Bill Inmon's data warehouse approach tackles text analysis
Learn the fine points of a concept at the heart of 'The Textual Warehouse' a new book that aims to help organizations profit through textual analysis.

In The Textual Warehouse (Technics, 2021) authors Bill Inmon and Ranjeet Srivastava aim to help organizations make better business decisions through document analysis. This article, an excerpt from the book, explains textual warehouses, a central concept in text analytics.
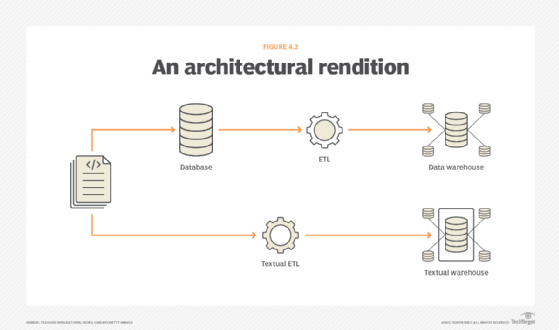
At the center of doing textual analytics and managing text in the corporation is an architectural feature known as the textual warehouse. Identifying and qualifying data from the document goes into a database. The important business-related text that does not go into the database goes into the textual warehouse.

The textual warehouse contains the simple data that comes from documents. Fig 4.1 shows that the identifying and the qualifying data from the document goes into a database. The important business-related text that does not go into the database goes into the textual warehouse.
Where's the data warehouse?
To see the fuller picture, once the identifying and qualifying data is placed into a database, eventually that data finds its way into the data warehouse.
ETL is needed to make these transformations of data happen. Two forms of ETL are needed: standard ETL that integrates application data into a data warehouse and textual ETL, which transforms raw text into a textual warehouse.
Textual warehouse -- a definition
A textual warehouse is a collection of business-relevant text that is referenced back to its source document. Usually, the text in the textual warehouse also contains the classification of the text.
 To learn more about this
To learn more about this
new book from Bill Inmon,
click here.
As an example of what might be in a textual warehouse, there might be an entry that looks like this:
- Red pony -- word
- Farm animal -- classification
- Book by John Steinbeck, NA128.68 -- location
- 2087 (first byte) -- byte address
The entry in the textual warehouse tells what the word that is being described is, what its classification is, where it can be found and the byte address where it can be found in the source document.
Who needs a textual warehouse?
Who needs a textual warehouse? Anyone who:
- Has a large amount of text.
- Has to store the text for a lengthy period of time.
- Needs to periodically search textual documents.
This list includes many organizations, such as:
- Insurance companies
- Banks
- Finance organizations
- Government
- Manufacturers
Document types to store in a textual warehouse include:
- Insurance policies
- Contracts
- Bill of materials specifications
- Deeds of trust
- Warranties
- Medical records
- Patient discharge summary
- Human resource profile
- Automotive quality reports
When do you need a textual warehouse
This answer is a little bit different for every company. There is no standard answer here.
For small organizations and startups, they can probably do without a textual warehouse. But at some point, in time, the volume of information to be managed starts to become overwhelming. When an organization reaches the point where they need textual documents to run their business properly and cannot find those documents easily and efficiently, they need a textual warehouse.
It is normal for an organization to experience challenges in managing its textual documents before building a textual warehouse. It is unusual for an organization to be proactive in the building of a textual warehouse. In fact, nearly all organizations build their textual warehouse in a reactive mode, where the pain level has risen to a critical point. Fig 4.3 shows that a certain period of time passes before an organization builds its textual warehouse.
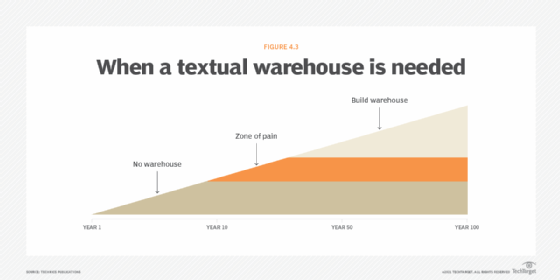
So as shown in the image above, it doesn't mean that you need a textual warehouse only after 20-25 years of your business. The diagram above is symbolic only. The faster you generate text, the sooner you will need a textual warehouse.
Why do you build a textual warehouse?
There are two primary reasons why an organization builds a textual warehouse:
- As an aid to finding relevant documents
- As a basis for analytical processing
Either or both of the reasons for building a textual warehouse can be found in an organization.
The second reason is obvious and the ultimate purpose. The first reason is related to cross-referencing the source of the data and text captured in the textual warehouse. So, the source document reference might be needed for various obvious reasons, like contracts, agreements, court hearings and medical transcriptions.

