
spainter_vfx - stock.adobe.com
Unsupervised machine learning: Dealing with unknown data
Learn how machine learning works when dealing with unclassified, unlabeled data sets and how, using certain algorithms and other practices, the system can learn on its own.
The following article is comprised of excerpts from the course "Fundamental Machine Learning" that is part of the Machine Learning Specialist certification program from Arcitura Education. It is the third part of the 13-part series, "Using machine learning algorithms, practices and patterns."
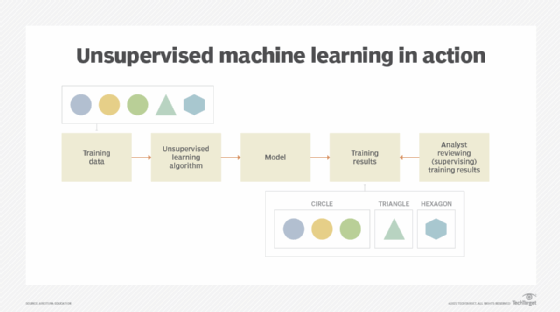
With unsupervised learning, the algorithm and model are subjected to "unknown" data -- that is, data for which no previously defined categories or labels exist. When data is unknown, the machine learning system must teach itself to classify the data. It accomplishes this by processing the unlabeled data with special algorithms to learn from its inherent structure (Figure 1).
Most of the time, data that is used in unsupervised learning is not historical data. For example, unsupervised learning can be used in healthcare to create a model that can categorize and identify the results of different tests to quickly identify abnormal situations or test results. The model can learn from different features of X-ray images or blood test results to categorize future tests or scans.
In unsupervised machine learning, clustering is the most common process used to identify and group similar entities or items together. This task is performed with the aim of finding similarities in data points and grouping similar data points together.
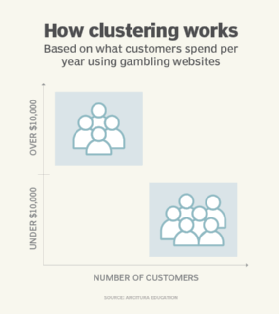
For example, the learning model identifies and groups high-risk customers by determining which spend more than a certain amount or more than a certain number of times in casinos or on gambling websites; it then categorizes them accordingly in a group (Figure 2).
Grouping similar data points helps to create a more accurate profile and attributes for different groups. Clustering can also be used to reduce the dimensionality of the data when there are significant amounts of data.
Categorization can further identify the featured data that is needed, and another process can then extract the featured data. For example, clustering can be used to group and identify certain data points to represent different social interactions with the profile of a social media influencer, such as: likes, dislikes, shared posts and comments.
The hypothetical toy company, introduced in Part 2, continues to look for ways to gain further insights into its customer base. It sends an online survey to all of its customers, asking them to fill out a questionnaire about their preferences regarding the types of toys they enjoy buying for their families and how much they prefer to spend on toys each year. The toy company gets a good response, primarily because it includes the promise that all customers who complete the survey will be entered into a raffle for a series of high-end prizes.
The company uses a clustering algorithm to mine the database in which survey results are recorded. The algorithm looks for common responses and compares those against common characteristics of the customer profiles. Doing so results in potentially useful groups or clusters of data.
After the clustering process is completed, the following new data clusters are discovered and characterized by the analyst:
- Cluster A: Customers who have historically paid by credit card are more likely to spend more on toys each year than those who usually pay by cash.
- Cluster B: Customers who have three or more children are more likely to purchase outdoor toys priced at over $100 than those who have fewer children.
The toy company adds a new class label to each customer record (based on its cluster membership) as further input for future model building using classification algorithms.
Dimension reduction algorithms
Dimension reduction algorithms are used to decrease the number of characteristics or attributes in data sets so that the data generated is more relevant to the problem being solved, and less difficult to visualize and understand. Reducing dimensions further helps reduce the amount of space required for storing data sets and can also improve performance, as data sets are trimmed down and optimized, thereby decreasing the time required to perform computations. Dimension reduction algorithms exist for both supervised and unsupervised learning.
Our hypothetical toy company, when carrying out classification and regression algorithms, has been using a standard set of characteristics about customers, including:
- geographic location
- age group
- average transaction amount
- transaction frequency
- frequency of returns
- types of toys purchased
In an attempt to reduce the number of factors (features) taken into consideration when each model is trained, the toy company attempts to reduce the quantity of these characteristics (dimensions) to only those most relevant and valuable to its machine learning analysis goals.
They deploy a dimension reduction algorithm for this purpose. Upon running the algorithm, it is determined that the age group and frequency of returns values add negligible value to the typical analysis results, so they are dropped from further classification and regression processing. The remaining features are used in subsequent model development because they have higher predictive potential.
Semi-supervised learning
Semi-supervised learning is a hybrid approach that combines aspects of supervised and unsupervised learning. Commonly, semi-supervised learning is carried with a smaller volume of labeled historical data that is combined with a quantity of unlabeled (unknown) data. These two types of data are combined to form the training data used to train a model. Essentially, the labeled data establishes base labels and categories that are used as a starting point for the algorithm to process related unlabeled data.
This approach is often necessary when it is considered too time-consuming and expensive to collect, pre-process and label large amounts of historical training data.
Reinforcement learning
Reinforcement learning is a learning method that interacts with its environment by producing actions and discovering errors or rewards. Trial-and-error searches and delayed rewards are the most relevant characteristics of reinforcement learning. This method allows machines and software agents to automatically determine an ideal behavior within a specific context in order to maximize its performance.
In other words, reinforcement learning uses a trial-and-error model to teach the machine so that it can learn the required behaviors and decisions needed to make the expected decisions. Reinforcement learning is used in robotics, gaming and self-driving cars.
What's next?
The remaining 10 parts of this series focus on proven machine learning techniques in a standard patterns format. (These patterns should not be confused with computation and data-related patterns resulting from machine learning processing.) The next article focuses on two exploration patterns: central tendency computation and variability computation.
View the full series
This lesson is one in a 13-part series on using machine learning algorithms, practices and patterns. Click the titles below to read the other available lessons.
Course overviewLesson 1: Introduction to using machine learning
Lesson 2: The supervised approach to machine learning
Lesson 3
Lesson 4: Common ML patterns: central tendency and variability
Lesson 5: Associativity, graphical summary computations aid ML insights
Lesson 6: How feature selection, extraction improve ML predictions
Lesson 7: 2 data-wrangling techniques for better machine learning
Lesson 8: Wrangling data with feature discretization, standardization
Lesson 9: 2 supervised learning techniques that aid value predictions
Lesson 10:Discover 2 unsupervised techniques that help categorize data
Lesson 11: ML model optimization with ensemble learning, retraining
Lesson 12: 3 ways to evaluate and improve machine learning models
Lesson 13: Model optimization methods to cut latency, adapt to new data





