Hands-on guide to S3 bucket penetration testing
Attention AWS pen testers: The trick to understanding the indicators of AWS S3 bucket vulnerabilities is setting up an insecure bucket. Learn how in this actionable guide.
Cloud environment misconfigurations and subsequent data breaches keep landing AWS Simple Storage Service in the headlines.
In their book, Hands-On AWS Penetration Testing with Kali Linux, co-authors Benjamin Caudill and Karl Gilbert provide actionable steps for effective penetration testing in major AWS services, including S3, Lambda and CloudFormation.
S3 has enjoyed enormous popularity since its launch in 2006 due to a variety of benefits, including integration, scalability and security features. "Think of it as a one-stop shop for storage," Caudill said.
But Amazon S3 security is what you make of it. Misconfigurations happen, and they keep landing organizations in the headlines due to data leaks and breaches that occur as a result. "An S3 bucket-related issue is just overwhelmingly sort of the primary vulnerability that comes to mind when people think of AWS and certainly unauthenticated attacks," Caudill said.
The following excerpt from Chapter 7 of Hands-On AWS Penetration Testing with Kali Linux published by Packt Publishing serves as a virtual lab to identify Amazon S3 bucket vulnerabilities by first setting up an insecure bucket.
Hands-On AWS Penetration Testing with Kali Linux
Download a PDF of Chapter 7.
Read a Q&A with co-author Benjamin Caudill.
S3 permissions and the access API
S3 buckets have two permission systems. The first is access control policies (ACPs), which are primarily used by the web UI. This is a simplified permission system that provides a layer of abstraction for the other permission system. Alternatively, we have IAM access policies, which are JSON objects that give you a granular view of permissions.
Permissions apply either to a bucket or an object. Bucket permissions are like the master key; in order to provide someone access to an object, you need to provide them access to a bucket first, and then the individual objects themselves.
 Click here to learn more about
Click here to learn more about
this book.
S3 bucket objects can be accessed from the WebGUI, as we saw earlier. Otherwise, they can be accessed from the AWS command-line interface (CLI) using the aws s3 cmdlet. You can use it to upload, download, or delete bucket objects.
In order to upload and download objects using the AWS CLI, we can take the following approach:
- Start by installing awscli:
sudo apt install awscli
- Configure awscli with the new user credential. For this, we will need the access2.key ID and the secret access key. To get these, follow this procedure:
- Log in to your AWS Management Console
- Click on your username at the top-right of the page
- Click on the Security Credentials link from the drop-down menu
- Find the Access Credentials section, and copy the latest access key ID
- Click on the Show link in the same row, and copy the secret access key
- Once you have acquired these, issue the following command:
aws configure
Enter your access key ID and secret access key. Remember to not make this public to ensure your accounts are safe. You may leave your default region and output format set to none.
- Once your account has been set up, it is very easy to access the contents of the S3 bucket:
aws s3 ls s3://kirit-bucket
kirit-bucket in the preceding code will be replaced by your bucket name.
- If you want to traverse directories inside a bucket, simply put / followed by the directory named listed from the preceding output, for example, if we have a folder named new:
aws s3 ls s3://kirit-bucket/new
- To upload a file to the S3 bucket, issue the cp cmdlet, followed by the filename and the destination bucket with full file path:
aws s3 cp abc.txt s3://kirit-bucket/new/abc.txt
- To delete a file on the S3 bucket, issue the rm cmdlet followed by the full file path:
aws s3 rm s3://kirit-bucket/new/abc.txt
ACPs/ACLs
The idea of access control lists (ACLs) is very similar to the firewall rules that can be used to allow access to an S3 bucket. Each S3 bucket has an ACL attached to it. These ACLs can be configured to provide an AWS account or group access to an S3 bucket.
There are four main types of ACLs:
- read: An authenticated user with read permissions will be able to view filenames, size, and the last modified information of an object within a bucket. They may also download any object that they have access to.
- write: An authenticated user has the permission to read as well as delete objects. A user may also be able to delete objects they don't have permissions to; additionally, they can upload new objects.
- read-acp: An authenticated user can view the ACLs of any bucket or object they have access to.
- write-acp: An authenticated user can modify the ACL of any bucket or object they have access to.
An object can only have a maximum of 20 policies in a combination of the preceding four types for a specific grantee. A grantee is referred to any individual AWS account (that is, email address) or a predefined group. IAM accounts cannot be considered as a grantee.
Bucket policies
Each S3 bucket has bucket policies attached to it that can be applied to both the bucket and the objects inside it. In case of multiple buckets, the policies can be easily replicated. Policies can be applied to individual folders by specifying a resource such as "data/*". This will apply the policy to each object in a folder.
