Many network pros write their own automation scripts. These best practices help teams implement coding and tool set standardization, proper change management and immutability.
Automation is crucial to managing networks at speed and at scale, securely and reliably. Most network teams write some of the automation scripts they use to provision and manage resources on the network.
install software and firmware updates on physical devices;
push out a device configuration;
deploy changes to configurations; and
pull information from devices and plug it into some file or database.
Network practitioners write their own scripts to save money on management tools or to make up for shortcomings in tools they have. For example, they may have comprehensive automation via a management console for their Wi-Fi infrastructure, but not their wired; or for equipment from one network vendor but not others.
Sometimes teams use scripts to direct the efforts of a management tool via its API instead of through a GUI. They might even script to knit together management tools that control different segments of the network.
The goal is to automate time-consuming or error-prone tasks. Automating these operations reduces errors that affect services or security. Reducing errors adds the benefit of saving administrator time, specifically the time that would have gone to troubleshooting and error remediation.
In some data centers and cloud environments, this kind of scripted or programmatic control of the network is included in a DevOps culture. Network teams outside those environments are less likely to be "doing DevOps" and aren't even close to being full-time developers. Even if they pursue an Agile methodology, that doesn't dictate specific best practices for their coding efforts the way DevOps cultures do.
So, network teams that are on their own can follow some best practices to ensure their efforts support reliability, security and maintainability over time.
These best practices can help network teams streamline their DIY network automation initiatives.
Develop for people -- aka sharing is caring
One key insight network staff should internalize when writing automation scripts is, "This script isn't just for me." Script authors that write with the expectation of using it more than once should assume someone else could or will use it someday. That person could be a co-worker, successor or the original author -- a sufficient span of time can blur out details and insights that were top-of-mind when the author wrote the code.
When authors write code without others in mind, it can be difficult and time-consuming for network admins to understand the code's functions, behavior, requirements, expected context and consequences.
Staff can avoid the problem of write-only code by implementing the following best practices:
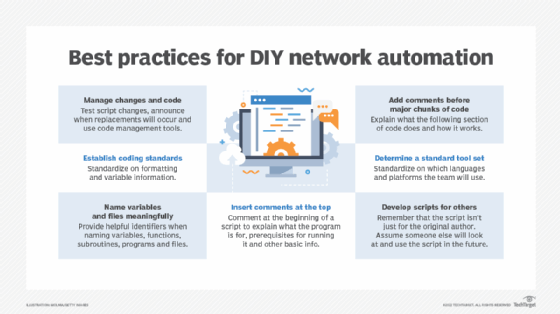
Establish a small set of coding standards. For example, teams can decide that any given script will follow snake_format or CamelFormat for all object names. It doesn't matter which format they use; what matters is consistency within a given program. Some see a benefit in going a step further and encoding into variable names information about the variable itself -- e.g., whether it's an integer or a string -- typically by adding a prefix or suffix, such as str_username for a string holding a username.
Name variables, functions, subroutines, programs and files meaningfully. If an author means for a variable to identify a network appliance, calling it appliance_id is far more useful to other people than naming it foo.
Insert comments at the top of a script explaining overall facts. These comments explain information about what the program is for, any prerequisites for running it and the basic process it uses for solving the problem in hand.
Insert comments before major sections of a long chunk of code. These comments explain what the next section of code is going to do and how it does so, at a high level.
One key insight network staff should internalize when writing automation scripts is, 'This script isn't just for me.'
It's also helpful for teams to establish a standard tool set. When tool choice is a free-for-all, a team might end up with every admin using a different language or platform and no mutual understanding.
One size won't fit all, however. Everyone everywhere doesn't need to write all their code in Python, or anything like that. Instead, teams should define a small and controlled set of languages or platforms they can use for the ad hoc automation they write. This strategy makes it possible for everyone on the team to have at least basic competency with all the tools in use. In turn, they'll be able to use, extend, update or fix anybody else's work. Teams can drop languages or platforms in favor of better ones, as needed.
Manage code and changes carefully
In most organizations, when IT rolls out a new version of any major application or OS, it follows a change management process. Teams review the proposed change. Does IT have a plan for making the change? Does it have a plan for reverting to the status quo ante if the change causes a problem? Has the team tested the change well? Does it have a plan to inform users who will be affected? Once teams approve the change, they schedule it for deployment, often choosing a change window that limits the adverse effects if something goes wrong and minimizes the inconvenience to users, however the change goes.
Network automation is critical IT software. So, when network teams want to modify a program currently in use, they should use a similar, streamlined process. At a minimum, the network change management process should ensure teams do the following:
test changes to a script before deploying a new version in production; and
announce in advance when they will replace the old version with the new.
The term new version brings up the question of code management. Network teams should know what the current version of any given script is, where it can be found, who last updated it and when. All that information comprises the minimum level of code management. Network teams can use code management tools to enforce version control -- via check-in and check-out -- and track authors.
Don't forget about immutability
Finally, network teams should consider a common approach among DevOps teams that practice infrastructure as code management in their environments: immutability. With immutability, a value or configuration can't be modified, only replaced or removed.
For example, once network teams deploy a virtual appliance, they should treat its configuration as immutable -- not to be modified. If the virtual appliance requires a configuration change, the network team pushes out a new virtual appliance with a configuration that includes the change, and they deprovision the older, incorrectly configured instance. Or, if the team makes configuration changes to a physical device, it pushes out a complete configuration that includes the change, rather than just pushing the change itself.
The goal of immutable configurations is to minimize or eliminate configuration drift in the environment. Pushing complete configurations or images wipes out any unsanctioned changes on the device.
Immutability also addresses a common problem in which one push to a device (incorporating change A) fails but a later push (to implement change B) succeeds. If the second push includes only change B, the device is still improperly configured because it lacks change A. However, if the second push is a complete configuration, which includes both A and B, the second push brings the device into compliance again. Also, notably, if change B depends on change A, pushing a complete configuration means change B won't automatically fail for any device on which change A failed.
Network teams use a lot of ad hoc automation and will likely use more each year. Using those automation scripts better can help make their efforts more successful and ease their work stress.