GenAI and synthetic data: What can go wrong in business?
GenAI's ability to improve everything it touches, including synthetic data, is undeniable, but when misused, simulated data can amplify bias, taint data and compromise security.

Generative AI has spawned a powerful new era of synthetic data. Businesses can now use GenAI to create data sets that mimic the characteristics and features of real-world data without revealing sensitive or personally identifiable information. Synthetic data is a major benefit for machine learning models that lack sufficient real data and for situations when real data demands an additional level of protection before being shared with third parties.
Synthetic data does have a dark side, however. Simulated data is dangerously close to "fake" data, and the issue isn't just about semantics. The purpose of synthetic data is to create data that's indistinguishable from real data -- at least from a statistical standpoint. But the ease and speed of synthetic data generation often erode vital data validation and governance practices. In the wrong hands, synthetic data can slip past an organization's automated checks and filters, and become a mechanism for attack, fraud and other misuse that puts a business at risk.
Synthetic data misuse in business
In general terms, synthetic data misuse can occur anytime artificially generated data is used inappropriately. Consider these four areas of potential misuse:
- Inaccurate use. Synthetic data is more trusted than it should be, or it's treated as real-world data.
- Unrepresentative use. Synthetic data is biased or fails to properly represent an intended purpose.
- Unethical use. Synthetic data is generated with misinformation or deliberately false data intended to mislead, misdirect or deceive.
- Harmful use. Synthetic data is used to attack, steal, commit fraud or deliberately conduct other malicious acts.
Synthetic data misuse is prevalent. A healthcare organization, for example, generates synthetic patient records to support disease research, but inaccurate use of that data fails to capture the detailed relationships between symptoms and outcomes, leading to faulty treatment recommendations. Or a financial institution uses synthetic credit data to train loan models, but the synthetic data reinforces bias or prejudices contained in the original real-world data, and the organization wrongfully denies credit.
This article is part of
What is GenAI? Generative AI explained
Businesses need to validate synthetic data and establish data governance practices that address and mitigate misuse.
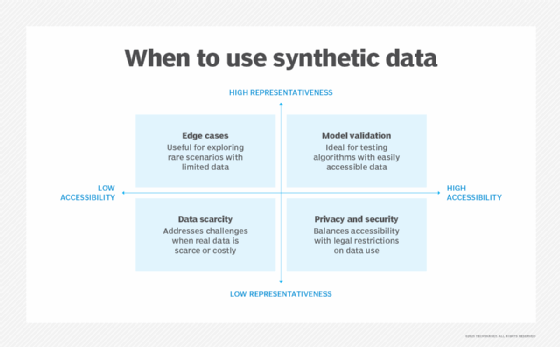
Causes of synthetic data misuse
Although synthetic data misuse is often seen as a deliberate or malicious act, most cases are accidental due to a combination of over-reliance on automated tools, limitations of data generation technologies, lack of attention to synthetic data risks and lapses in data governance.
Malicious acts
GenAI has no moral compass. In the wrong hands, it can create artificial data that can be used to mislead, misinform, defraud, steal and attack. The creation of AI deepfakes, fake evidence and other "untrue" content is nothing new, but businesses still struggle to balance the fair use of AI platforms against moral and legal guardrails.
Any business that gathers and uses data as part of its normal customer interactions faces increasingly sophisticated attacks that use synthetic data to establish fake accounts. Synthetic identity theft is an emerging trend. Businesses must recognize these growing risks and establish strong validation mechanisms to locate and mitigate fake data.
Model overfitting
GenAI models are intended to learn from real data and create data that's different from the training data. Overfitting occurs when a model is trained so close to the training data that it can't identify anything but the training data and basically replicates the real data. If, for example, every picture of an apple used to train a model looks exactly alike, the model will only be able to "see" an apple from that angle, lighting and visual characteristics.
Overfitting GenAI models can be a serious problem when synthetic data is created to anonymize or shield personally identifiable information (PII) or when the synthetic data is needed to flesh out limited or niche data sets. The inability of a GenAI model to produce unique and diverse data can lead to security vulnerabilities, such as the reverse engineering of data. It can also reinforce data limitations, such as amplifying bias, or cause model degradation if the poor-quality synthetic data is reused for further training.
Weak data governance
Even though the data used to train a model is valid and trustworthy, the synthetic data generated by that model is not. Assuming that synthetic data is a substitute for real data is reckless and carries enormous data governance risks for businesses.
A synthetic data set demands the same scrutiny that data science teams apply to real-world data. Proper validation ensures synthetic data provides integrity, statistical validity, error detection and correction, bias detection and mitigation, as well as the ability to handle edge cases and complex relationships.
