InfluxData update ups speed, power of time series database
The new version of InfluxDB features an architecture built with Apache Arrow and written in Rust to improve the speed and flexibility of the time series database.
InfluxData has launched a revamped version of its platform designed to improve the speed, power and flexibility of the vendor's time series database.
InfluxData is a specialist in time series data management and the creator and lead sponsor of InfluxDB, an open source database optimized to manage the unique data that enables time series analysis. In February 2023, the San Francisco-based vendor raised $81 million in combined venture capital funding and other corporate financing to bring its total funding to more than $200 million.
On April 26, just over two months later, InfluxData unveiled InfluxDB 3.0.
InfluxDB 3.0 is generally available in the vendor's cloud products -- InfluxDB Cloud Serverless and InfluxDB Cloud Dedicated -- and will be available in the vendor's self-managed products later this year. The new version not only aims to improve on previous versions of the vendor's platform but also serves as the foundation for future additions to InfluxDB.
New capabilities
Time series data is a set of data collected at successive intervals and listed in the order the events captured occurred. Time series databases, meanwhile, are optimized for time series data because they sort and organize data based on the time events actually occurred.
Rather than lump data together in a random order, the database technology instead automatically arranges data points in the order they took place.
Besides InfluxData, vendors specializing in time series data management include Grafana and Prometheus. Tech giants such as Amazon, Google, IBM and Microsoft also offer databases dedicated specifically to time series data.
Key uses for time series database applications include IoT applications, such as industrial and scientific process monitoring, and IT system monitoring.
New capabilities included in InfluxData 3.0 include the following:
Real-time query responses that are 100 times faster than previous versions of InfluxDB.
Unlimited cardinality – a reference to the uniqueness of the values in a database column with a high level of distinctness meaning the column has high cardinality – combined with high throughput to enable customers to ingest, transform and analyze hundreds of millions of time series data points per second.
Increased data compression that lets users store 10 times more data and reduces the cost of storing that data.
Support for SQL so that customers can use the popular programming language for their queries and analysis.
Perhaps the most important addition to InfluxData's capabilities is the attempt to enable unlimited cardinality, according to Rachel Stephens, an analyst at RedMonk.
"Cardinality is historically one of the biggest limitations of time series databases," she said.
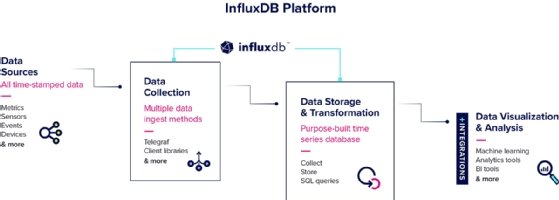
A graphic from InfluxData displays the workflow of the vendor's time series database.
In particular, she noted that high cardinality has made it difficult for time series databases to log or trace unique use cases.
InfluxData, however, changed the infrastructure of InfluxDB in version of 3.0.
The new version is built with Apache Arrow, an open source software framework designed specifically to enable processing of columnar data. In addition, it was written in Rust, a programming language designed for performance, safety and memory management.
"InfluxDB 3.0 attempts to address the problem of cardinality in time series databases, and they did that through an overhaul of the database's core engine," Stephens said.
InfluxData vice president of product Rick Spencer also noted the importance of unlimited cardinality.
Unlimited cardinality combined with support for SQL and faster processing represent a significant improvement over previous iterations of InfluxDB, according to Spencer.
"We're bringing a series of next generation capabilities to our customers -- namely SQL support; high-performance, real-time querying; and unlimited cardinality," he said. "Together, these deliver gains in ingest performance, scalability, resilience and efficiency even as data complexity and cardinality increase."
InfluxDB 3.0 attempts to address the problem of cardinality in time series databases, and they did that through an overhaul of the database's core engine.
Rachel StephensAnalyst, RedMonk
While platform updates are often motivated by requests from customers asking for new features and improved performance, the impetus for developing InfluxDB 3.0 came from InfluxData founder and CTO Paul Dix, according to Spencer.
He noted that Dix envisioned InfluxDB as a single database for a complete range of time series data that goes beyond just support for metrics and includes precise observation of data at scale.
"His goal was to re-architect InfluxDB for real-time analytics, optimized for time series specifically," Spencer said. "[Dix] realized early on that by opting into the Apache Arrow project, and its columnar approach, we could build the definitive database for real-time analytics while also participating in and benefiting from a vibrant upstream ecosystem."
As intended, InfluxDB 3.0 expands the range of time series data applications beyond the capabilities of previous versions of the database, according to Stephens.
"Overall, this opens up more observability use cases for the database -- like working with log and tracing data -- and improves ecosystem compatibility with their introductions of Apache Arrow, Apache Parquet and SQL," she said.
Future plans
With InfluxDB 3.0 now generally available for InfluxData's cloud customers, the vendor's next step will be to launch self-managed versions of the database -- InfluxDB 3.0 Clustered and InfluxDB 3.0 Edge -- according to Spencer.
"We are ensuring that we retain as much compatibility with InfluxDB Enterprise as possible," Spencer said.
Beyond the InfluxDB 3.0 versions of Clustered and Edge, InfluxData's roadmap includes regular updates to the new products now built on the 3.0 architecture, he continued.
Eric Avidon is a senior news writer for TechTarget Editorial and a journalist with more than 25 years of experience. He covers analytics and data management.