
Familiarize yourself with these 7 key SRE terms
Want to understand site reliability engineering? Check out this primer of SRE terminology that explains some of its fundamentals, from the job role to SLAs and issue resolution.

Site reliability engineering is a way to close the gap between software developers and IT operations teams; for teams already practicing DevOps, it is a way to improve workflows and resiliency. Or, as Google -- which established the term and concept of SRE -- says, it is when an organization treats IT operations as a software problem.
In doing so, an enterprise will see many benefits across its development pipeline. For example, SRE reduces manual effort through automation and leads to improved software quality, which in turn enhances a system's reliability, repeatability and flexibility. An SRE team also addresses and improves other aspects in the IT ecosystem, such as overall performance, availability, troubleshooting and monitoring.
However, before adopting an SRE approach, it's important to understand some key terms.
Site reliability engineer
A site reliability engineer bridges the gap between developers and IT operations staff to create and ensure the scalability, stability and predictability of an organization's systems. To do so, SREs automate rote tasks, manage production changes and determine emergency responses, among other tasks.
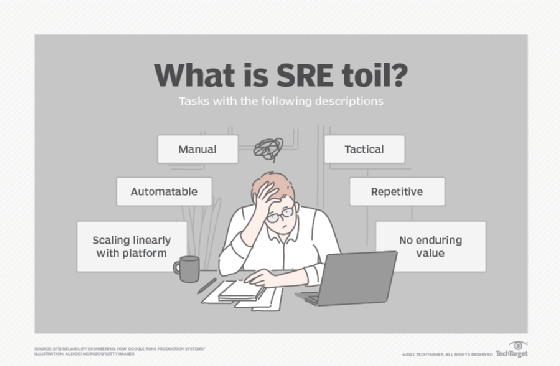
Toil
Tasks that keep the IT platform running are, of course, essential, but completing them manually is not. The reduction of these tasks, also known as toil, is one of SRE's primary goals. Examples of tasks that are considered toil include automatable patching and updates.
Error budget
One hundred percent availability is an unrealistic standard. And because no service is perfect, users must set a performance standard internally, externally or both. This performance gap, or amount of acceptable downtime, is called an error budget. It is the site reliability engineer's responsibility to keep performance within this frame through completing administration tasks and tracking key metrics.
Service-level agreement (SLA)
This is the contract between a provider and the customer that spells out the expectations for both parties. For example, SLAs set standards for services, such as availability level, so that customers understand the provider's liability for outages or performance issues. This means that if an issue falls outside of the severity levels or circumstances defined in the SLA, the provider is not responsible for it, but it falls within the contract, there is often a financial penalty. This ensures accountability by the provider and the user.

Service-level objective (SLO)
Rather than a distinct metric, the SLO is part of the SLA; SLOs track key performance indicators the customer should expect from the vendor -- and the dictated penalties if expectations are not met. SLOs define a range of acceptable performance, starting with key metrics such as disaster recovery time and application availability. An SRE must align these performance goals set by an SLO with the organization's error budget to ensure performance standards. This involves setting alerts and monitoring the value of the SLOs.
Service-level indicator (SLI)
Another typical component of an SLA, SLIs are a direct measurement of a service's behavior that indicates the level of performance the customer receives. These are set by both the provider and customer. SLIs are the basis of SLOs. Examples of SLIs include latency, error rate and availability. However, there needs to be a fine balance of chosen metrics to ensure that those critical to the specific environment or user base are not overlooked.
IT incident post-mortem
The upside to IT incidents is the opportunity to learn and improve. An incident post-mortem evaluates the root cause of an issue and its effects, reveals key lessons and helps IT staff establish a plan to prevent a recurrence. SREs are responsible for conducting these post-mortems and sharing the results with senior staff, such as C-suite leaders, engineers and architects. Successful post-mortems remove blame to create an environment where staff feel comfortable speaking honestly about incidents, which focuses the discussion on why the issue occurred.







