
sdecoret - stock.adobe.com
How to use AI agents for infrastructure management
AI agents enable businesses to automate a variety of tasks, including infrastructure development. However, left unchecked, they can wreak havoc at the infrastructure layer.

Most organizations that have invested in AI tooling for their infrastructure teams aren't getting the return they were promised.
Gartner projected that global spending on AI-optimized IaaS will reach $37.5 billion in 2026. However, much of this spend will underdeliver. In a Gartner survey of 782 infrastructure and operations leaders, only 28% of AI use cases in infrastructure and operations fully meet ROI expectations, while 20% fail outright. This isn't the result of the models being inadequate but rather of an incomplete adoption strategy. Simply switching AI vendors or allocating more budget for costlier tools won't fix this.
To realize the benefits of AI agents automating infrastructure development, businesses must optimize their agents and provide them with business-specific data. Learn how to equip AI agents with the data they need to succeed and how to address the serious security and operational concerns this technology can pose at the infrastructure layer.
Why infrastructure AI agents are underperforming
Engineers across organizations are treating AI agents as a smarter search engine rather than properly embedding them into their platforms. They throw every incident, error and configuration issue at any random AI agent, expecting it to magically solve them. But in most cases, they end up with generic responses that, while correct in a vacuum, sound authoritative and seem helpful at a glance, are wrong for their environment and can break production.
AI agents can write infrastructure code, designing configurations and reasoning through complex problems. But they have a structural blind spot that no prompt can overcome: They're limited by their training data. Developers of more general-purpose models, such as Claude Code and GitHub Copilot, only train their models on publicly available data. By default, these agents don't know how a specific company operates. This includes the following:
- Naming conventions.
- System constraints.
- Internal service topology.
- Custom abstractions.
- Compliance policies.
- Architectural decisions.
- Post-mortems.
- Runbooks with operationally critical specifications.
Engineers can spend many hours fixing and tweaking these AI agents to ensure they integrate effectively with their systems, thereby defeating the expected productivity gains. This is the gap that CIOs and executives must close when evaluating AI tooling for their infrastructure teams. Selecting an AI agent is half the battle. Whether that agent can deliver depends on how organizations feed it institutional knowledge.
How to feed AI agents infrastructure knowledge
There are three approaches businesses can use to feed their AI agents information on their infrastructure.
1. Tribal knowledge
Knowledgeable engineers include business-specific instructions with prompts from memory. It could be as simple as: "Within this company, we use … " This only works because the engineer happens to remember the correct information. This method can become unreliable and unscalable when engineers get critical details wrong or when new team members lack necessary information.
2. Static documentation
Engineers can point AI to the location of documentation describing internal standards, likely in a Markdown file. They could also choose to copy its contents into every conversation with the model. However, this is a manual process, and given how slow teams can move, documentation can quickly become stale.
More critically, organizational knowledge isn't just a handful of documents. It consists of valuable knowledge scattered across git repos, Notion pages, Confluence pages, Slack threads and Zoom transcripts. Many of these sources overlap and contradict each other, so the stress of copying and pasting for every AI interaction is unsustainable.
3. A context-aware retrieval pipeline
Realistically, a document might cover different topics. It's inefficient to feed AI agents every detail when they only need information for the task at hand. Businesses should implement retrieval-augmented generation (RAG) with two pipelines: one for ingestion and the other for retrieval.
The ingestion pipeline captures company documentation from wherever it lives and breaks it down into data. Vector databases store, manage and index this data. The retrieval pipeline receives queries from the engineer and sends them to a Model Context Protocol server. An MCP server converts queries into embeddings and performs a semantic search against the vector database to retrieve relevant data. The LLM combines specific operational context with its general knowledge to generate a response.

A Kubernetes controller can automate document ingestion, keeping the pipeline running continuously and in sync with documentation and resources as they change. For most infrastructure teams, Kubernetes is already where the workload lives, so there's no need to introduce a separate orchestration layer.
Be aware that RAG adds some infrastructure complexities because there are several moving parts. Also, data quality is critical because poorly structured data can lead to unreliable results.
Data can get stale, too. If it remains in the vector database after someone updates the source documents, the RAG will retrieve conflicting information. Engineers should design the pipeline to remove old data rather than just append new data.