You can add a policy to your S3 bucket using the web UI. The action is under the Permissions tab of the bucket Properties page:
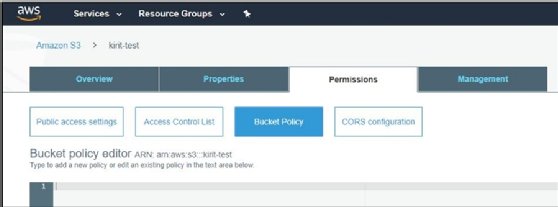
Next, we will see how bucket access can be configured for IAM users.
IAM user policies
In order to provide S3 access to individual IAM accounts, we can use IAM user policies. They are a very easy way to provide restricted access to any IAM account.
IAM user policies come in handy when an ACL permission must be applied to one specific IAM account. If you are wondering whether to use IAM or a bucket policy, a simple rule of thumb is to determine whether the permissions are for specific users across a number of buckets, or if you have multiple users, each needing their own set of permissions. In such a scenario, IAM policies are much better suited than bucket policies, as bucket policies are limited to only 20 KB.
Access policies
Access policies are fine-grained permissions that describe permissions granted to any user on an object or bucket. They are described in JSON format and can be divided into three main sections: "Statement", "Action", and "Resource".
Here is an example of a bucket policy in JSON:
{
"Version": "2008-02-27",
"Statement": [
{
"Sid": "Statement",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::Account-ID:user/kirit"
},
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::kirit-bucket"
]
}
]
}
The JSON object has three main parts. First, within the "Statement" section, we can see there are two points to note – "Effect" : "Allow", and the "Principal" section containing "AWS" : "arn:aws:iam::Account-ID:user/kirit". This essentially means that the "kirit" user account is being granted permissions to an object.
Second, is the "Action" section, which describes what permissions are being allowed to the user. We can see the user is allowed to list objects inside the "s3:ListBucket" bucket, and download objects from the "s3:GetObject" bucket.
Finally, the Resource part describes on which resource the permissions are being granted. To put it all together, the policy summarizes to allow the kirit user account to GetBucketLocation, ListBucket, and GetObject under the bucket named kirit-bucket.
Creating a vulnerable S3 bucket
For our next exercise, we will try to read and write from a vulnerable S3 bucket that has been made public to the entire world. In order to do this, we will set up an S3 bucket and intentionally make it vulnerable my making it publicly readable and writeable.
We will start by heading over to the S3 home page (https://s3.console.aws.amazon.com/s3/) and creating a vulnerable bucket that is publicly accessible:
- Create a new S3 bucket.
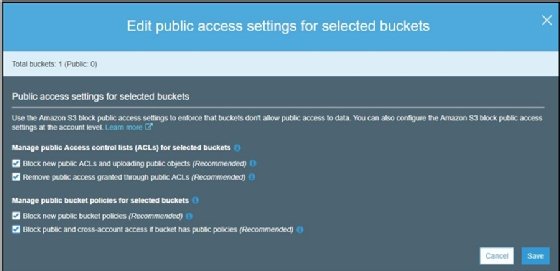
- Once the bucket has been created, select the bucket and click on Edit public access settings for selected buckets:
![Screenshot of AWS S3]()
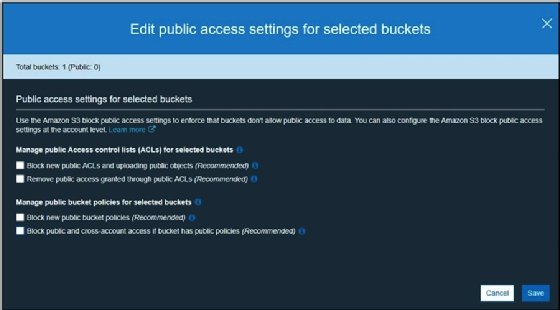
- Unselect all the checkboxes and click on Save. This is done in order to remove any access restrictions that have been enforced on a bucket:
![Screenshot of AWS S3]()
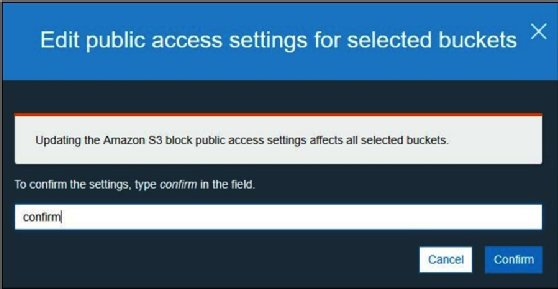
- AWS will ask you to confirm the changes; type confirm into the field and click on Confirm:
![Screenshot of confirmation of changes to AWS S3]()
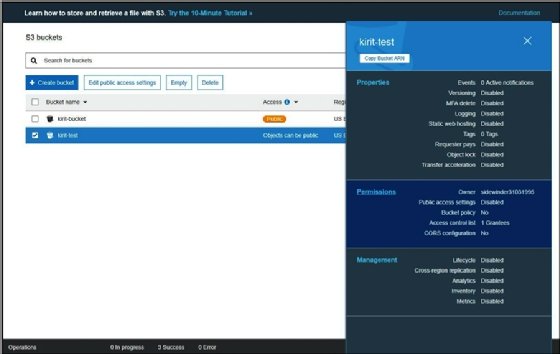
- Click on the bucket, and then on the side panel, click on the Permissions tab:
![Screenshot of AWS S3 bucket Permissions tab]()
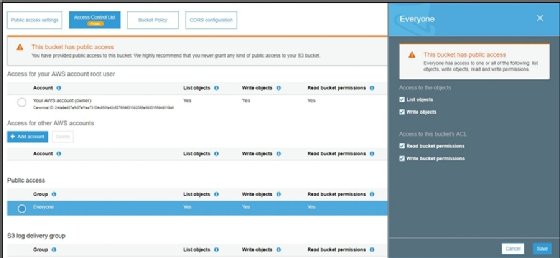
- Go to Access Control List, and under Public Access, click on Everyone. A side panel will open; enable all the checkboxes. This tells AWS to allow public access to the bucket; this is what makes the bucket vulnerable:
![Screenshot of AWS S3]()
- Click on Save and the bucket will be made public.
