage pipelines.
- Support branch prediction.
GPU pipelines
- Highly parallel in number of processing units.
- Optimized for graphics and math.
- Shallow pipeline depth.
- Usually not designed for branch prediction.
Learn about parallel processing; explore how CPUs, GPUs and data processing units differ; and understand multicore processors. The term pipeline is also used in other contexts, such as a data pipeline, sales pipeline, talent pipeline and code pipeline.