
Getty Images/iStockphoto
The data team-IT operations divide delays data delivery
Extended delays in the data delivery process aren't just inconvenient; they're a hindrance to business success that data teams and IT operations must solve together.

Modern IT runs on data -- and there's a lot of it to manage.
In fact, there's so much data to manipulate and analyze that organizations have created a specific team of data engineers and data scientists. Unfortunately, even in DevOps environments, that data team often operates independently -- a separation that can harm the entire business, not just the IT department.
This issue stretches beyond business intelligence: It's a data team issue and, by extension, an IT operations problem. This collaboration, called DataOps, brings together data engineers, data scientists and IT operations teams, who inevitably form the bridge between users' requests and the data team's fulfillment.
We met with Mike Leone, analyst at Enterprise Strategy Group with expertise in data platforms, data analytics and AI and author of ESG's "Data Initiatives Spending Trends for 2022" study, to discuss data, DataOps and the challenges of getting data to those who need it really, really fast.
Author's note: This interview has been edited for clarity and brevity.
You've got the data point, '52% of organizations say it takes at least a day for end users to have access to a newly requested data set.' You have said it's a business intelligence issue, but this is also effectively a deployment situation, right?
Mike Leone: A BI [business intelligence] platform serves as an entry point for business analysts and folks doing some quick data analysis.
And there are systems that are tightly integrated to get the data from where it's generated, or where it's stored, to that platform. There are technology solutions, services that need to be stitched together to have a high-performing data pipeline get to where it needs to be.
On top of that, you need components of governance and security to ensure trust -- to make sure the right people are accessing the data they're supposed to -- and not the other way around. There are different teams involved. There's data engineers, there are application development teams, and, interestingly enough, the persona that an end user goes to by default -- if they want to add a new data set -- is actually IT.
So, 58% of respondents to the survey said, 'If I need a new data set, the IT team is the team that I will reach out to for that support.' You hear so much about data engineers and data scientists, but IT is being asked to extend their skills [to support] BI platforms -- which are not normally under their purview -- but also to support all these end users that crave data.
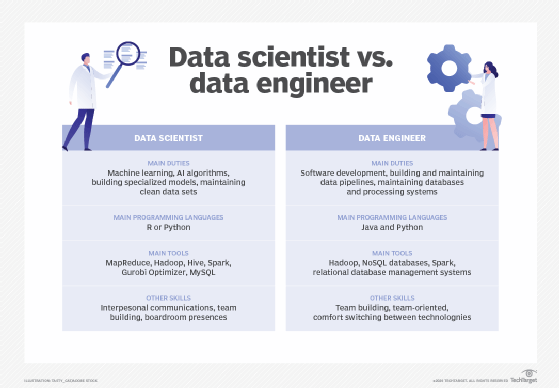
Do you separate data science teams from the IT teams?
Leone: For the most part, data science teams and IT teams are notoriously independent. And what we find is that the more those two teams collaborate from the start of projects, where they're discussing business objectives and ideas and working together, it's more beneficial to the business. …
But the good news is that organizations are starting to better integrate those two teams.
Do you think DataOps is more relevant or, perhaps, accurate pairing for connecting IT and data science teams than you would say DevOps is?
Leone: Traditionally, you hear 'DevOps:' It's IT teams, it's developers -- they're working together [to build] these applications in an Agile way.
So, DataOps. It's kind of a misconception that DataOps [is] just DevOps for data. [DataOps is] an entry point for data engineers -- not even the data science teams. These are data engineers that are doing data integration and ETL [extract, transfer and load] processes and working with IT to ensure that data and analytics capabilities are available to the business. There are components of software development and CI/CD, but often that is associated with the codes and scripts that those data engineering teams use to make sure that data is available to the right folks or the right tools.
Does the data team send its accumulated data to IT operations to perform log management and various automated analysis-type activity?
Leone: Today, log management vendors -- the Splunks of the world -- are tying themselves to DataOps because it's operational data and comes directly from the infrastructure components within IT.
It's predictable in the sense that, [for example], CPU utilization is a defined number that can only be from zero to 100%. Data engineers have not gotten involved with moving that kind of data and making it available for IT.
So, to clarify: The data team does all of its own collection and analysis, and then that information goes to the end users -- but the end users contact IT directly for data, who then transfer those requests to the DataOps team.
Leone: It's a train wreck, truly. There are many personas involved. And that's a big reason why DataOps is on the rise again, in my opinion.
The goal is to best empower all of the personas as effectively as possible. Traditionally, the data teams [give IT operations] some tools to expose this data to [end users]. But it's yet a new persona that controls the governance of [access to new data sets].
This persona is called a data steward. A data steward lives across IT and data teams. And that gets interesting -- and confusing. But it's almost forcing IT to educate themselves on data-centric processes and integration points. They'll continue to get these questions [from end users] to a point where they don't have a choice but to answer them. Data teams -- like the data engineers -- are burdened with so much work because of the dynamic toolchains that make up a data pipeline.
It's a big reason why organizations invest in things like embedded analytics, which simplify the way end users access data in a controlled environment. That puts pressure on the developers, but the developers are responsible for building these applications that have self-service and have the guardrails that the end users need to do what they need to do -- and do it effectively.
If the response to this complication is to invest in embedded analysis capabilities in tools and platforms, will that force companies to then transition to DataOps where they do merge those two groups?
Leone: I don't think it would force merging. It would force collaboration, and that should be happening anyway.
There's been such a big focus from vendors on collaboration -- not just collaboration from the end users -- it's collaboration with all the different teams behind the scenes, looking to deliver data [more effectively] at the right time to the right tool or the right person. The more that organizations collaborate across these teams … early on, the more effective they are at succeeding with DataOps strategies.
But it's more than that. You can go to metrics on the business side, like revenue per employee [or] the ability to predictively analyze where an organization should enter a new market or create a new service. All of those components are tied to better collaboration.
If it takes at least a day for more than half of end users to gain access to a requested data set, how can those organizations reduce that time?
Leone: There are tools that provide automation and [better data governance]. Vendors will provide tools that infuse AI and machine learning to simplify the process. There are components of self-service: If I want a new data set, instead of reaching out to IT, I can just click three buttons, and then I magically have access to a data set -- if it's available. And I know that it's trusted [because] I know where it came from. There are more and more tools trying to deliver that type of experience. …
Look for ways to present data faster to end users when they ask [for it]. And think about it from an end-user standpoint. I know it would annoy me -- I'm assuming it would annoy you -- [if] you're an hour into some kind of experiment or analysis, and then, suddenly, you need more data. Now, I have to wait more than a day. It takes a long time to get back into the right headspace that you were just in while you were analyzing [that data set].
Is there anything else notable about this particular topic that you would like to call out?
Leone: There's a component of developer and data team interaction that is really important.
One of the components that we saw was that companies considered 'data leaders' are more likely to have their data teams and developers interact more frequently when it comes to supplying the business with access to data and analytics -- to the tune of more than one in four organizations. They have developer and data team interaction on a daily basis.
Would you consider the data teams working more closely with developer teams to produce such systems that help users get what they need -- when they want it -- another form of self-service?
Leone: That's exactly it. We expect the self-service enablement market -- which is tied to data and analytics -- to grow by 85% over this next year because of situations like how long it takes to access data. It shouldn't have to go through four different teams; it should be faster than that.
This is where we want to empower end users to leverage data. And to do that -- and to give them the confidence -- [enable] self-service so overburdened data teams, and overburdened IT teams, aren't crushed with constant support tickets.







