Machine learning for data analytics can solve big data storage issues
Discover how AI and machine learning -- with support from major vendors and technologies like Lambda architecture, FPGAs and containers -- address big data analytics challenges.
Large companies across a variety of industries have discovered hidden business value within existing data, and using machine learning algorithms to find hidden insight within that data has quickly become the norm. In spite of all of its benefits, machine learning for data analytics poses some challenges, particularly where storage infrastructure is concerned.
Because data can contain hidden value, organizations may be less inclined to purge aging data. This causes storage to be consumed at an accelerated rate, complicating capacity planning efforts. Furthermore, the actual analytical processes generate an additional load on the underlying storage infrastructure.
Somewhat ironically, several vendors have begun using AI as a tool for solving problems created by big data analytics. As it stands now, they have not based their machine learning for analytics efforts around one single technology, but rather on a disparate collection of technologies.
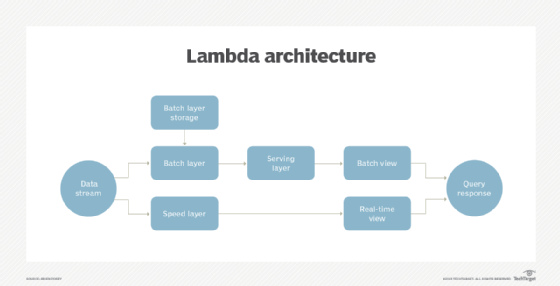
The Lambda architecture
When it comes to using AI for things like workload profiling and capacity planning, it is important to have access to current data pertaining to storage use and health. Even so, relying exclusively on real-time data may not always be desirable.
The problem with using real-time streaming data is that the data is raw and completely uncurated. Imperfections in the data stream might exist, and the fact that the data is being used in real time greatly limits the amount of processing that can be done.
Using data that is relatively current -- but not real time -- can often yield more information through machine learning for data analytics. But that data is not as up-to-date as the data that is streaming right now.
The Lambda architecture addresses this problem by simultaneously streaming data into two different layers: the batch layer and the speed layer. The batch layer's job is simply to store the data. Because this data is not being acted on in real time, batch rules can be used to improve the quality of the data. In some models, the batch layer can also make data available to a third layer -- the serving layer -- that creates batch views in response to query requests.
Inbound data is also streamed into the speed layer, which provides real-time data views.
When a query is made against the Lambda architecture, organizations obtain results by merging analysis from both the batch view and the real-time -- speed -- view. This enables the Lambda architecture to provide a more comprehensive and complete picture of the data than might otherwise be possible.
For the Lambda architecture to work, it must have very low latency and be scalable enough to accommodate the inbound data stream. As such, the Lambda architecture is designed to be scaled out across multiple nodes, including hyper-converged, for example. This scale-out architecture also allows the system to be fault tolerant against hardware failures.
Custom FPGAs
Custom field-programmable gate arrays (FPGAs) are relatively new to the world of IT, but have been used in electrical engineering for years. Even so, hardware vendors are beginning to use FPGAs as an alternative to CPUs and GPUs in machine learning for data analytics offerings. In fact, Intel spent $16.7 billion to purchase FPGA manufacturer Altera in 2015.
FPGAs have historically been used to bring down the cost and complexity of designing electronic devices. Modern electronic devices are almost always based on the use of integrated circuits (ICs). This means an electronic engineer designing a new device would either need to locate ICs that meet the device's needs or create a custom IC, which is an expensive and complicated process.
In electronic engineering, FPGAs eliminate the need to produce custom ICs. Unlike other types of integrated circuits, an FPGA is programmable. This means an electronic engineer can configure an FPGA to act like a custom-built IC.
It isn't just the FPGA's ability to act as a custom IC that makes it desirable for machine learning. FPGAs have two other characteristics that must be considered:
They can achieve extremely low latency. This is largely attributed to the ability of an FPGA to act as a custom, purpose-built device, rather than a general-purpose device the way a CPU does. In addition, FPGAs are not burdened with having to run a general-purpose OS such as Windows or Linux. Because they can achieve such low latency -- sometimes as low as a single microsecond -- FPGAs lend themselves well to use in AI machine learning platforms.
