service-oriented architecture (SOA)
What is service-oriented architecture?
Service-oriented architecture (SOA) is a software development model that makes services reusable and lets them communicate across different platforms and languages to form new applications. An SOA service is a self-contained unit of software designed to complete a specific task. Applications use SOA and simple interface standards to access services to form new applications.
SOA creates interoperability between apps and services. It ensures existing applications can be easily scaled, while simultaneously reducing costs related to the development of business service solutions.
Enterprises also use SOA to build applications that require multiple systems to interact with each other efficiently. The defining concepts of SOA are the following:
- Business value is more important than technical strategy.
- Strategic goals are more important than benefits related to specific projects.
- Basic interoperability is more important than custom integration.
- Shared services are more important than implementations with a specific purpose.
- Continuous improvement is more important than immediate perfection.
How does service-oriented architecture work?
SOA simplifies complex software systems into reusable services that can be accessed by other applications and users referred to as service consumers. These services can be used as building blocks of new applications. Each SOA service has a specific task and an interface that includes the service's input and output parameters as well as the communication protocol required to access it.
SOA lets services communicate using a loose coupling system to either pass data or coordinate an activity. Loose coupling refers to a client of a service remaining independent of the service it requires. In addition, the client -- which can also be a service -- can communicate with other services, even when they aren't related. Through this process, various services can be combined to create more complex software that other applications can use as a single unit.
A consumer or application owner sends input data to request information or a task from a service. The service processes the data or performs its requested task and sends back a response. For example, an individual in sales or marketing could perform an SOA service request from a customer relationship management system, which provides access to customer data. The employee can give the service the relevant input, such as a specific customer's name, and it will return the requested response, which might include the customer's purchase history.
SOA is an implementation of the service concept or service model of computing. In this architectural style, business functions and processes are implemented as software services, accessed through a set of strictly defined application programming interfaces (APIs) and bound into applications through dynamic service orchestration.
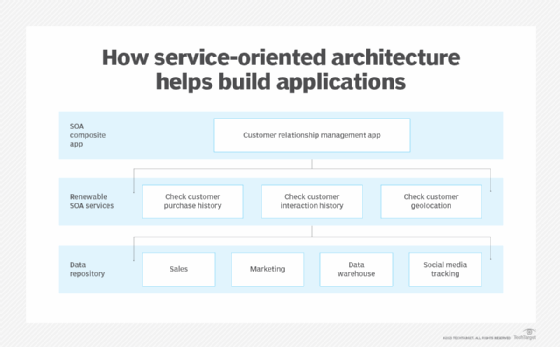
Components of SOA
There are typically four main components in SOA:
- Service. This is the foundation of SOA. Services can be private and available only to authorized users or Open Source and publicly available. Each service contains a service implementation, which is the code responsible for performing the service; a service contract, which describes the parameters of a service and its cost and quality; and a service interface, which is the layer of a service that defines how to communicate with it and handles communication with other services and systems.
- Service provider. This component creates or provides the service. Most organizations either create their own service or use third-party services.
- Service consumer. The service consumer is the individual, system, application or other service that makes service requests to the service provider. The service contract describes the rules for interaction between a service provider and service requester.
- Service registry. Also known as a service repository, a service registry is a directory of available services. It is tasked with storing service descriptions and other relevant information about how to use a service provider's services.
Major objectives of SOA
There are three major objectives of SOA, each of which focuses on a different part of the application lifecycle:
- Service. This objective aims to structure procedures or software components as services. Services are designed to be loosely coupled to applications, so they're only used when needed. They're also designed so software developers can easily use them to create applications in a consistent way.
- Publishing. SOA also aims to provide a mechanism for publishing available services that includes their functionality and input/output requirements. Services are published in a way that lets developers easily incorporate them into applications.
- Security. The third objective of SOA is to control the use of services to avoid security and governance problems. SOA relies on the security of the individual components within the architecture; the identity and authentication procedures related to those components; and the security of the connections between the components of the architecture.
