
kosmin - Fotolia
Machine learning still big at Stripe despite deep learning hype
Classical machine learning methods are getting overshadowed in today's AI landscape, but problems with deep learning are keeping them relevant at payment processor Stripe.

With all the deep learning hype today, you might think it is the primary focus of development at most large web enterprises. But that's not true in all cases.
"Machine learning has been around for a long time," said Michael Manapat, engineering manager at online payment processing company Stripe Inc. "So while all of the attention has been on neural networks, there's still a huge amount of value in plausible machine learning that can solve industrial problems."
One of the main focuses of machine learning at Stripe is fraud detection and prevention. In the world of e-commerce, retailers are typically on the hook for fraudulent purchases made on their sites. If they send out goods for a purchase that is later blocked by a credit card company, the retailer has to eat the cost.
To spot potentially fraudulent transactions before they are processed, Stripe uses tried-and-true models. Random forests and gradient boosted decision trees form the core of their antifraud tool. These classical machine learning models may not be the most cutting-edge algorithms available, but they do have some important benefits.
Where explainability is important, classical methods reign
For one, Manapat said their outputs are easier to interpret than those of neural networks. This is critical when it comes to stopping fraudulent transactions because having too many false positives risks alienating customers and losing business for retailers. When the model recommends stopping a transaction, everyone involved wants to know why.
"One of the things we realized is that, even though [our users] are happy for us to take the reins, the visibility into why we make the decisions we do is important," Manapat said.
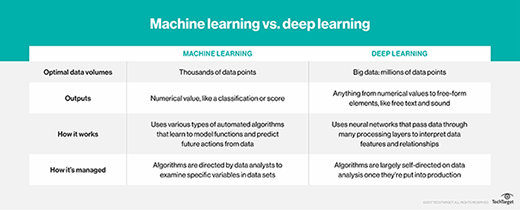
In general, the reason classical machine learning models are easier to interpret is straightforward. Traditional machine learning models typically look at fewer features in fewer data points, compared to a neural network, which generally trains on millions of data points, searching out extremely subtle correlations in many data features.
At this point, the Stripe model has trained on billions of customer records, matching some deep learning models in training data volume. But even at this large volume of data, Manapat said the structure of classical machine learning models makes them more transparent.
But getting to an explanation isn't as easy as just looking at a model's output. Stripe developed a secondary model that tries to encapsulate the specific reasons for a transaction being stopped and then passes this explanation on to the users. In and of itself, this is no easy task, but it would be nearly impossible if the fraud detection tool relied on more complex models.
"While our explanation system can theoretically work for all types of models, the structure of random forests and gradient-boosted trees makes it possible for us to optimize the computation more than we could for, say, a neural net," Manapat said.
The proper role of deep learning in industry
Still, none of this means Manapat and his team are hostile to deep learning. In fact, they are currently putting aside the deep learning hype and exploring how it can improve their fraud detection models.
Manapat said the Stripe team has identified the transaction features that are most predictive of fraud and engineered their machine learning models to assess these features. Things like whether a credit card has been used previously to make a purchase from the same IP address or country of purchase can all predict fraud, and the model knows to look for these characteristics.
But that doesn't mean there are no other features that can predict fraud. This is where deep learning could play a role. In classical machine learning, data scientists must find important data features for themselves. However, deep learning models independently assess all the features in a data set to tease out the predictive quality of each feature.
Manapat said adding a deep learning layer on top of the existing model could lead to even stronger results without sacrificing much interpretability.
"Feature engineering is the hardest part of machine learning, and deep learning can eliminate some of it," Manapat said.
Ultimately, Manapat said, it's important not to get caught up in the deep learning hype. Deep learning is really hot right now, but at the same time, some people are discovering its limitations. What's true is that it can be powerful in some applications, but not as useful in others.
"We're not trying to do the shiniest thing," Manapat said. "For a long time, that meant using practical techniques. But we are at a point now where we can find gains from deep learning."







