Making sense of large data sets is not always easy, which is what inspired Aneesh Karve and his co-founder to start Quilt Data.
The San Francisco-based data discovery and search vendor emerged from stealth on Sept. 19 along with its technology platform that enables users to search for open data repositories across Amazon Web Services S3 storage. The core platform can also enable organizations to organize their own data and query it in what can be thought of as a new type of cloud data search engine.
Among the early users of Quilt Data's technology is Atlanta-based security company Bastille. Quilt has been useful in helping Bastille organize its data sets for model training, said Bob Baxley, chief engineer at Bastille.
"Before Quilt, we used a hodgepodge of S3 buckets and local NAS [network-attached storage] drive locations to store data, but we had issues with versioning and tracking data set changes," Baxley said. "By referencing data sets through Quilt versions and hashes, it is much easier to make immutable analysis notebooks that don't break as data sets evolve."
The promise of Quilt Data
Quilt Data co-founder and CTO Karve said he and co-founder and CEO Kevin Moore realized that there were several barriers to working with large data sets. Those barriers included both technical and cost-related problems.
"We asked ourselves, is there a radically different model for how anyone without coding skills can access data, and can access data at any scale, and that became Quilt," Karve said. "Our job as a company is to bring all the world's data into one place."
Quilt Data is able to handle structured, semistructured and unstructured data, by building on top of commodity block storage, Karve explained. Simply storing data however isn't the biggest challenge, he said.
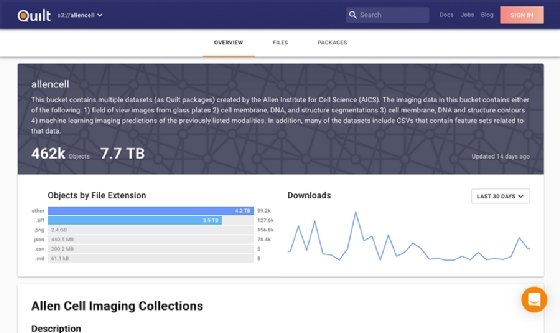
The biggest dilemma, particularly with large data sets stored in S3, is actually understanding what resides in a given storage bucket. What Quilt Data does is it provide context, shows how the files are broken down and enables users to visually make sense of what's available with an intuitive dashboard view.
Quilt Data open search dashboard
How Quilt Data works
Quilt Data's core premise is somewhat analogous to how a search engine works. Karve said that every time an object lands in a monitored S3 instance, the Quilt system gets a notification that triggers a serverless function to index the new data.
We build on top of Elasticsearch, but this is a level of user experience. Think of it like this -- Elasticsearch is an engine and we [Quilt Data] are the car.
Aneesh KarveCTO and co-founder, Quilt Data
"We do type inference based on the notifications we get from S3 and then we look at the file extensions, and depending on what the extensions are, we do something different," he said.
As part of its technology stack, Quilt Data uses Amazon's Elasticsearch Service. Quilt Data abstracts away the inherent complexity of Elasticsearch, with a zero configuration approach for users, Karve said.
"We build on top of Elasticsearch, but this is a level of user experience," he said. "Think of it like this -- Elasticsearch is an engine and we [Quilt Data] are the car."
Beyond what Elasticsearch enables, Karve emphasized that Quilt Data provides a higher-level solution for users, with actionable and visual results that help users make use of data.
Searching open cloud information with Quilt Data
Many public data repositories for scientific and other use cases are stored in AWS S3 cloud storage buckets. As part of its launch, Quilt Data also started a new free service called Open.quiltdata.com that provides a visual search tool to query and find information from the open cloud data repositories.
Quilt Data estimates that its system has already indexed some 3.7 petabytes of information that anyone can now search. Among the repositories that the Quilt Data indexes is Amazon's Registry of Open Data, which has its own basic query interface. The Quilt Data interface and query results make the data more useful, while also making it easier for users to find data in the first place, Karve said.
As a service, Quilt Data is now also available via the Amazon Marketplace for AWS users to run on their own cloud instances to identify and discover data. While Quilt Data as a service runs on AWS, Karve explained that the actual data can be hosted in another cloud or location by way of a feature called Quilt packages.
"What a Quilt package does is it allows you to create a pointer to data," Karve said. " So, if you have a multi-cloud environment, with data scattered all over the place, you can create a bunch of pointers that lets you use the data without moving the data."
"We are a company that helps other companies to become data-driven," Karve said.