DevOps incident management turns sys admins into SREs
DevOps practices begin with collaboration on application releases, but it's not until something goes wrong with those apps in production that true transformation takes place.
App delivery collaboration under DevOps gets a lot of lip service, but IT teams truly mature only when developers take responsibility for their code in production.
Enterprises where developers troubleshoot their own code have not only profoundly improved DevOps incident management success rates and IT management decisions, but have shifted the fundamental function of IT ops pros in the organization. On-call developers free up operations pros to play a more strategic role in the design and automation of the IT infrastructure -- a role dubbed site reliability engineer (SRE).
"Code problems are understood better and get fixed more quickly when developers are on call," said Ernest Mueller, director of engineering operations at AlienVault, an IT security firm headquartered in San Mateo, Calif. "The operations team can also provide better build and monitoring systems instead of being in interrupt mode the whole time."
Some developers and IT ops pros resist these shifts at first. At AlienVault, developers wriggled out of their on-call responsibilities over time, and IT ops pros struggled to see developers as customers who they must accommodate, Mueller said.
"Some ops folks have a more adversarial view of the universe, and the SRE role is about getting them to understand, 'You may like the tool better working a certain way, but that's not relevant,'" Mueller said. "What's relevant is what the customer wants to do with it."
While role changes can be uncomfortable, AlienVault's IT teams saw firsthand what happens without thorough DevOps incident management. As developers stopped responding to code issues in production, problems sometimes took up to six months to resolve. Now, developers on call can escalate infrastructure-related problems to operations engineers, but the software engineers who wrote each application are the first ones paged to troubleshoot issues, which leads to quicker resolutions.
"In a mature product, the vast majority of the time, production problems actually are app problems," Mueller said. "The server just doesn't crash that much."
DevOps incident management boosts app quality
When developers own their code, there's less finger-pointing between developers and operations during IT incident management, which leads to better app performance overall, said Thomas Davis, director of security at ServiceMaster, a home services company based in Memphis, Tenn.
"It's important for developers to be closer to production, because it allows them to have skin in the game," Davis said. "All of a sudden, if you're answering phone calls in the middle of the night, you're going to think differently next time."
ServiceMaster has rotated some team members through various IT roles to strengthen their understanding of the applications they produce and the infrastructures where those applications run. This means IT ops teams have to understand app development, too.
If you're an ops person, know how development works ... As we move into the cloud and software-defined networking, infrastructure teams shouldn't be on an island.
Thomas Davisdirector of security, ServiceMaster
"If you're an ops person, know how development works, because we're going to ask you to start doing some of that stuff," Davis said. "As we move into the cloud and software-defined networking, infrastructure teams shouldn't be on an island and not understand the software development lifecycle."
This big-picture view sharpens the entire company's focus on the customer's experience of its applications. IT ops pros learn how to think more strategically to make infrastructure reliable when they aren't constantly putting out fires in production, and developers learn how to write their applications to be resilient when infrastructure outages do occur.
"Now that the engineers building the apps are the ones responding to incidents, even if the services the app depends on are down, they have a better sense of what it does to their customer," said Andy Domeier, director of technology operations at SPS Commerce, a communications network for supply chain and logistics businesses in Minneapolis. "In that model, your software engineers will at least give the user a better experience."
DevOps incident management improves automation
As the IT operations role in DevOps incident management diminishes, SREs focus on the maintenance of a standardized, automated infrastructure optimized to smoothly deploy and manage applications.
In some cases, this means SREs must pick their battles and hand tricky bits of infrastructure over to service providers. At Mux Inc., a video streaming startup in San Francisco that serves major media customers such as CBS, one full-time SRE and one part-time SRE manage some 200 Kubernetes cluster nodes in multiple AWS regions globally. With the SREs' hands full, ingress controllers that govern those clusters' interactions with the open internet are outsourced to a SaaS provider, Backplane, so developers don't wait for ops to set up load balancers when they want to test new apps.
"Traditionally, we would have to deal with setting up load balancers and configuring ports for routing traffic internally," said Adam Brown, co-founder at Mux. "With Backplane, you just turn on the agent, and it means that we have spent less time configuring, particularly for testing new services and quick development."
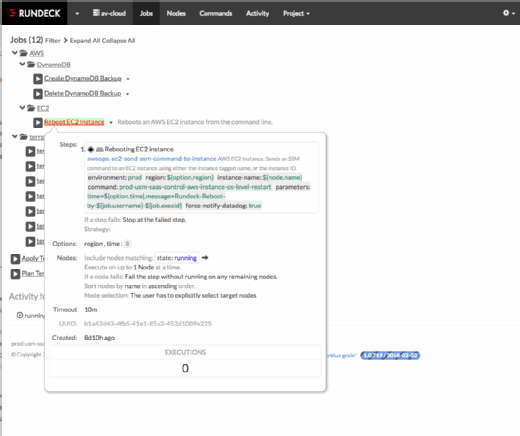
At larger organizations, SRE teams use open source tools to create guardrails that protect the infrastructure as developers gain troubleshooting experience. AlienVault uses the open source version of Rundeck's runbook automation tools, which provide fine-grained, role-based access control. These limitations give developers the freedom to do common infrastructure management tasks, but restrict riskier operations to more experienced team members.
Next, Mueller's team at AlienVault will integrate alerts from Datadog monitoring and VictorOps alert routing tools with runbook information, to provide context for developers to respond to incidents. In the process, the organization will convert vast swaths of tribal knowledge accumulated by ops pros into more accessible documentation for all team members.
"You go to college to become a developer, but ops comes from the streets," Mueller said. "But we're trying to make runbooks more developer-friendly, with fewer assumptions built into them."