
KOHb - Getty Images
What to know about synthetic data as a business advantage
Synthetic data mimics real data without sensitive information. It offers cost-effective options and competitive advantages for AI training, software testing and data monetization.

Data has become the single most important resource for modern business. It's created by sensors, product functions and many customer actions. It's analyzed extensively, forming the foundation of real-time business decisions. It can teach machine learning (ML) models to help AI systems learn and adapt to changing situations. Data can even be monetized, yielding other revenue streams for enterprises that understand the value of data.
But data also presents vulnerabilities for business. Oversight and security are needed to restrict access, implement data sovereignty and ensure that sensitive or personally identifiable information (PII) contained within is protected. Data can have quality issues that result in it being biased, limited, incomplete or inconsistent. It also can be costly to collect, especially when data sets are small or specific to an industry or use case.
Synthetic data is one way organizations are overcoming some of these data challenges. Synthetic data isn't real data. Algorithms and generative AI (GenAI) are used to create data sets that reflect the characteristics and patterns found in real data, but they contain no actual sensitive data or PII. Given this, synthetic data can replace real data, addressing the cost, localization, security, privacy and quality concerns that surround real data.
Because of these advantages, synthetic data use is on the upswing. In its "What generative AI means for business" report, Gartner predicted that 75% of businesses will use GenAI to create synthetic customer data by 2026. This is an increase from less than 5% in 2023.
How synthetic data works
At its most basic, synthetic data is artificially generated data that mimics real-world data. It can be created algorithmically, or by first training a GenAI or other platform with real data on which the artificial data can be based. Although synthetic data is artificial, it retains the statistical characteristics of the real data used as its foundation, but it doesn't possess any of the sensitive or personal information found in real data. And that's what makes synthetic data useful and appealing: It provides business value while mitigating much of the associated risk in using real data.
Consider this example: A financial company is developing software to underwrite mortgages, but the application needs to be trained and tested extensively to validate its capabilities. The company could use data from real mortgage applicants, but this carries costs and data privacy, security and quality risks. It might not even be possible to obtain an adequate data set at a reasonable cost. By using synthetic data, the company can cost-effectively acquire the needed data without the issues and obligations of real data.
In these situations, businesses can use one of the following three approaches to synthetic data:
- Full data synthesis. As the name implies, this approach doesn't contain any real-world data. The entire data set is generated using patterns and relationships that produce an emulated data set.
- Partial data synthesis. This approach is a mix of real and synthetic data. Some elements of real-world data are retained, but sensitive data elements -- such as PII -- are replaced with synthetic data or additional data elements can be added. The ability to add data elements is useful when data sets must be augmented to include data that hasn't been collected from the real-world.
- Hybrid data synthesis. Here, a data set mixes real and synthetic records. This approach expands a data set and can be useful when real-world data sets are too small or limited in scope to be useful alone.
How synthetic data is created
There are numerous techniques available to create synthetic data. The following are some common methods:
- Statistical algorithms. When data uses well-understood distributions or correlations, it's a simple matter to use statistical algorithms to create synthetic data. For example, interpolation can determine new data points between existing ones, while extrapolation can create new data points beyond existing ones.
- AI agents. Increasingly used to model complex systems, AI agents interact with one another in ways similar to real-world behaviors. When built and tuned properly, AI agents can generate data that closely resembles real-world data. This approach is a powerful research tool. For example, infectious disease scientists can use AI agents to synthesize data that resembles the spread of a disease and examine the roles of possible vaccination or other interventions.
- Generative adversarial networks. GANs use two networks that compete to produce or modify data in ways that make it impossible to differentiate between real and synthetic data. For example, a generator network creates synthetic data, and a discriminator is the adversary that tells real versus synthetic data. The discriminator feeds back to the generator, creating a loop that can build data that resembles real data.
- Transformers. These models are the basis of small and large language models used in AI and GenAI. Transformer models use encoders and decoders to break down and manipulate data in ways that capture the semantic meaning of data and then generate the most statistically likely outcome. This works for understanding the meaning and context of language, and it can be applied to generating artificial text and other types of synthetic data.
- Variational autoencoders. VAEs are GenAI models intended to produce variations of data used to train the model. Similar to transformers, VAEs use encoders to compress data into less space while capturing meaningful information. Decoders are used to construct new data from the encoded foundation data.
