From perceptron to Concert: The operations data model at IBM Think '26
IBM positions Concert as a graph-driven operations platform that combines observability, policy, risk and AI agents into a shared enterprise context layer.
“Stories about the creation of machines having human qualities have long been a fascinating province in the realm of science fiction. Yet we are now about to witness the birth of such a machine, a machine capable of perceiving, recognizing, and identifying its surroundings without any human training or control,” writes Frank Rosenblatt in his groundbreaking article "The Design of an Intelligent Automaton".
Rosenblatt’s article was not published in 2026 or even in the 2000s. Cornell Aeronautical Laboratory included his piece in its Research Trends magazine in the summer of 1958, and the first software simulation of his perceptron ran on an IBM 704 at Cornell that same year.
Seventy years later, every frontier LLM does what Rosenblatt described. Perception without supervision is no longer the interesting question. The interesting question is what to do with a perception layer that has no enterprise context, and that is the question Arvind Krishna, IBM’s CEO, spent his Think 2026 keynote answering. His message, as per the title of the opening keynote: Win the enterprise AI race or be left behind.
Coming from IBM, this line sounds far less radical or aggressively bullish than the taglines from OpenAI, Grok or Anthropic. That group of unicorn startups has all its eggs in the LLM basket and feels the pressure of hundreds of billions of dollars in CapEx for data centers and hardware infrastructure to ultimately capitalize on their intellectual property.
Front page of Frank Rosenblatt's groundbreaking article introducing the perceptron.
For IBM, today’s version of AI happens to be based on agents using LLMs and any number of tools to autonomously complete tasks. But in this story, neither agents nor LLMs are the real stars. They are important enablers. Therefore, instead of sinking its cash into developing the best-performing frontier model, Big Blue focuses on making data-driven decision-making and intelligent automation accessible at scale. “Model layers are going to keep changing. We need to make sure that the architecture lasts,” said Krishna.
Enterprise AI is won at the orchestration, data and operations layers, not at the model layer itself.
He acknowledges that the model is a moving target and explicitly positions IBM as committed to helping enterprises leverage AI progress for their business. Enterprise AI is won at the orchestration, data and operations layers, not at the model layer itself. Given how close the performance benchmarks are across the major LLM vendors and IBM’s deep reach into the enterprise, this approach makes intuitive sense.
Concert: One unified operations data model for resilience at scale
Omdia research identifies the foundational challenge preventing AI from taking action. It's the inability to actually feed AI with the contextualized data it needs to make the best possible decision and then automatically execute the solution.
For example, 69% of enterprises are running six or more observability platforms and 30% even run 11 or more. Yet 61% use less than a third of their operations data to optimize operations and achieve resilience. As a result, over 46% continuously override the recommendations from their observability platforms.
Concert plays on a unified data model
IBM positions the Concert platform as much more than a rebranding and basic integration of its acquisitions and internal developments within its intelligent automation business unit. Instead of simply making the products ‘talk’ via API and then giving them a unified user interface, IBM went much deeper:
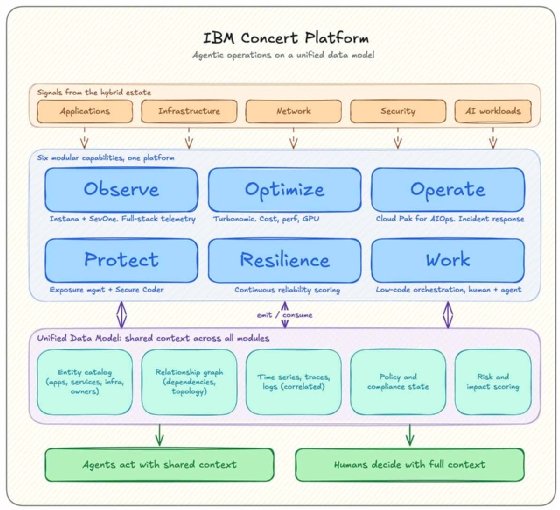
IBM Concert consists of six modules communicating with a comprehensive unified data model
All Concert platform modules -- Observe, Optimize, Operate, Protect, Resilience, Work -- now have access to a unified data model, consisting of an entity catalog, relationship graph, time series store, policy state and risk impact scoring layer. This means that all these modules share a common context. Here's a breakdown of each component of the unified data model:
The entity catalog
This is the inventory of every running thing in the enterprise, modeled as discrete entities with owners attached. Applications, microservices, databases, containers, hosts, network devices, and the people and teams responsible for each. This lets the system answer "who owns this service" without anyone having to grep through a wiki.