The emergence of SOA
For decades, software development required the use of modular functional elements that perform a specific job in multiple places within an application. As application integration and component-sharing operations became linked to pools of hosting resources and distributed databases, enterprises needed a way to adapt their procedure-based development model to the use of remote, distributed components.
The general concept that emerged was the remote procedure call (RPC). This approach allowed one software process to invoke another as though it were local, even though the other process might be in a different application, computer or data center.
The problem with the RPC model was it allowed too much variation in implementation. It also lacked some important elements:
- A systematic set of tools to provide security for information flows.
- Governance of access rights to the business processes involved.
- Discovery, connection with and message formats for the services themselves.
The concept of services that SOA introduced is an integral part of modern cloud computing and virtualization. However, SOA itself has been largely displaced.
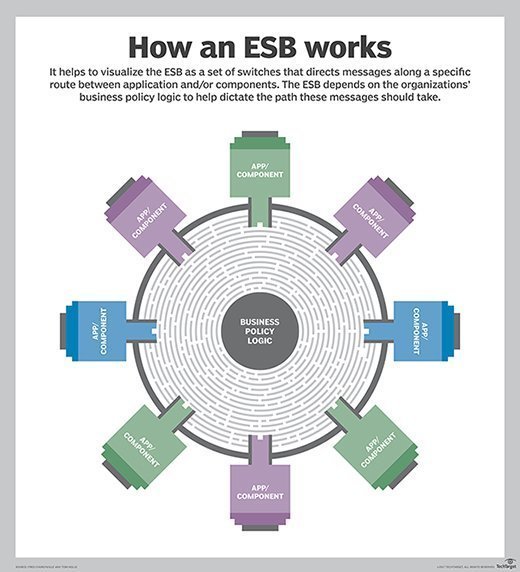
What is an enterprise service bus?
Most SOAs are implanted using an enterprise service bus (ESB). ESBs are so frequently used with SOAs that the terms are sometimes used interchangeably. An ESB is an architectural pattern that lets centralized software components integrate between applications. ESBs transform data models, handle routing and messaging, convert communication protocols, and manage the writing of multiple requests.
An ESB makes each one of these integrations its own service interface that new applications can reuse. Without an ESB, every application would have to connect directly to each service and service interface to perform its necessary integration or transformation, which makes building new software less efficient.
Implementation of SOA
SOA is independent of vendors and technologies. This means a variety of products can be used to implement the architecture. The decision of what to use depends on the goal of the system.
SOA is typically implemented with web services such as simple object access protocol (SOAP) and web services description language (WSDL). Other available implementation options include Windows Communication Foundation; gRPC; and messaging, such as with Java Message Service ActiveMQ and RabbitMQ.
SOA implementations can use one or more protocols and may also use a file system tool to communicate data. The protocols are independent of the underlying platform and programming language. The key to a successful implementation is the use of independent services that perform tasks in a standardized way without needing information about the calling application or the calling application requiring knowledge of the tasks the service performs.
Common applications of SOA include the following:
- Military forces use SOA to deploy situational awareness systems.
- Healthcare organizations use it to improve healthcare delivery.
- Mobile apps and games use SOA to access a device's built-in functions, such as the global positioning system.
- Museums use SOA to create virtualized storage systems for their information and content.
Benefits of service-oriented architecture
SOA comes with several key benefits:
- Standardization. SOA uses the RPC model commonly from structured programming. It standardizes how business processes are automated and used in a way that maintains security and governance.
- Reusability. Services can be reused to make multiple applications. SOA services are held in a repository and linked on demand, making each service a resource available to all, subject to governance constraints. Reusing services saves organizations time and lowers development costs associated.
- Ease of maintenance. Since all services are independent, they can be easily modified and updated without affecting other services. This lowers an organization's operating costs and speeds time to market for applications being developed.
- Interoperability promotion. The use of a standardized communication protocol lets platforms easily transmit data among clients and services regardless of the languages they're built on.
