InfluxData launches new database for self-managed users
The time series database vendor completed the InfluxDB 3.0 product line with the release of InfluxDB Clustered, a version tailored for private cloud and on-premises deployments.
InfluxData on Wednesday introduced InfluxDB Clustered, a self-managed version of the vendor's time series database.
InfluxDB Clustered, designed for on-premises and private cloud deployments, completes InfluxData's commercial product line developed on InfluxDB 3.0. First unveiled in April, InfluxDB 3.0 is a revamped version of InfluxData's time series database and was designed to improve its speed, power and flexibility.
InfluxDB Clustered essentially replaces InfluxDB Enterprise, the vendor's long-standing database platform for on-premises and private cloud customers.
In addition to InfluxDB Clustered, the vendor's 3.0 product line includes InfluxDB Cloud Serverless for organizations with small workloads and InfluxDB Cloud Dedicated for organizations with larger workloads. Both are fully managed options and were previously made generally available.
San Francisco-based InfluxData specializes in time series data management and is the lead sponsor of InfluxDB, an open source database designed specifically to manage the data that fuels time series analysis.
Its launch of InfluxDB 3.0 came shortly after raising $81 million in funding from venture capitalists and other corporate investors to bring its total funding to more than $200 million.
New capabilities
Time series data is simply data with a time stamp so that changes can be tracked over time.
And just as the overall amount of data being created is increasing, so is the amount of data that enables changes to be tracked over time. Sources now include -- among others -- IoT sensors and IT infrastructure logs to help manage the health of increasingly complex systems.
As a result of the increasing reliance on time series data, several vendors are now developing databases that specialize in managing time series data.
In addition to InfluxData, time series database vendors include Grafana and Prometheus. Tech giants including Amazon, Google, IBM and Microsoft also offer dedicated time series databases in addition to their other database products.
Common characteristics of time series databases, meanwhile, include optimization for large-scale workloads given the amount of time-specific data organizations collect, high-performance reading and writing capabilities to enable real-time analysis, data lifecycle management processes so that older data can be retained and found and filters specific to time-based queries.
Because they're capable of handling the scale and complexity of time series data, time series databases have been effective enablers of time series analysis in recent years and will continue to gain relevance as IoT and other time-specific data volume grows, according to Carl Olofson, an analyst at IDC.
In particular, he noted that the way they simplify time series analysis is significant.
"Time series has been an important issue in the database world for a long time," Olofson said. "It is particularly critical for managing and analyzing sensor data. The importance of time series support in the database is that it makes time interval analysis easy to do without a lot of coding and advanced math."
Simplification and versatility are among the main benefits InfluxDB 3.0 has over previous iterations of InfluxDB, according to Rachel Stephens, an analyst at RedMonk.
She noted that one of the main characteristics of the database's April debut was substantially faster queries on high cardinality data -- cardinality refers to the uniqueness of the values in a database column with a high level of distinctness, meaning the column has high cardinality.
Changing the underlying database engine was significant for InfluxDB. The 3.0 changes brought more versatility to the database.
Rachel StephensAnalyst, RedMonk
In addition, Stephens noted that InfluxDB 3.0's support for SQL -- which was not available in previous versions of InfluxDB -- meant users familiar with the popular query language could more easily run queries.
"Changing the underlying database engine was significant for InfluxDB," she said. "The 3.0 changes brought more versatility to the database."
Now, with the launch of InfluxDB Clustered, that versatility is being extended to InfluxData's on-premises and private cloud customers.
"InfluxData first introduced these changes via its managed cloud products," Stephens said. "InfluxDB Clustered brings the more performant experience of the new database engine to customers' self-managed environments."
Beyond support for SQL and faster queries on high cardinality data, InfluxDB Clustered provides the former users of InfluxDB Enterprise with the following:
Faster data ingestion to better fuel real-time analytics.
Reduced storage costs resulting from data compression, new object storage capabilities and the separation of compute and storage.
And enterprise-grade security and compliance capabilities, including encryption of data while it's both being moved as well as at rest and attribute-based access controls.
Combined, the features are important additions for InfluxData as the vendor attempts to attract more enterprise customers, according to Olofson.
"The features make InfluxDB more of an enterprise-grade product, especially with regard to higher cardinality support, faster load times and reduced storage cost, all of which are critical factors for their segment of the market," he said. "Security is also top of mind for most enterprises, so addressing such issues is critical."
In fact, security and compliance are two reasons many database users choose to deploy on-premises or in a private cloud, according to Rick Spencer, InfluxData's vice president of product.
Enterprises that collect sensitive data need to know that data is secure, he said. On-premises and private cloud deployments don't guarantee the security of data, but they reduce its exposure to potential breaches.
They similarly make it easier for organizations to remain compliant with regulations, control costs and keep their data close to its source, Spencer continued.
Those customers now have the version of InfluxDB that suits their needs.
"This is the conclusion of the 3.0 product line," Spencer said. "From a customer point of view, this completes the picture for anyone that wants to run InfluxDB 3.0."
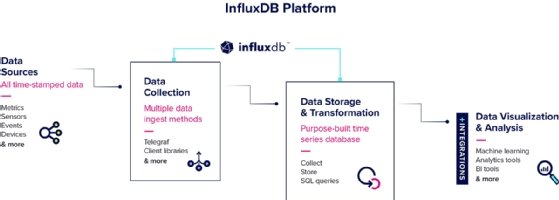
A graphic from InfluxData displays the workflow of the vendor's time series database.
Next steps
With the full InfluxDB 3.0 suite now available, InfluxData's roadmap includes plans to add more enterprise-grade features and continue improving the functionality of existing capabilities, according to Spencer.
"The more we optimize, the more we uncover other opportunities to optimize," he said. "The faster we can make the queries, the more different ways users can take advantage of their data."
In addition, making InfluxDB easier to deploy -- perhaps with a one-click option -- is something InfluxData is working on, Spencer continued.
Olofson, meanwhile, suggested the vendor could continue to improve its database by more easily enabling analysis between geographic regions and continuing to add real-time analytics capabilities.
"A big step would be geographic distribution for inter-region analysis and comparison of events in real time," he said.
Eric Avidon is a senior news writer for TechTarget Editorial and a journalist with more than 25 years of experience. He covers analytics and data management.