StorPool adds fast erasure coding to block storage
Latest release of StorPool Storage enables high-performance data protection for block storage using erasure coding on standard SSDs for fast recovery of demanding applications.
A compute-intense form of data protection can now support block storage in the latest release of StorPool’s flagship offering, enabling recovery of data for mission-critical enterprise databases and applications.
StorPool Storage v21, available today, supports high-performance erasure coding capabilities for scale-out block storage used by mission-critical applications on commodity flash storage among other new capabilities including new integrations with technology partners.
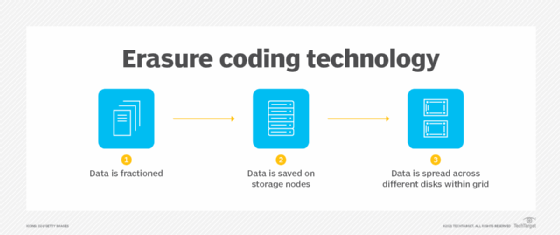
Erasure coding is a form of data protection which breaks data into fragments which are spread across redundant storage locations to enable recovery. Block storage demands performance from hardware, said Ray Lucchesi, founder and president of Silverton Consulting.
However, it’s difficult to support the performance requirements that erasure coding requires alongside block storage without impacting application performance, he said. Other vendors have tried in the past with the use of custom hardware.
“Not a lot [of vendors] have done what they’re doing,” Lucchesi said. “If you want to do erasure coding, you’d got to have some way of maintaining performance parity.”
Rebuilding in block
StorPool sells virtual storage array software that runs on any hardware. It enables distributed block storage for demanding database workloads on traditional hard drives as well as flash and NVMe drives both on premises and in the cloud.
The company typically sells to managed service providers and private clouds that use virtual machines.
The new scale-out block erasure coding capability in StorPool Storage v21 builds off traditional erasure coding, which usually targets file or object workloads. Erasure coding breaks data into fragments with redundant pieces of data available across other storage media. Should a drive fail, this replicated data enables a faster form of recovery rather than replicating the entire drive.
StorPool’s new erasure coding for block requires at least five all-NVMe storage servers to use. Specific new capabilities include cross-node data protection, which enables data replication in more locations and delayed batch-encoding to reduce processing overheads for replication requests.
Having enough NVMe servers allows always-on capabilities for up to two storage nodes to be brought offline for service without impact to available data, according to StorPool.
The StorPool v21 release supports new deployment options and capabilities for StorPool partners. The software now supports volume encryption and migration capabilities for CloudStack, an open-source cloud infrastructure platform. New integrations with the Proxmox Virtual Environment, open-source server virtualization software, bring storage automation to the enterprise stack suite.
Erasure coding stores data across different disks to protect against any single point of failure.
Power to keep pace
The trade-off of using erasure coding comes from the potential impact to performance for a storage cluster, said Marc Staimer, founder and president of Dragon Slayer Consulting.
Erasure [coding] is the next generation of RAID.
Marc StaimerPresident, Dragon Slayer Consulting
Erasure coding runs against all data written to storage and across all used disks, thus impacting CPU performance during writes and recovery, Staimer said.
Block storage usually has higher performance demands compared to file and object storage, so using erasure coding in conjunction with block further degrades performance. Staimer anticipates more storage vendors will use erasure coding for data protection, however, as performance capabilities and availability of SSDs continue to increase and eventually supplant RAID, which typically uses cheaper hard disk drives.
“Erasure [coding] is the next generation of RAID,” Staimer said. “I suspect it will show up in more primary storage.”
Tim McCarthy is a journalist living in the Merrimack Valley of Massachusetts. He covers cloud and data storage news.