But for some organizations, there is another motive for building a textual warehouse. That reason is that infrastructure helps to find anything in big data. A lot of organizations invested in big data to understand the infrastructure that was needed. But for the most part, big data never delivered on this part of the infrastructure. In this regard, a textual warehouse is a part of the infrastructure that can be used to help the end-user make the big data environment more effective. A textual warehouse can be useful for finding things in big data and even data lakes or data lakehouses, for various business-related textual analytics purposes.
Ingredients of construction
There are two ingredients that are needed to design a textual warehouse:
- The raw documents of the organization
- An understanding of the business itself
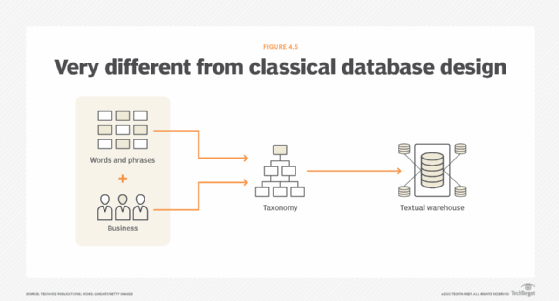
The words and phrases that are important to the business form the basis for the design of the textual warehouse. To the database designer who does classical database design, it seems odd that there is no mention or even a reference to processes in the design of the text warehouse. Indeed, the textual warehouse design is very different from classical database design.
The operation of a textual warehouse
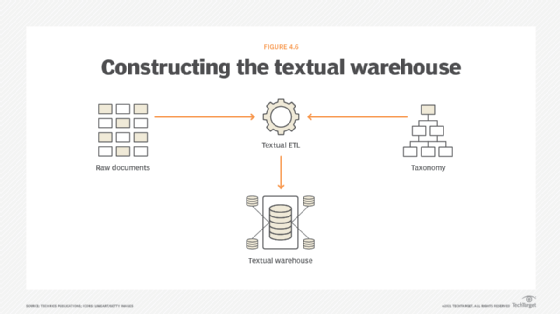
So how does the text warehouse environment operate? The operation of the text warehouse environment starts with the creation of the taxonomy.
The taxonomy is a list of the words and classifications of the business that are important to the business. It is a classification of something. For example, we can classify car insurance, home insurance, life insurance, business insurance, bike insurance and home appliances insurance as "general insurance." So general insurance is the taxonomy of all those insurances listed above.
General insurance
- car insurance
- home insurance
- life insurance
- business insurance
- bike insurance
- home appliance insurance
Once the taxonomy is created, the raw text is passed through textual ETL and the taxonomies help us find the important text. After the raw text is processed, the textual warehouse is created.
About the authors
Bill Inmon, the "father of the data warehouse," has written 60 books published in nine languages. ComputerWorld named Bill one of the 10 most influential people in the history of the computer profession. Bill's latest adventure is the building of technology known as textual disambiguation.
Ranjeet Srivastava is a data management professional and an enterprise architect with more than 20 years in enterprise product research, development and design of data-intensive mission-critical applications.
https://technicspub.com/the_textual_warehouse/







