Achieve multi-cloud data protection with archiving, backup and DR
How can multi-cloud users effectively use DR, backup and archiving together? Although multiple clouds complicate infrastructure, they also offer benefits for data protection.
To improve business continuity and better control costs, in 2020, enterprises will pressure their IT professionals to start breaking down the silos between on- and off-premises infrastructure, and between public cloud providers' discrete environments. Doing so requires transitioning to multi-cloud data protection practices that join on-premises private cloud and traditional IT infrastructures with multiple public cloud services.
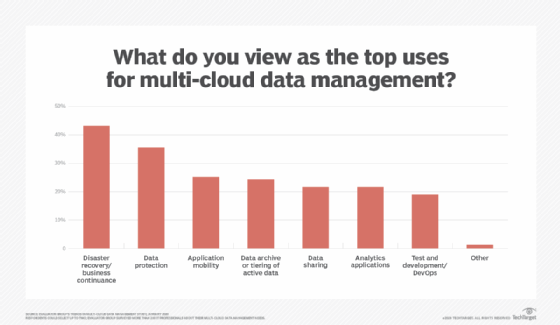
Although enterprises are still in the early days of transitioning their infrastructures and operating models to multi-cloud, data protection technologies will play a pivotal role in providing foundational data management capabilities. Evaluator Group surveyed more than 200 IT professionals about how they address their multi-cloud data management needs and found archive and long-term retention as well as backup storage systems and cloud services to be the most popular building blocks -- both noted by 54% of respondents. This study, "Trends in Multi-Cloud Data Management," also found backup software and disaster recovery technologies and products to be the second- and third-most popular, noted by 48% and 46%, respectively.
IT professionals can evolve how they use archive, backup and disaster recovery technologies -- well-established cornerstones of enterprise data protection implementations -- to address the demands of multi-cloud infrastructures.
What's changing (or not)?
Fundamentally, the relationship between archive, backup and DR -- or, at least, what this relationship should be -- stays the same with multi-cloud data protection, compared to a single cloud or fully on-premises environment. Backups remain the primary means of avoiding total data loss. They also serve as the recovery point for workloads with less stringent recovery point objectives and recovery time objectives. Disaster recovery remains about getting the business back online -- sometimes from backups, other times through replication. Meanwhile, archiving naturally continues to address long-term data retention needs.
From a disaster recovery perspective, multi-cloud data protection opens new options for enterprises to mitigate downtime and data loss.
In the face of so many moving parts in a multi-cloud world, visibility becomes paramount to avoiding vulnerability to risks like inconsistent or overlapping protection policies, unprotected assets and noncompliance. Data sprawl is an unavoidable outcome of multi-cloud, and IT must have visibility into all the data created across various infrastructures, so that it can be stored, protected and governed appropriately.
Metadata cataloguing tools provide functions such as discovery and scanning, tagging, indexing, classification and search that become important complements to archive and backup technologies. Automation is also key for rolling out changes in policies across heterogeneous infrastructure resources and for reacting to dynamic threat and compliance landscapes.
From a disaster recovery perspective, multi-cloud data protection opens new options for enterprises to mitigate downtime and data loss. For example, organizations can turn to the public cloud as a failover site for their on-premises production data centers. In fact, Evaluator Group's study found that improved disaster recovery and business continuance is the most common benefit expected from -- and success metric of -- multi-cloud data management. The major problem that businesses still must solve, however, remains the inherent and notorious incompatibility between public cloud providers' environments; Evaluator Group expects this area to receive ongoing investment from third parties in 2020.
Areas of overlap
Historically, many enterprises have effectively treated their backup environments as an archive or long-term data repository, but this becomes a less feasible option from a cost perspective as enterprises increasingly store more data for longer periods of time. The introduction of cloud services such as Amazon S3 Glacier Deep Archive creates opportunities to meet retention requirements more cost-effectively.
Taking advantage of these multi-cloud data protection services requires an automated and intelligent data tiering strategy -- especially as cloud providers regularly adjust pricing and introduce new services. Many IT professionals find success using disaster recovery technologies to migrate workloads from on-premises to the public cloud.