- High availability. SOA facilities are available to anyone upon request.
- Increased reliability. SOA generates more reliable applications because it's easier to debug small services than large code.
- Scalability. SOA lets service run on different servers, increasing scalability. In addition, using a standard communication protocol allows organizations to reduce the level of interaction between clients and services. With a lower level of interaction, applications can be scaled without adding extra pressure.
Limitations of service-oriented architecture
One of the main limitations of SOA is that the web services model isn't widely accepted or adopted. In part, this is because of its complexity. It's also because of the incompatibility between the web services approach and the representation state transfer model API (RESTful API) model of the internet. The internet and the cloud computing model exposed specific issues with SOA and web services, and the industry has moved to different models. That said, many experts still believe that SOA is still useful.
Other disadvantages of SOA include the following:
- Implementation of SOA requires a large initial investment.
- Service management is complicated because services exchange millions of messages that are hard to track.
- The input parameters of services are validated every time services interact, decreasing performance as well as increasing load and response times.
- Scalability is limited when services must coordinate with various shared resources.
- Complex SOA systems can develop dependencies among several services, making modification and debugging difficult.
- SOAs using ESBs create a single point of failure, making it impossible for clients and services to communicate when an ESB fails.
Web services and WSDL models of SOA
Initially, SOA implementations were based on RPC and object-broker technologies available around 2000. Since then, two SOA models have been emerged:
- Web services model. This approach uses highly architected and formalized management of remote procedures and components. It also uses WSDL to connect interfaces with services and SOAP and define procedure or component APIs. Web services principles link applications via an ESB, which helps businesses integrate their applications, ensure efficiency and improve data governance. This approach has never gained broad traction and is no longer favored by developers.
- REST model. The representational state transfer model represents the use of internet technology to access remotely hosted components of applications. It has gained attention because the RESTful APIs have low overhead and are easy to understand.
What is the difference between SOA vs. microservices?
REST and the internet supplanted SOA before it gained significant traction, confining SOA to legacy applications, often built around the ESB. RESTful thinking converted the broader notion of services into software processes instead of business processes. That software-centric view became known as microservices, which is the term in use today.
The term web services is still used in the cloud, where it means the set of packaged cloud-provider services offered to facilitate development of cloud-based applications. There are dozens of these services available from all the public cloud providers, and they're all accessed through REST interfaces.
Microservices are the latest evolution of the services concept. They are small software feature components accessed through a REST interface. The modern practice is to enforce security and governance outside the service and microservice APIs, usually using a service broker that acts as an intermediary to authenticate access rights.
With this approach, SOA-like discovery and service repositories aren't relevant because software processes and microservices build applications, and application components are explicitly linked and not invoked according to workflows. Microservice discovery and binding is instead defined to support scalability under load and resilience, one of eight key characteristics of cloud computing.
Microservices can be shared among applications, and cloud providers may offer serverless, pay-as-you-use microservice architectures for hosting. In these cases, there may be a formal commercial microservice or service contract to describe the specific performance guarantees and the payment terms. Even internal microservices may have a contract if the IT organization charges departments back for use.
What is the difference between SOA vs. SaaS?
Software as a service (SaaS) is a form of public cloud computing where a service provider or a public cloud provider offers a complete business application via a RESTful API from the cloud.
SaaS is another cloud development that has impacted SOA and, in some ways, returns to the original SOA principles. SaaS could more properly be called application as a service because the goal is to provide complete support for a business process in the cloud. Since the service is a business process, SaaS is like SOA. It's also like some forms of microservices in that SaaS is offered in accordance with a service contract that describes service levels and pricing.
SaaS services will almost always offer APIs to support the integration of SaaS work with other business processes still hosted in the data center or even in another cloud. However, these interfaces will obey modern microservice and API conventions, not SOA and web services conventions.
Learn more about the technologies and tools available for software application development in this look at ways to enable secure software development.