Various tools and platforms exist to produce synthetic data. The following is a sampling of tools:
- The Mostly AI platform is used in finance and insurance.
- Nvidia's Gretel.ai offers APIs to generate, classify and transform synthetic data.
- Synthea generates synthetic healthcare records.
- Tonic is used for realistic test data.
- YData is used for high-quality synthetic data sets.
Uses of synthetic data
Synthetic data has a range of potential uses across industry verticals, such as the following examples.
Machine learning and AI training
ML models and AI systems depend on enormous amounts of high-quality data for training. Synthetic data can help fill the demand for this high-quality training data, especially in cases where the data is limited, proprietary or costly to obtain. For example, synthetic data is useful for the simulation of rare events -- such as a network attack or fraudulent financial behavior -- where real-world data is particularly limited.
Organizations that use synthetic data for ML and AI can develop models and systems that perform better and behave more predictably in unusual cases than organizations that depend solely on real-world data.
Software development
Testing is a central part of the software development lifecycle, and this demands test data that ensures a build's functionality across a range of input conditions. Synthesized data can meet these demands, creating test data for varies situations while safeguarding real data.
Businesses that use synthetic data for software development typically realize better, faster and more consistent testing regimens than those that use manual test scenarios or only real-world data. Broader and more comprehensive synthetic data can help expose more software defects earlier, resulting in a more reliable and trustworthy software release.
Data security
As regulatory and sovereignty demands expand globally and across industries, the need to safeguard data privacy and security poses increasing risks for businesses. Organizations are less likely to share real-world data for fear of compliance issues, breaches and corresponding business consequences. Synthesized data can generate data that's partially or completely synthetic, enabling simulations and data use while mitigating business risks.
Organizations that integrate synthetic data into their data privacy and security environment are more resilient to data breaches, lowering the chances of litigation, fines and sanctions because no PII need be present in the synthetic data. However, synthetic data can still have business value and should be subject to reasonable security methodologies.
Data augmentation and bias mitigation
Synthetic data can be generated to expand existing data or create entirely new data sets that support more diversity and additional data parameters. This enhances the performance, fairness and accuracy of AI systems.
Businesses that use synthetic data for augmentation can realize faster data preparation, making the augmented data ready for use faster than manually adding or recapturing additional data. Bias mitigation can ensure acceptance of the AI when bias reduction is required by law. Similarly, bias mitigation is emerging as an AI business differentiator, and synthetic data can result in better user or customer outcomes, building a meaningful AI reputation and brand.
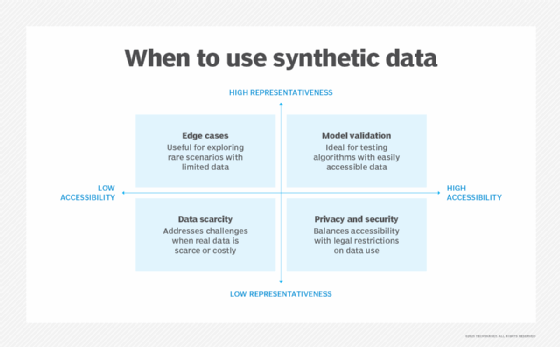
Monetization of synthetic data
Data monetization is the practice of translating business data into measurable business value. While real-world data is increasingly monetized, the emergence of quality synthetic data also provides monetization opportunities. The financial appeal of synthetic data arises from the following three areas:
- Synthetic data privacy. Real data frequently contains PII and other sensitive business data that carries the risk of data misuse, leading to regulatory violations and penalties. Real data could be anonymized before it's monetized, but this requires additional processing and costs. Synthetic data is anonymous by default and eliminates the risks of managing sensitive or personal data.
- Synthetic data availability. Synthetic data can be generated quickly and in vast quantities, often on demand. At the same time, it can effectively address bias or other data quality issues. This makes synthetic data appealing when real data is scarce, of limited quality, or when rapid training or prototyping is required.
- Synthetic data cost. Real-world data can be expensive and time consuming to collect, process and anonymize. This makes real data highly proprietary and valuable, potentially making the data too important to monetize directly. Synthetic data can be created quickly and relatively inexpensively. This can yield data that provides value but is far more affordable for potential buyers.
