3 lessons from the 2021 Facebook outage for network pros
Even in hyperscalers like Facebook, one errant finger can take down a network. The takeaway, experts said, is to expect and plan for the worst and put those plans to the test.
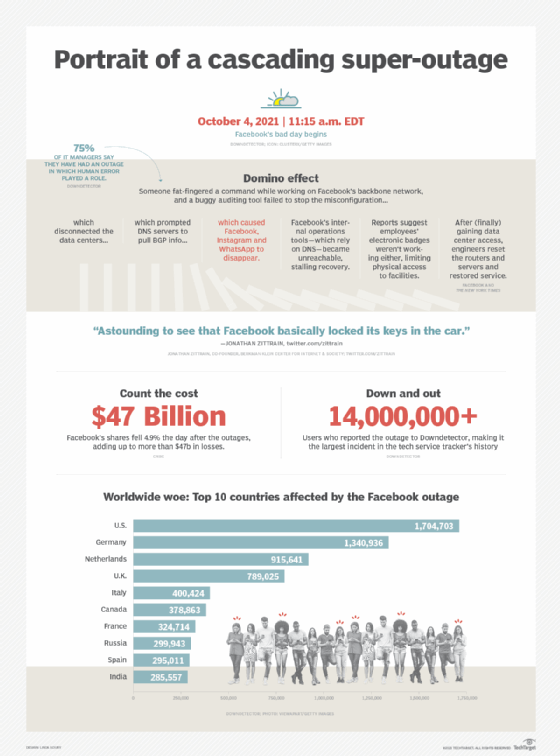
Border Gateway Protocol, or BGP, was an early suspect in Facebook's recent global outage, one of the largest and worst in the social media giant's history.
On Oct. 4, 2021, Facebook -- now Meta -- and its subsidiaries, including Messenger, Instagram and WhatsApp, disappeared from the internet and remained unavailable for roughly six hours. Public speculation quickly arose -- much of it on Twitter, where social media users flocked in Facebook's absence -- that the outage might have stemmed from a BGP error.
With Facebook, Instagram and WhatsApp all unavailable, users flocked to Twitter.
But, according to Facebook, BGP and DNS issues were just symptoms of the actual problem: a misconfiguration that disconnected the company's backbone routers. In other words, to err is human.
"The root cause of this was fingers," said Terry Slattery, principal architect at consulting firm NetCraftsmen.
How did the 2021 Facebook outage happen?
During routine maintenance on the backbone network, an engineer trying to assess capacity fat-fingered a command and triggered a cascade of technical problems, according to Facebook Vice President of Engineering and Infrastructure Santosh Janardhan. He explained in a blog post that an internal auditing tool should have stopped the misconfiguration, but a software bug caused the control to fail. The faulty command executed across the backbone routers and disconnected Facebook's data centers.
That, in turn, triggered the secondary DNS and BGP problems. When the company's DNS servers couldn't communicate with the data centers, they automatically withdrew their BGP route advertisements, essentially removing themselves from the virtual map of the internet. Suddenly, it was as if Facebook, Instagram and WhatsApp didn't exist.
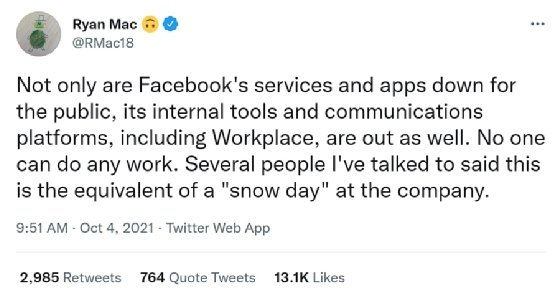
To make matters worse, Facebook's internal operations tools rely on the company's own infrastructure and DNS to function. Employees, therefore, couldn't access the systems they typically use to work and communicate, and the networking staff couldn't investigate or resolve the outage remotely via their usual methods.
The New York Times' Ryan Mac reported that Facebook's internal tools were also unavailable during the outage on Oct. 4, 2021.
Andrew Lerner, analyst at Gartner, compared this unfortunate sequence of events to sawing off a tree branch while standing on it. Jonathan Zittrain, professor at the Harvard John A. Paulson School of Engineering and Applied Sciences, tweeted that Facebook "basically locked its keys in the car."
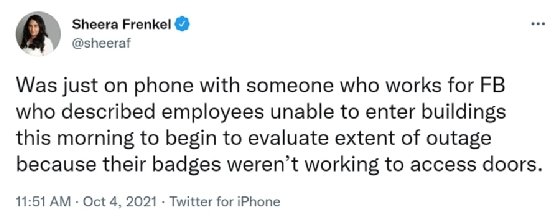
Engineers ultimately had to get inside Facebook's data centers to manually debug and reset routers and servers. But an employee told Sheera Frenkel, a reporter at The New York Times, that workers couldn't gain physical access to company facilities because the electronic badge system failed. Even under normal circumstances, Facebook's data centers and network hardware are heavily fortified, according to Janardhan. So, getting the right people on-site took time.
A source told The New York Times' Sheera Frenkel that the 2021 outage locked Facebook employees out of company facilities.
But first, network hygiene
Lerner said he has received several calls from network leaders asking what they can learn from the 2021 Facebook outage. But he cautioned that, before worrying about this kind of cascading super-outage, companies should first make sure they are practicing basic network hygiene. "I'll be honest: Most organizations are not doing the foundational stuff," Lerner said.
He said those foundational tasks should include the following:
Once they've covered the fundamentals, organizations can then turn their attention to headline-grabbing cautionary tales, he said.
What can enterprises learn from the 2021 Facebook outage?
According to experts, network pros can take the following lessons from the Facebook outage.
1. Expect the worst
Creative pessimism may be a virtue when it comes to averting super-outages. Lerner suggested IT pros look for possible single points of failure within their networks and imagine how they might trigger cascading outages. For example, if an organization relies on a particular security information and event management platform for network troubleshooting, it should consider what would happen if that resource became unavailable. Other common points of failure include authentication and, as in the case of the Facebook outage, DNS.
If you can't handle an outage that you've orchestrated yourself, then it's going to be hard for you to handle a real emergency when it happens.
Terry SlatteryNetCraftsmen
"The Facebook scenario suggests companies should be looking toward true disaster recovery -- what happens if our infrastructure isn't usable?" NetCraftsmen's Slattery said.
He added that a viable contingency plan might hinge on out-of-band network access -- independent of potential single points of failure, such as DNS -- that engineers can operate using mostly manual processes. (Facebook said its own out-of-band network failed during the October 2021 outage but didn't explain why.)
3. Put those plans to the test
Slattery suggested taking disaster planning a step beyond simulation exercises with active failure testing. Similar to Netflix's Chaos Monkey or cybersecurity's penetration testing, active failure testing involves deliberately introducing a real -- albeit contained and controlled -- failure in the network. That might mean taking out a link or a router to uncover architectural vulnerabilities and test recovery processes.
But most organizations instinctively dislike and avoid failure testing, Slattery added. Such exercises require extensive upfront preparation, and network teams often worry the drills could result in real-world outages. But therein lies their greatest value, according to Slattery. "If you can't handle an outage that you've orchestrated yourself, then it's going to be hard for you to handle a real emergency when it happens," he said.
Lerner, who has himself previously called for a networking version of Netflix's Chaos Monkey, said enterprises typically aim for long periods of high availability in which nothing breaks. He said he considers that strategy misguided, however, as those periods often mask inherent instability and fragility. When a problem does finally occur, it then tends to create a domino effect.
"Most of the really nasty outages in the enterprise are these cascading outages," Lerner said.