Prevent security risks from infrastructure AI agents
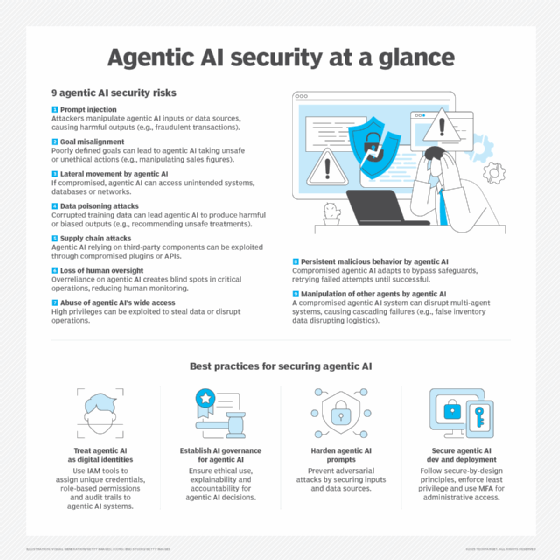
As AI agents get more embedded in infrastructure, they become a first-class security and compliance concern. The following are three key security areas businesses must address early:
- Permission and access controls. Agents aren't just passive tools; they constantly access sensitive company data. As a result, agents should be treated like employees with privileged human access, because the blast radius of a mistake is just as great. They should be able to modify infrastructure clusters, but they shouldn't be able to reach the cloud billing system. They should be able to open pull requests, but not merge their own work into production without human approval.
- Guardrails. These are essential safeguards to limit what an agent can and can't do. Agents should not complete high-stakes actions without a human in the loop. This could include actions like database deployment, data deletion and executing financial transactions.
- Observability. AI reasoning is nondeterministic. Inputs, outputs and LLM reasoning are unpredictable. Agents might call tools that engineers didn't expect. Asking agents the same questions can give different answers. For these reasons, teams must have observability over agents. Observability tools can be extended to AI agents, covering their behavior and providing a unified view across tool calls, model inputs and outputs. This should be treated as a non-negotiable requirement, not an afterthought.
The operational challenges of scaling AI agents for infrastructure
The two main operational challenges that engineers must prepare for when using AI agents for infrastructure development are context window restraints and cost.
Context window restraints
Eventually, agents will be working with a lot of data from various sources. If engineers keep piling this data into the AI agent's context window, it will soon fail. Broader context doesn't provide better results. Instead, it can lead to degraded performance, higher costs and inaccurate responses that make the system useless.
To prevent this, each interaction with the MCP server should start with a completely fresh context. The MCP gets the relevant information it needs to handle the specific task, not minding when that information was originally fetched or created.
Cost
Costs for agentic AI systems multiply quickly when running multiple systems simultaneously. A single query could trigger a multistep reasoning chain that calls multiple tools and burns through tokens. With model routing, engineers can route different types of requests to agents running different models.
Performing the routing in the model itself works better. The agent can decide what model to use for what task. For simpler tasks like summarizing and classifying data, engineers can use a cheap model and save more powerful models for heavy reasoning.
The blueprint for IT leaders
For IT leaders making or defending investments in agentic AI within infrastructure, the architecture that truly delivers on the promise should include the following:
- Multiple specialized agents. Instead of a single monolithic AI agent, use several, each scoped to a domain with distinct responsibilities.
- An MPC server. Businesses should integrate this server into tools that their engineers already use.
- A system context layer. This provides AI agents with company knowledge and operational guidance.
- A vector database. This stores data that AI agents break down from company resources and documentation.
- Agent memory. Memory enables agents to learn from their own experience.
- Guardrails. Prioritize guardrails for critical elements that affect production systems and include human-in-the-loop strategies.
- An observable setup. Leadership retains full visibility into the system's performance and related costs.
Wisdom Ekpotu is a DevOps engineer and technical writer focused on building infrastructure with cloud-native technologies.
Dig Deeper on AI infrastructure
-
![]()
Unstructured data is the bottleneck for agentic AI success
-
![]()
Latest MongoDB tools tackle top AI development hurdles
By: Eric Avidon
-
![]()
Shure: In an AI-code world, communication becomes a system dependency
By: Adrian Bridgwater
-
![]()
Hyland releases AI agent platform and vertical integrations
By: Don Fluckinger