Synthetic data can be monetized to yield direct and indirect business benefits, such as the following:
- Direct monetization. The selling or licensing of synthetic data to academic researchers, AI startups and any business that can't readily generate time- and cost-effective data internally are examples of direct monetization. Synthetic data can be pre-existing -- already generated to serve the original enterprise -- or it can sometimes be generated on demand in response to buyer queries.
- Training and consulting. Organizations that refine their mastery of synthetic data might be able to couple direct monetization with additional revenue-generating services such as synthetic data training and consulting. This lets the organization bolster sales and licensing of its synthetic data with practical services that can aid other businesses in selecting, using and generating synthetic data.
- Indirect monetization. Using synthetic data to enhance or improve internal operations is a form of indirect monetization. For example, synthetic data that represents potential fraudulent financial transactions can be used to train AI platforms for superior fraud detection capabilities. Similarly, synthetic data that reflects wear and tear on vehicles can enhance AI training for predictive maintenance across logistics fleets. The business value here isn't direct revenue, but rather value generated through cost savings and product enhancements.
Benefits and challenges of synthetic data
Any enterprise considering a role for synthetic data must consider the tradeoffs involved. This includes the following benefits of synthetic data:
- Data privacy. With no PII, synthetic data eliminates the risks associated with data breaches and data sovereignty.
- Data volume. Synthetic data can be produced in enormous quantities -- often on demand.
- Data annotation. Synthetic data can be generated with desired annotations, such as tagging and labeling, eliminating the need for manual tagging.
- Bias reduction and model performance. Synthetic data can provide a broader scope of data which is more representative and inclusive, resulting in fairer data and outcomes. Broader data conditions can also reduce overfitting and enhance overall model performance.
- Unique or rare data. Synthetic data can represent rare or potentially dangerous conditions, such as a cyberattack, that are difficult to capture in the real world.
- Cost. Generating synthetic data can be cheaper and faster than collecting real data. This can vastly accelerate prototyping and AI training.
Despite the benefits, however, there are numerous challenges with synthetic data that business leaders must understand and address, including the following:
- Poor data quality. Synthetic data must follow real data patterns. Less accurate models result when it doesn't. Similarly, synthetic data that fails to capture the nuances typically found in real data can limit the model's ability to learn.
- Validation. Simply generating synthetic data is no guarantee of its usefulness or reliability. Organizations must be able to validate that the synthetic data offers a worthwhile replacement to real data.
- Bias amplification. Synthetic data can reduce bias, but when generated improperly, it can worsen or amplify bias. Synthesized data should be inspected and evaluated carefully for bias, even when all efforts are made to reduce bias.
- Generation complexity. Synthetic data doesn't just appear; it must be deliberately generated using complex methods that use a wealth of real data as the foundation. The sophistication required to create meaningful synthetic data can be difficult and costly to implement.
- Use case limitations. Synthetic data can be broadly applicable but might not be suitable for every use case, such as mission-critical or regulatory-dependent production systems. Consider whether synthetic data is appropriate for each use case and determine whether partial or hybrid data synthesis might yield better outcomes.
Responsible governance is the future of synthetic data
The role of synthetic data is expanding rapidly. It's no longer an experimental tool but is becoming a foundation for innovation. Companies like Waymo, an autonomous vehicle technology developer, can simulate entire urban areas for vehicle testing. Healthcare organizations can test treatments or track health concerns at enormous scale without risking patients' medical records. These practical uses will drive the evolution and use of synthetic data into the future.
However, the production and use of synthetic data will need to address societal consequences arising from the authenticity and trustworthiness of the data. For instance, what happens when people no longer believe what they see, hear and read? These issues will demand attention to governance and transparency, encouraging lawmakers and business leaders to foster proper use of synthetic data while enabling businesses and people to readily distinguish between real and synthetic data.
Stephen J. Bigelow, senior technology editor at TechTarget, has more than 30 years of technical writing experience in the PC and technology industry.
Dig Deeper on AI technologies
-
![]()
GenAI and synthetic data: What can go wrong in business?
By: Stephen Bigelow
-
![]()
Improving business forecasting with synthetic data and simulation modeling
By: Kashyap Kompella
-
![]()
AI governance can make or break data monetization
By: Stephen Bigelow
-
![]()
Synthetic data vs. real data for predictive analytics
By: Donald Farmer