They can perform floating point computations. Although FPGAs can perform floating point computations, they lack the speed and precision of a modern CPU or GPU, making current-generation FPGAs not a good option for use in AI training. However, they excel in inference tasks. This means a storage vendor can use FPGAs as a platform for integrating machine learning capabilities into storage hardware as long as the initial training data is created on a different platform and then copied to the device.
Training vs. inference
At a high level, machine learning is based around the concepts of training and inference. Training is exactly what it sounds like. It is the process of teaching the machine learning platform how to perform a specific task.
A classic example of the training process is a 2012 experiment in which a computer algorithm was trained to recognize a cat. This experiment underscored the CPU and data-intensive nature of the training process. Learning to recognize a cat required 16,000 computers to collectively parse 10 million cat images. The result was an algorithm that could recognize an image as being either a cat or not a cat.
The other major component to machine learning is inference, which refers to the task a machine learning algorithm performs after the training process is complete. In the case of the previously mentioned cat recognition algorithm, for instance, inference happens when the algorithm looks at a previously unseen image and correctly determines whether or not the image contains a cat based on its past training.
Computationally, inference is far different than training. Whereas the training process is extremely CPU-intensive and usually requires analyzing vast amounts of data, inference is based solely on knowledge accumulated in the training process. It therefore happens much more quickly, and with considerably less effort, than training.
Containerized storage
Although best known as a platform for running business applications, containers are also viable for machine learning.
The process of training a machine learning algorithm tends to be computationally intensive. Once trained, however, enterprises can often use such algorithms without needing significant CPU resources. Because machine learning processes tend to be relatively lightweight, they are increasingly being run within containers. An example of a machine learning technology that is most often containerized is TensorFlow.
TensorFlow is an open source Python library from Google designed to make machine learning easier. Google has created its own custom IC, the Tensor Processing Unit, designed for use with Tensor. However, Google designed TensorFlow to work on nearly any platform, including containers.
One of the most compelling reasons for containerizing TensorFlow is its applications can be run at scale. Organizations can distribute computational graphs across TensorFlow clusters and can containerize the servers that make up these clusters.
Vendor support
One of the first storage products to incorporate machine learning for data analytics capabilities is the Dell EMC PowerMax family. Dell EMC advertises PowerMax as being the world's fastest storage array because it supports up to 10 million IOPS and allows for 150 GBps of bandwidth.
PowerMax arrays owe their impressive performance, at least in part, to machine learning. The integrated machine learning engine automatically uses predictive analytics to maximize performance by placing data onto the optimal media type -- flash or storage class memory -- based on the anticipated demand for that data.
Organizations wishing to use the power of machine learning for storage should begin by deciding what it is they hope to gain.
Dell EMC is not the only vendor to use machine learning to make storage more intelligent. Hewlett Packard Enterprise (HPE) uses machine learning for data analytics to bring intelligence to hybrid cloud storage.
Hybrid cloud environments typically include storage within an organization's own data center and within multiple public clouds. It has historically been up to the IT department to examine how data is used, where it is stored and to identify inefficiencies. HPE's Intelligent Storage technology analyzes workloads to understand the underlying requirements and then relocates data to the optimal location based on metrics like storage cost, performance, proximity to where the data is being used and available capacity. The Intelligent Storage offering also adapts to changing conditions in real time and relocates data on an as-needed basis.
What do you hope to accomplish?
Organizations wishing to use the power of machine learning for storage should begin by deciding what it is they hope to gain. Once those needs have been identified, they can look for products that directly address those requirements. If your main goal is to optimize performance, for example, you would want to look for machine learning for data analytics-based products that automatically arrange data in a way that minimizes latency and seeks to avoid wasted IOPS.
Depending on the needs identified, an organization might not necessarily have to purchase storage hardware to take advantage of machine learning. A software application could conceivably handle a task such as automated capacity planning, for instance, rather than requiring new storage hardware.