The relationship graph
This is the wiring diagram between those entities. It tracks dependencies, topology and reach, so a single incident in a payment service can be evaluated against the 10 downstream consumers it affects. This is also the basis for calculating the blast radius of an incident or planned system changes.
Correlated time series, traces and logs
These are the temporal layer. Raw operational signals from across the organization’s hybrid environment get stitched together by entity and by time, so a memory spike, a log line and a distributed trace become three views of the same event rather than three separate puzzles in three different tools.
Policy and compliance state
This holds the rules -- codified policies, change windows, approval requirements, regulatory obligations and the current compliance posture of each entity. This lets the platform answer "am I allowed to apply this remediation right now under the active change freeze” without a human reading procurement documents.
Risk and impact scoring
This is the business-meaning layer. Quantified scores attached to entities, incidents and proposed actions, capturing what is actually exposed, what revenue depends on it and what a given fix changes in terms of resilience. This tells an agent which of 10 findings is the one that matters today, and what tells a code reviewer in seconds whether to merge the pull request Bob (IBM’s SDLC agent) just opened.
Example: The power of the graph
Consider this example of the transformative character of graph-based operations: A payment service starts throwing alerts at the start of the busy evening shopping period each day. Here is how this issue would have been addressed before graph-driven operations.
The SRE receives the alert and hunts down the application owner.
Developers dig through piles of logs, suspecting the database as the issue and paging the DBA.
The DBA finds query lock contention but does not know where it comes from.
Now someone has to figure out whether a recent deployment caused the issue, what the blast radius looks like across dependent services and how to triage against already open incidents.
Tracing the deployment chain, the team must choose between a rollback and a hotfix while the retail window continues to bleed revenue.
The on-call SRE lacks authority to roll back during the change freeze, so the on-call manager joins the bridge, with engineering leadership and someone from product following over the next twenty minutes.
Customer support starts taking complaints about checkout failures, and the on-call manager has to draft a status page update while paging the upstream service owner to warn them.
After roughly 45 minutes on the bridge, the team agrees on a rollback. The change still requires CAB approval inside the evening window, which adds another delay.
The rollback executes, payment metrics stabilize and the SRE finally marks the incident resolved a little over 90 minutes after the first alert fired.
A postmortem the following week identifies the actual root cause, an unbounded cache combined with a Db2 index that no longer fit the new query pattern, and the permanent fix lands in the backlog where it competes with feature work.
Below is how IBM promises its Concert platform could address this same issue:
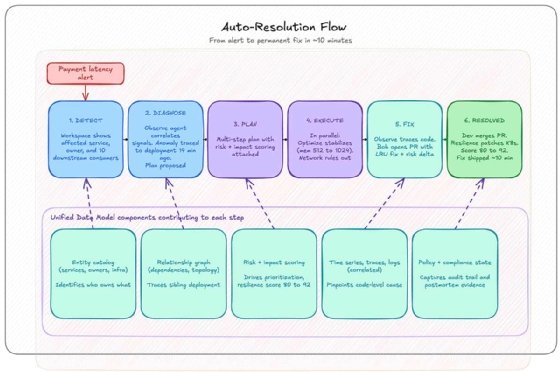
Resolving an issue in six mostly automated steps
Concert detects the latency anomaly and drops the SRE into a workspace that already shows the affected service, its owning team and the 10 downstream consumers pulled from the entity catalog and relationship graph.
The Observe agent correlates time series, traces and logs, pinpointing the anomaly as starting fourteen minutes after a deployment to a sibling service. No log digging, no DBA paging.
Concert proposes a multi-step remediation plan with risk-and-impact scoring attached, so the SRE can see which actions move the customer-impact needle.
The plan executes in a single coordinated pass. After the SRE approves, the Optimize agent bumps container memory from 512 to 1024 megabytes to stabilize the service. The network anomaly agent runs in parallel and rules out the network.
