Use event-driven architecture to design for DevOps 2.0
Collaboration is key to DevOps, but it will be even more important to DevOps 2.0. Expert Bob Reselman explains how event-driven architecture will help us build the next-gen DevOps.
When we begin to think about how DevOps 2.0 will function, event-driven architecture is a good place to start. An "event" can range from a left click of a mouse button to a request for a hotel reservation. The important thing to understand, though, is that in event-driven architecture, no one can really predict where a message will end up. The fact that event notifications can go anywhere at anytime has definite implications for systems in terms of design, implementation and testing. From a DevOps 2.0 systems point of view, we need to think beyond component independence.
System independence vs. collaboration
Event-driven architectures promote process independence. A process will act upon a given message within the scope and intention of its area of concern. Many system designers translate this notion of process independence into process isolation, meaning that developers, testers and support personnel need only concern themselves with the internals of the process and do their work accordingly. While such a purist approach has value for most activities in the software development lifecycle (SDLC), things change once DevOps gets going and all the parts start to interact with one another. Independence does not forgo cooperation. In fact, the further down the SDLC we go, the more cooperation matters. This is especially true for DevOps 2.0.
Most modern event-driven architectures are distributed. The simplest case is a login message in the form of an HTTP request, sent from browser to server. A more advanced case is a supply chain activity -- buying paper clips for example -- which means messages sent to management, purchasing, finance, more management, fulfillment, receiving and internal distribution. Such messaging can take place among a variety of systems in a variety of locations. While each process and system in the supply chain can be designed and implemented independently of one another, at some point, they need to work together to get the goods in the hands of the people in need. In terms of system design and implementation, cooperation becomes essential. Otherwise things can go wrong.
Set cross-functional standards
What do you do when your system emits similar info in different messaging formats? It's one of the biggest troublemakers associated with inter-process messaging. Deciphering, processing and forwarding messages are much easier when you have a common message format in play.
Systems with multiple message formats need to support more rule sets to translate data. For example, you might have to write one set of rules to inspect information in XML format and another set of rules to inspect information in JavaScript Object Notation (JSON) or CSV. This all results in more work for development, testing and support teams, but also increases the risk of error in your system. Few things bring a workflow system to a halt faster than when a process receives a message it has no idea how to decipher, let alone execute.
A system is only as good as is the ability of each component in the system to consume and process a message effectively.
As we stare down the barrel of DevOps 2.0, the easiest way for a company to avoid the risk of inconsistent message formats is to have developers, testers and delivery personnel work together in a cross-functional manner to specify a standard message specification. The standard should not be overly detailed or complex. It can be something as straightforward as agreement to use JSON and to define the required fields within the schema described by the JSON.
The most important thing is that the specification establishes a standard that is predictable and easy to consume. When it comes to making an event-driven architecture that is all-encompassing and scalable for DevOps 2.0, a consistent message format matters.
Take a cooperative approach to performance testing
Performance testing a system when everything runs in a prescribed sequence is a straightforward undertaking: start, test, stop and analyze. But what do you do when things do not happen sequentially, which is essentially the way an event-driven architectures runs?
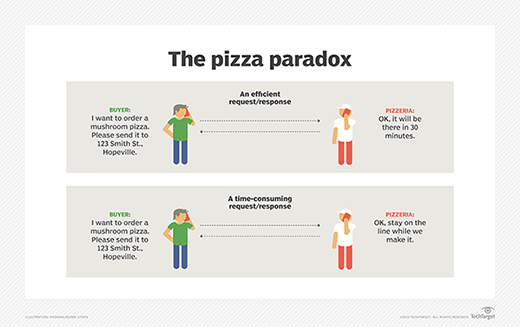
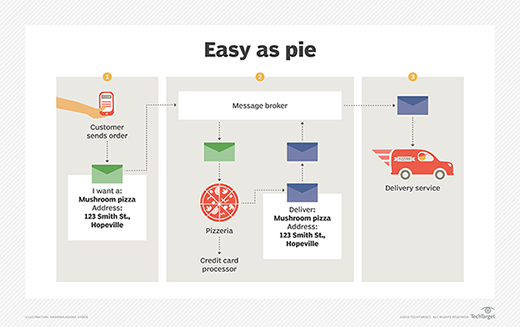
If we order a pizza, and all we measure in terms of performance testing is the time from when it's ordered to when it shows up at our door, how would we pinpoint a problem if the transaction stalled? The pizzeria's credit card processor could be operating at a snail's pace, and we'd have no idea. Yes, we could figure out the timespan from when the pizzeria receives our "buy pizza" message and when the delivery service receives the "pizza ready" message. We'd thus determine that the bottleneck was caused by the pizzeria. But we have no visibility into the credit card processing. That's internal to the pizzeria. What are we to do?
A long running response can cause a bottleneck in a workflow.
This is when a cooperative approach becomes important. Staying with our pizza analogy, what if we were to say to the pizzeria, "Would you mind emitting messages to a test message broker that describe your activities for a given pizza order? Using the pizza order number as key, we can correlate your activities to ours and figure things out. Of course, we'll keep things private between us."
Let's take the pizza analogy to the real world. A key to improving performance testing capabilities -- among components in an event-driven asynchronous architecture -- is to get on-demand performance metrics from a component. For example, most credit card authorizers offer a test mode that developers use to exercise code as if real transactions are in force. We can apply his notion of test mode to performance testing in an event-driven system. The key is cooperation among processes within the system. When we think about DevOps 2.0, the trick to getting developers, testers and release personnel to all cooperate and agree is to provide a way to publish information about a component's operational behavior on demand. That way any team can analyze it later on. This information can be published as structured log entries or as predefined event messages to a message broker dedicated to collecting test data.
This example shows how systems based on messaging reduce inter-process latency.
If you want to accurately assess system performance, you need to understand that behavior will happen in a variety of components. Understand that this will happen at potentially unpredictable times, and you'll need plans in place so any component can report behavior according to predefined metrics in a predictable manner. These metrics can be memory utilization, disk consumption, CPU consumption and error rates, among other things. The important thing is to establish and publish these metrics in a cooperative manner among all those working within the system.
DevOps isn't magic; it's a map
Although it's been said a billion times before, allow me to mention it once again: Documentation that describes the structure and operation of the system and its constituent parts clearly, with lots of examples, is essential for working effectively within the given system. In order for people to work within a system, they need to know the system. There's no magic in play. There needs to be a reliable reference. That's true now, and that will most certainly be true in DevOps 2.0.
Thus, just as domain experts write the code for a given part of an event-driven architecture, experts of each component need to develop their own documentation. But, as with messaging, the documentation needs to adhere to a common format. A good way to create good documentation is to work collaboratively across groups and create a master outline.
The important thing is that a common reference exists that anyone can quickly locate and modify to accommodate changes in the architecture, particularly in terms of message exchange.
Put it all together
A system is only as good as is the ability of each component to consume and process a message effectively. One bad message can create problems that will have impact later on. Also, asynchronous systems are hard to test in an ad hoc manner. Component independence, a fundamental architectural building block, does not lend itself well to unified testing.
The way to address these problems is through cooperation and planning among developers, testers and release personnel. Independence and separation of concerns allow components to change quickly to meet the growing needs of the enterprise.
Comprehensive collaboration that ensures message consistency, implementation of effective performance test planning and the creation of reliable, useful documentation are essential for a world class, event-driven architecture. It's the basis for DevOps 2.0.



.jpg)





