Google grows cloud capabilities with BigLake data lakehouse
Google is continuing to build out its cloud data services with a new approach that will serve as a central cloud service for unifying data across different clouds and formats.
Google announced a series of new data capabilities Wednesday during the company's virtual Data Cloud Summit event.
Among the highlights from a data management perspective is the new BigLake platform, which is available today in preview. With BigLake, Google aims to bring together the best elements of data warehouse technology and data lakes in an approach that is commonly referred to as a data lakehouse. Google also announced a preview of a change data capture capability for the Spanner database, called Spanner change streams. At the event, Google also announced a new database migration program to help organizations with on-premises databases move to the Google Cloud.
Two things customers eschew the most are integrating a complex web of products and duplication of data. The higher the complexity of the architecture, the higher is the risk for data loss and the cost of governance.
Sanjeev MohanFounder, SanjMo
The data announcements made by Google are in sync with what users are asking for, according to Sanjeev Mohan, founder of SanjMo, an advisory firm. He said that in his view, BigLake taps into the strengths of data warehouses and data lakes while providing fine-grained access control. It uses open standards and provides the flexibility of multiple distributed processing engines. He added that he thinks BigLake has the potential to mitigate the challenges of architecture complexity and integration.
"Two things customers eschew the most are integrating a complex web of products and duplication of data," Mohan said. "The higher the complexity of the architecture, the higher is the risk for data loss and the cost of governance."
Why Google is building BigLake for data lakehouse capabilities
The term data lakehouse was first used by Databricks as a way to describe the combination of data warehouse and data lake capabilities. A data warehouse provides governance and structure, enabling data analytics and business intelligence, while a data lake offers low-cost storage that is easily scalable.
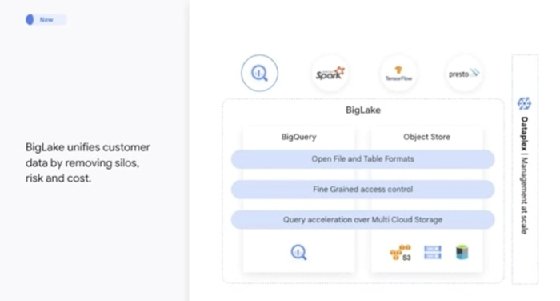
"BigLake is a data lake storage engine that enables organizations to leverage open source analytics engines and multi-cloud storage systems," said Gerrit Kazmaier, general manager and vice president of database, data analytics and business intelligence at Google Cloud.
Kazmaier noted that BigLake also allows companies to unify their current data warehouses and data lakes to analyze data without worrying about the underlying storage format or system.
Sudhir Hasbe, senior director of product management at Google Cloud, explained that BigLake is functionally a combination of BigQuery and object storage.
"We're taking the innovation from BigQuery and now extending it onto all the data that sits in different formats, as well as in data lake environments, whether it's on Google Cloud, with the Google Cloud Storage, whether it's on AWS or whether it's on [Microsoft] Azure," Hasbe said.
Google's BigLake combines BigQuery data warehouse capabilities with data lake and open source file and table formats.
Beyond just enabling support for data stored in different data lakes, BigLake will also support different data lake formats, including Apache Iceberg, an emerging open source data lake technology. BigLake will also integrate with Google's Dataplex to provide data governance.
As to why there is a need for BigLake and bringing together data warehouse and data lake capabilities, Hasbe said that data warehouses were traditionally thought about as being limited in the amount of data they could store, though they had strong capabilities on governance and querying. Data lakes, on the other hand, are great at storing large amounts of data, but lack the core governance and management capabilities.
"I think by bringing these worlds together, we take goodness of one side and apply it onto the other side," Hasbe said. "You can store all the data, and manage it and govern it really well."