Data mesh takes a decentralized approach to data management, setting it apart from data lakes and warehouses. Organizations can transition to data mesh with progressive steps.
By
Gunasekaran SGuest Contributor
Published: 31 May 2023
In today's data-driven world, organizations grapple with managing vast amounts of data effectively. The centralized data architectures in place for decades no longer suffice.
Without a well-defined data foundation, business teams and stakeholders struggle to access data for analysis. Data silos, inconsistent data quality management and outdated data governance policies all hinder business intelligence.
Businesses need a more decentralized and federated data management architecture. In a 2022 study by Forrester Consulting, commissioned by financial company Capital One, the vast majority of respondents reported challenges that include difficulties with data integration from multiple sources, managing data for analysis, and a lack of tracking and enforcing adherence to data governing policies.
Data mesh has emerged to overcome these challenges. Data mesh is an organizational approach to building data platforms that emphasizes decentralization and domain-driven data ownership. It enables more flexible and agile data management by breaking down monolithic data systems into smaller, more modular components. Each domain or team is responsible for the quality, availability and governance of its own data.
Although data mesh proposes a new approach to data management, its execution can still be an elaborate process. In this blog, we'll discuss how to create a data mesh architecture that promotes data democratization, self-service and autonomy. Domain-specific data hubs, in our experience, are the foundation of data mesh strategies.
Data mesh principles
There are four key principles of data mesh that business leaders need to understand for a shift toward this decentralized data architecture:
Domain-driven data ownership. Data ownership is based on domain expertise rather than technical expertise. Each team defines its data domain and ensures the data is accurate and up to date.
Self-service data infrastructure. A self-service data infrastructure includes tools and platforms for teams to collect, process and analyze data.
Federated computational governance. A central governing body provides a framework for quality and security, while the responsibility for maintaining those falls within the individual domains. Centralized data governance drives interoperability within the domain, complementing the federated domain-centric work.
Data as a product. Data is not a byproduct of software development but its own product. Treat data with the same care and attention as any other product, focusing on quality, usability and scalability.
Data platform patterns and evolution
Architectures such as data lakes and data warehouses have long been the strategy to store, process and analyze data. However, as the volume and complexity of data continues to grow, the following architectures are starting to show their limitations and drawbacks:
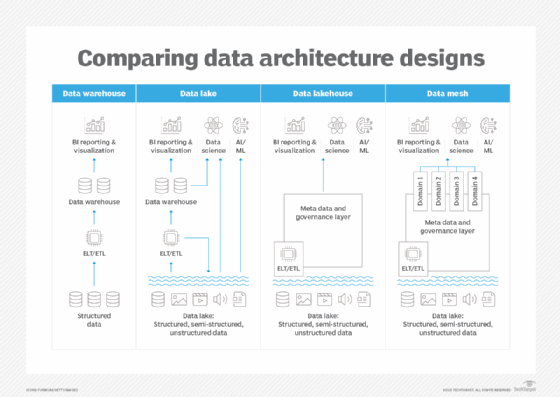
Data lake. A data lake is a large repository of raw data. It stores structured and unstructured data from multiple sources in its native format. Data lakes can become disorganized and difficult to manage as the volume of data grows.
Data warehouse. A data warehouse is a large centralized repository of data optimized for reporting and analysis. It can support complex queries and provide a single source of truth for business reporting. However, data warehouses can be expensive to implement and require a significant amount of upfront planning and design.
Data lakehouse. A lakehouse -- a combination of a data warehouse and a data lake -- enables enterprises to systematically extract insights like a data warehouse, via SQL or machine learning, while taking advantage of the scaling and cost benefits of a data lake. However, it has limited agility with adding new features because everything is centralized and monolithic. Data engineers must clean up data from teams that have limited incentive to ensure information is accurate as it goes in.
Many organizations are now exploring newer approaches such as data mesh architecture to overcome these limitations.
How data mesh compares to other data architectures.
How organizations adopt a decentralized architecture
The transition to a data mesh architecture has its challenges. Business leaders should be aware of the potential pitfalls and take steps to mitigate them. For example, ensure data domains are aligned with business objectives and necessary data governance structures are in place to ensure data quality, compliance and security.
An incremental approach to implementing a data mesh architecture can work with the following steps:
Identify the critical domains. The critical domains that require immediate attention are typically those that generate the most revenue or have the most significant impact on the business.
Build data hubs. Each domain requires a data hub. Data from various sources within the domain is collected, processed and analyzed in this hub. Start with one data hub.
Assign domain ownership. Each data hub should have a dedicated domain owner who is responsible for the data. The domain owner has the authority to make decisions about the data, including data quality, access and usage.
Expand to other domains. Once the first domain's data hub is operational, repeat the process for other domains and build data hubs incrementally. As you add new data hubs, update data contracts to include the new domains. This oversight ensures consistency across the entire data mesh.
Continuously improve. As new domains join and existing data hubs are updated, continuously review and refine the architecture to ensure it meets the organization's evolving needs.
Companies require a significant shift in mindset and culture to create and benefit from the data mesh.
Implementing a data mesh architecture is no small feat, especially for large organizations with complex data ecosystems. Companies require a significant shift in mindset and culture to create and benefit from the data mesh. Business leaders need to empower their teams and promote collaboration across teams.
By following the principles of data mesh and investing in the right tools, platforms and processes, companies can shift toward a decentralized data architecture. This will promote data autonomy and enable better data-driven decisions.
Author's note: The author would like to thank the informative post by Ashish Bijawat titled "Data Warehouse vs. Data Lake vs. Data Lakehouse vs. Data Mesh."
About the author Gunasekaran S is the director of data engineering at Sigmoid, a data engineering and AI consulting firm. As an advisor on data strategy, he helps customers design and implement modern data platforms for retail, consumer packaged goods, financial, travel and other sectors. Sigmoid's data management strategies have been instrumental in helping customers begin their journey toward a data mesh architecture.