Synthetic identity theft on the rise
Synthetic identity theft is a type of financial fraud in which a real individual's social security number is stolen and combined with synthetic data such as name, date of birth, address and contact information. A new identity is then created for an individual who doesn't exist -- a process known as identity compilation.
Alternatively, a malicious actor might obtain an individual's PII and alter the personal data to create a different identity -- a process called identity manipulation. Another tactic called identity fabrication could be used to create an entirely new identity using false PII. Once created, a synthetic identity is typically used for financial fraud related to bank accounts, loans and credit cards. In many cases, synthetic identity theft is termed a long con when the fake identity is used for years to build a full and legitimate profile, such as a credit history, before the fraud is executed.
Synthetic data can appear to be so complete and valid that it's indistinguishable from real data. Businesses accepting a mortgage application, for example, can't readily detect fraud through traditional monitoring.
Risks of synthetic data misuse
Synthetic data can be misused internally or externally and carry significant risks for businesses, such as reputational damage, compliance violations, security vulnerabilities and model degradation. Common risks include the following:
- Bias reinforcement. Bias is present in virtually all data even when completely benign or unintentional. Every data set is finite and can't guarantee balanced representation. When data is used to create synthetic data, the bias is reflected and often amplified in the synthetic data output, tainting other models and AI systems trained on the same synthetic data.
- Data contamination. Synthetic data is so easily and quickly created that it's often the de facto foundation for model testing and validation and wrongly assumed to carry the same integrity and validity of real data. When synthetic data is casually comingled with real data, there's potential for model collapse -- a degradation in output accuracy when the model loses touch with the nuances found in real data.
- Re-identification. Synthetic data can be reverse engineered to reveal some of the underlying real data. Overfitted models, for example, might be unable to generate truly unique data, enabling real and potentially sensitive data to leak into the synthetic data set and cause privacy violations. Attackers can then correlate synthetic data to real individuals, further compromising PII and exposing an organization to compliance violations.
- Misinformation. Synthetic data can generate false, misleading or malicious data, such as deepfakes, which can be used to defraud, harass or harm individuals and businesses. As GenAI platforms improve their output fidelity and detail, it's almost impossible to discern fake content. Fake data assumed to be real can comingle with real data to skew future AI output.
- Lost reliability. Machine learning models can recognize deep cause-and-effect relationships between data variables. Synthetic data can recreate overall correlations in data, but it can't replicate the deep cause-and-effect nuances of the data. Consequently, synthetic data can pose reliability problems that are potentially dangerous for mission-critical tasks such as healthcare diagnostics.
- Real-world vulnerabilities. Models trained on real data can spot real-world noise such as outliers or erroneous data. But synthetic data tends to be well curated and preprocessed, so models trained on synthetic data might not learn to recognize and respond to real-world noise, opening the door to unpredictable model behavior or malicious attacks.

How to avoid synthetic data misuse
Business and technology leaders should follow several guidelines to mitigate misuse, including the following:
- Don't replace real-world data. Synthetic data has proven effective when used as a supplement to real-world data or when testing model performance, but it should never be a complete replacement for real-world data. When data is synthesized for security purposes, it should be tested to ensure that original details can't be reverse-engineered. Data anonymization methods can be used instead of or in addition to synthetic data.
- Validate synthetic data. Data that's synthesized from valid data doesn't guarantee the synthetic output has the same integrity. Synthetic data should be validated just like real-world data to ensure the synthetic content maintains data quality standards.
- Document synthetic data. The creation and use of synthetic data should meet an organization's data governance requirements. Careful documentation records factors such as why the synthetic data was created, where it was obtained, how it was tested and validated, and how it was used. Comprehensive documentation helps businesses meet compliance requirements and guide discovery in the event of model-related litigation.
- Monitor GenAI model output. Businesses should monitor the GenAI model's output performance and ensure adequate review and validation before delivering synthetic data to the user. Monitoring also ensures adherence to the limitations outlined in the terms of service, such as no false, misleading or harassing content.
- Perform reasonable due diligence on all submitted data. Businesses should implement safeguards to authenticate data submissions and stop attacks such as synthetic identity theft.
Stephen J. Bigelow, senior technology editor at TechTarget, has more than 30 years of technical writing experience in the PC and technology industry.
Dig Deeper on AI business strategies
-
![]()
Improving business forecasting with synthetic data and simulation modeling
By: Kashyap Kompella
-
![]()
What to know about synthetic data as a business advantage
By: Stephen Bigelow
-
![]()
AI slop: The hidden enterprise risk CIOs can't ignore
By: Sean Kerner
-
![]()
Using simulation forecasting in business analytics
By: Jacob Roundy



