Free DownloadWhat is data management and why is it important? Full guide
Data management is the process of ingesting, storing, organizing and maintaining the data created and collected by an organization. This comprehensive guide to data management further explains what it is and provides insight on its individual disciplines, best practices, challenges that organizations face and the business benefits of a successful data management strategy. You'll also find an overview of data management tools and techniques. Throughout the guide, hyperlinks point to related articles that provide more information and offer expert advice on managing data.
Best practices and pitfalls of the data pipeline process
Developing an effective data pipeline process is a key step for organizations to manage data sources, flow and quality. A data pipeline also ensures approved data access.
Data is sometimes characterized as the new oil but getting to that oil requires building a data pipeline process to continuously adapt to new sources, requirements and opportunities.
There are many sources of data that organizations can pull from today -- public documents, unstructured text, warehouses, cloud warehouses and data lakes. Teams need to connect the dots with new opportunities spanning traditional BI, predictive analytics, and new AI and machine learning models. It is essential to ensure compliance at each step with a growing array of new regulatory and business requirements.
"A data pipeline process is essential to organizations as they create and build microservices that are dependent on the same data sources across products and platforms," said Kathy Rudy, chief data and analytics officer at advisory firm ISG.
Without a process for moving data between applications, there is a risk of using inconsistent or out-of-date data. A data pipeline also drives efficiency on the development team, allowing developers to use data generated in one system across multiple applications or use cases. For example, a client name generated in an ERP system may also be used by marketing, sales management and events teams.
"Proper initial setup will ensure consistent use across various platforms," Rudy said.
Plus, data systems are complex, with a very high rate of data proliferation that outstrips compute capacity to collect, analyze and synthesize responsively. A data pipeline helps organizations manage these systems and extract accurate data.
"Modern data pipelines are essential for their ability to manage data flows and ensure data quality while unlocking use cases such as data enrichment and data visualization," said Alexander Wurm, senior analyst at Nucleus Research.
The need for modern data pipelines becomes increasingly relevant as an organization expands its network of data sources and data consumers. Examples include large conglomerates and organizations with IoT or edge networks.
Enterprises should take a holistic approach to modernizing data pipelines rather than focusing on individual components, Wurm said. More than 70% of new cloud data warehouse implementations occur alongside the adoption of a new integration platform, according to Nucleus Research.
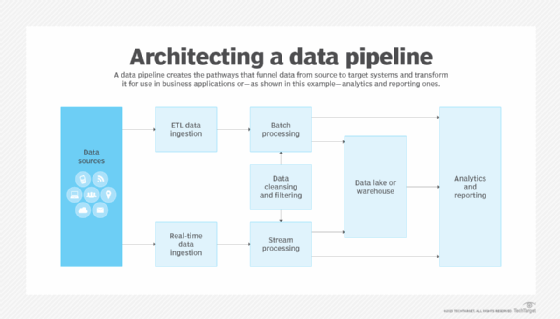
Data pipelines funnel a wide variety of data sources into business operations
Building the data pipeline
Shruti Thaker, global data manager at J O Hambro Capital Management, has built data pipelines at various financial firms for more than 10 years. A data pipeline process is critical for regulating data consumption, both from a fiscal and compliance standpoint, she said. She also finds that a data pipeline is the only way to truly democratize data in the organization.
"Having a robust pipeline process includes the sourcing of the data, ensuring that your company doesn't end up paying multiple times for the same data in different pockets of your organization," Thaker said.
On the compliance side, a data pipeline process ensures that only the people approved to access the data are accessing it and that this is an auditable process.
Here are some best practices for building out a data pipeline process:
Treat the data pipeline as a project
Treating a data pipeline as a project is essential, much like software development, Thaker said. Similarly, data project managers should work with end users to determine what they want from the data, what they will use it for and what sort of answers they expect from the data. It is important to include data engineers as a crucial part of this data pipeline process.
"Use people who understand data flow and context of data movement, rather than app coders or people who know a certain tool," Thaker said.
Assess requirements
Data engineering teams also need to consider various technical, legal and business aspects of the data set that need to be architected, Rudy said. Consider the data sources, types, volumes, quality, growth and rights.
Questions to explore include:
Does it need to go through a cleansing and transformation process?