Now that we have our vulnerable bucket, we can upload some objects to it and make them public; for example, we upload a small text file to the bucket as follows:
- Create a small text document.
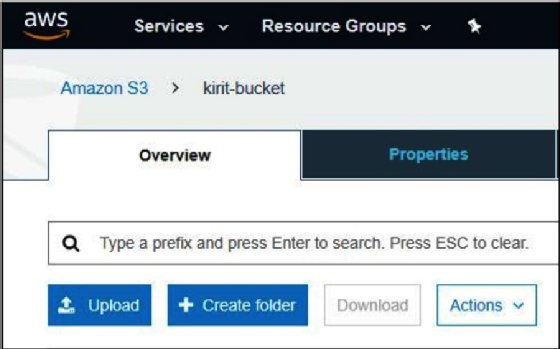
- Enter your bucket and click on Upload:
![Screenshot of how to upload a bucket in AWS S3 Overview tab]()
- Select the file and upload it.
Once the file has been uploaded, click on the object, and you will receive an S3 URL to access the object from the outside. You can simply point your browser to the URL in order to access the bucket:
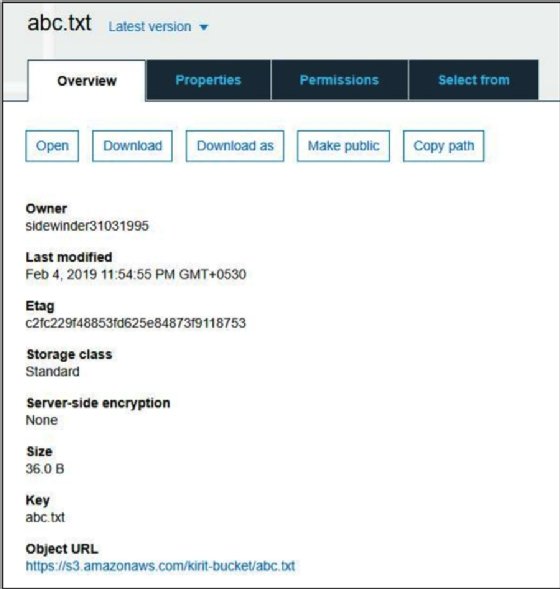
The Object URL link is located at the bottom of the page, as demonstrated in the preceding screenshot.
Our vulnerable S3 bucket has now been set up and made accessible to the public; anyone can read or write to this bucket.
In the next chapter, we will learn how to identify such vulnerable buckets and exfiltrate data using AWSBucketDump.
About the author
 Benjamin Caudill
Benjamin Caudill
Benjamin Caudill is a security researcher and founder of pen testing firm Rhino Security Labs. Building on 10-plus years of offensive security experience, Caudill directed the company with research and development as its foundation into a key resource for high-needs clients. He has also been a major contributor to AWS security research. With co-researcher Spencer Gietzen, the two have developed Pacu (the AWS exploitation framework) and identified dozens of new attack vectors in cloud architecture.
As a regular contributor to the security industry, Caudill has been featured on CNN, Wired, The Washington Post and other major media outlets.
Dig Deeper on Cloud security
-
![]()
How to import existing AWS resources into a CloudFormation stack
By: Ernesto Marquez
-
![]()
Sample Questions for AWS' Security Specialist Certification
By: Cameron McKenzie
-
![]()
Researchers unveil AWS vulnerabilities, 'shadow resource' vector
By: Rob Wright
-
![]()
Why Amazon S3 is a ransomware target and how to protect it
By: Mike Matchett