The Observe agent traces through the GitHub MCP to find the unbounded cache, and the Bob coding agent opens a pull request with an LRU eviction fix and the resilience and risk-impact delta in the description.
The developer code owner reviews the PR in Slack with full incident context already attached, approves, and merges. The resilience coordinator then re-evaluates the service, patches missing Kubernetes memory limits, and moves the resilience score from 80 to 92.
The incident closes inside Concert with a complete audit trail. The permanent fix has shipped, and elapsed time is closer to 10 minutes than the 90 minutes it would have taken before. The postmortem evidence is already captured in the policy and compliance state, which means there is no meeting next week to debate what happened, and no permanent fix sitting in the backlog waiting to be deprioritized.
Conclusion
In Concert, the unified data model is the real protagonist. IBM rightfully recognizes that even the most intelligent AI agents with access to the latest frontier models cannot compensate for the absence of context. However, AI agents with access to contextualized operations data are the real deal, as the deterministic connections and dependencies recorded in the graph compensate for the probabilistic character of LLMs.
Even the most intelligent AI agents with access to the latest frontier models cannot compensate for the absence of context.
For example, when the Payment latency alert fires during the evening retail peak, an LLM on its own might confidently suggest restarting the Payment pod because that is the canonical fix for memory-bound services in its training data, while the relationship graph immediately tells the agent that Payment shares a Redis cache with Cart and Auth. Every in-flight checkout session would then be invalidated the moment the pod cycles, turning a latency spike into a measurable cart-abandonment event during the highest-revenue hour of the day.
So how significant is IBM Concert for Big Blue and its customers? IBM has architected Concert in a modular fashion to enable a peaceful coexistence with existing enterprise environments.
That modularity is doing real work and it cuts both ways across the brownfield. Customers already running Instana, SevOne, Turbonomic or Cloud Pak for AIOps can turn on a single Concert module and start seeing value inside a quarter without committing to the rest of the platform. Customers running Datadog, Splunk, Dynatrace, or New Relic for telemetry, and ServiceNow for ticketing and change management, can wire Concert in through its MCP and connector layer without ripping any of those tools out.
The unified data model is engineered as an index that sits alongside the existing stack rather than as a replacement for it, which is the only way a platform play has a chance of landing in real enterprise environments where the ops tooling was bought, deployed and integrated three different ways across the last decade. Partial Concert is real on both axes.
The catch is that none of those single-module or mixed-stack deployments delivers the architectural payoff Krishna spent the keynote selling. The unified data model only earns its keep when multiple modules are emitting signals into and consuming from the same shared layer, and the agentic resolution loop only closes when at least three of the six modules are in production together, regardless of which third-party tools sit beside them. Getting there is the project most enterprises will spend the next 18-24 months on. The heavy work sits in the entity catalog, the policy and compliance state, and the risk-and-impact scoring rather than in any of the Concert modules or third-party connectors themselves.
The heavy work sits in the entity catalog, the policy and compliance state, and the risk-and-impact scoring rather than in any of the Concert modules or third-party connectors themselves.
Customers with a mature CMDB, a developer portal like Backstage and machine-readable policy already in place can stand up a useful Concert deployment in a quarter or two whether they are on the IBM stack or running Datadog and ServiceNow. Customers without those primitives are looking at a multi-quarter data hygiene exercise that no platform vendor can shortcut.
Concert fits cleanly into both IBM-heavy environments and mixed-vendor stacks where partial adoption already delivers value on day one, but the full architectural promise depends on a data model project that IBM has correctly identified as essential and that no vendor, including ServiceNow, Datadog, Dynatrace, or Atlassian, can hand a customer off the shelf.
Whether Concert ends up being the operating layer of the agentic enterprise or just a strong portfolio rebrand will be decided in the next 18 months, based on how many customers actually commit to the data work it requires. IBM has bet that enough of them will. The history of platform plays in this industry suggests that bet is right about half the time, and the half it gets right tends to define the next decade.
Torsten Volk is principal analyst at Omdia covering application modernization, cloud-native applications, DevOps, hybrid cloud and observability. Omdia is a division of Informa TechTarget. Its analysts have business relationships with technology vendors.