Where will the data be used?
What is the format required for each process?
Where will the data be stored? On premises or in the cloud?
"Only after you have the answers to these questions should you start building the data pipeline," Rudy said.
Configure, not code
One approach to reduce coding is to adopt an ontology-driven data pipeline process. The ontology helps enforce a consistent data schema across the organization. In this approach, coding is limited to high complexity use cases that the ontology-based pipeline framework cannot handle.
"Manual intervention including coding introduces fragility into data pipelines," said Goutham Belliappa, vice president of data and AI engineering at Capgemini.
Minimize centers of gravity of data
Identify opportunities to consolidate data infrastructure. One Fortune 500 client Belliappa worked with was spending 60% of their data budget to maintain multiple redundant platforms, he said. Removing platform diversity and minimizing the number of enterprise data platforms increased the IT throughput per business dollar spent on data pipelines by more than 300%.
Lack of data is often never the problem in analytics; it's a lack of understanding data.
Yulin ChenFounding engineer, Connectly.ai
Maintain clear data lineage
As applications evolve, the data is bound to change. Fields are added or depreciated all the time, which makes using the data in data processing difficult. Properly labeling tables and columns with sensible descriptions and migration details is paramount.
"Lack of data is often never the problem in analytics; it's a lack of understanding data," said Yulin Chen, founding engineer at Connectly.ai.
Implement checkpoints
It's helpful to capture intermediate results calculated as part of long calculations into checkpoints or tombstones, Chen said. For example, in a function that aggregates order amount by date, the values can be stored into checkpoints once computed and then reused. This also reduces the time to re-execute failed pipelines by targeting re-execution starting from the last failed step. The pipeline should also make it easy to recompute some data when required.
Componentized ingestion pipelines
Data engineering teams can also benefit from building up a rich stable of vetted data processing components. These empower frontline data teams to adapt to changing environments without the need for massive overhauls. It is also important to translate the technical benefits of this approach into business value to maintain support for the initiatives.
"Consider component-based or templated ingestion pipelines to ensure quality, but allow for configuration by the data teams," said Tina Sebert, chief analytics officer at Infostretch, a digital engineering services firm.
Maintain data context
It is essential to keep track of the specific uses and context around data throughout the data pipeline and let each unit define what data quality means for each business concept. Apply and enforce those standards before data enters the pipeline. Then, the pipeline's job is to make sure that data context is maintained as the data flows.
"As soon as a piece of data becomes a row and not a business concept, it becomes irrelevant," said Tyler Russell, chief architect at Claravine, a data integrity platform.
Plan for change
Data pipeline processes frequently deliver data to a data lake where the data typically resides in a text format structure. Updates to individual records in the data lake could easily result in what could be viewed as a duplicate of previously delivered data. It is essential to have logic in place that ensures that data consumption reflects the most up-to-date record in a nonduplicate fashion.
Incorporating logic is also important for managing change data capture, said Craig Kelly, vice president of analytics at Syntax. Change data capture identifies and captures changes in a database then applies it throughout the enterprise.
Pitfalls of the data pipeline process
Teams should be aware of some pitfalls around implementing and refining a data pipeline process. The top pitfall is not fully understanding the downstream user requirements for the data, Rudy said.
"People tend to get deep into the technology and how it will work and forget there are use cases for the data that created the need for the pipeline in the first place," she said.
Start by understanding how data is connected to the organization and how users intend to transform and use the data to achieve their objectives. Using that feedback in the planning process will help prevent unhappy data customers and limit rework and wasted effort for the technology team.
It's common for organizations to underestimate the time to build out the data pipeline process, said Todd Bellemare, senior vice president of strategic solutions at Definitive Healthcare. Project management, engineering and data subject matter experts should work together to improve planning accuracy and recalibrate plans when required, recommended Bellemare. It is also advisable to add additional time for unexpected problems to keep expectations reasonable.
Organizations need to be wary of unrealistic expectations that fail to deliver and kill enthusiasm for building out a data pipeline.
"Often implementations of data pipelines start with their scope being too aggressive and trying to boil the ocean," Kelly said. "It is better to start small with a few data sources and ensure that the process you have in place is sound first, and then build around that."