10 enterprise patch management best practices
It might not be the most exciting responsibility, but the value of a well-executed patch management strategy can't be denied. Use these best practices to build a smooth process.

Enterprise patch management requires the right balance of preparation, speed and agility. Without the proper processes and tools, patch updates can quickly fall behind. Failing to stay on top of patching can result in unnecessary exposure to security breaches or inoperable systems, applications and services.
These days, there are more endpoints than ever to monitor, from applications and servers to infrastructure and IoT devices. Data breaches can lead to theft or loss of sensitive information. Additionally, if those systems are left exposed, the chances of service disruptions escalate significantly, and the business might not be able to properly serve its customer base.
Simply relying on network and perimeter-based security, such as firewalls, intrusion prevention systems and other cybersecurity tools, is no longer sufficient. Zero-day exploits crop up regularly, and the ability of perimeter-based tools to protect newly identified security vulnerabilities is waning by the day. Thus, these types of vulnerabilities are best handled directly by patching software and firmware.
While patch management isn't known to be the most fun or interesting responsibility of IT administrators, if done right, the results can prove invaluable. Learning enterprise patch management best practices is well worth the time and effort.
Here are 10 tips to ensure your patch management process flows smoothly and with fewer unforeseen hazards.
1. Always know what you're responsible for patching
Identify targets and where they're located. The endpoints, servers, infrastructure components, apps and services your IT department is responsible for patching are in constant flux. They might reside on premises, in the cloud or on the internet. Those responsible for creating an organization-wide patch strategy must always be aware of changes. While it might be possible to track IT resources manually, most find it beneficial to use various device, network and application monitoring tools for continuous monitoring and inventorying. Patch management inventory and scanning tools can also detect and track devices that are missing critical updates, ensuring nothing falls through the cracks.
2. Get the vendor involved
In many cases, questions surrounding a new feature or security patch might not be readily available given the vendor's published documentation. If questions arise, it's always better to err on the side of caution and reach out to the vendor prior to making a production change. While this might add time to the execution of a patch, it's likely better than applying patches and having them cause unnecessary harm to your operations or failing to achieve the desired results.
3. Categorize systems into groups based on criticality
Not all applications, systems and platforms are equal from a patch management perspective. Critical network and server infrastructure, for example, is likely to cause far more damage if a vulnerability is exploited than non-mission-critical applications and services. As such, organizations should carefully evaluate and categorize systems by criticality and patch the most critical ones first.
4. Create standard and emergency patching procedures
An enterprise patching strategy should consist of two procedures: standard and emergency. Standard patching procedures detail what happens during normal, regularly scheduled patching. This includes specific calendar dates and maintenance windows when various infrastructure components receive patching updates. The standard schedule is useful because it creates a timetable for administrators to work from so that patching doesn't fall behind. Also, a schedule informs department managers and users well in advance of when a work-affecting maintenance window will occur.
Emergency patch procedures are when a patch, usually a security patch, must be installed outside the standard patching window. These are commonly identified by vulnerability or compliance assessment tools. Use emergency patching windows sparingly, and take great care in determining the thresholds that have to be met for a window to be approved. Emergency processes must also include the communications steps and channels for properly notifying affected departments, users and customers.
5. Understand each vendor's patch release schedule
The number and types of OSes, applications and end-device firmware vary from one organization to the next. So, too, do vendor patch announcements and release schedules. For example, Microsoft uses a monthly patch schedule -- known as Patch Tuesday -- to release its software patches. IT admins must understand when regularly scheduled patches are released, as well as each vendor's process for notifying them about emergency patches.
6. Design and maintain a realistic patch testing environment
Once a patch is released, you can't simply apply it and assume it works without side effects. It's inevitable that some patches will break a feature, process or other interaction your business depends on. The purpose of a software patch testing environment is to see what impact a patch has in an environment that closely matches your production environment. Designing and maintaining the environment, however, are easier said than done. The key is to make sure the test environment is updated right along with production. Any architecture changes made to production that could be affected by software patches must be mimicked in the test environment. Fortunately, server virtualization and test sandboxes have made it much easier and cheaper to create a test environment that closely matches production.
Administrators need ample time to test newly released patches before rolling them out to production. Patch management timelines can fall off the rails when a patch breaks something in production and must be rolled back. Allocate appropriate amounts of time to properly test patches for adverse effects before putting them into your live environment.
7. Use the right tools for automating patch management
Manually managing software and firmware patch installation across a wide range of enterprise servers, appliances and clouds can quickly become overwhelming without the right tools and processes in place. Because of the sheer number of different devices and software that must be kept up to date with the latest code, automated patch management tools are often used. These tools, which are becoming increasingly sophisticated and useful by the day, can automate repetitive, tedious tasks to shorten the time between a patch's release and its implementation.
8. Review the patch process and results
Once a patch has been successfully applied, it's important to look back to see where improvements in the patching process can be made. Patching processes and procedures should always be evolving toward greater efficiency.
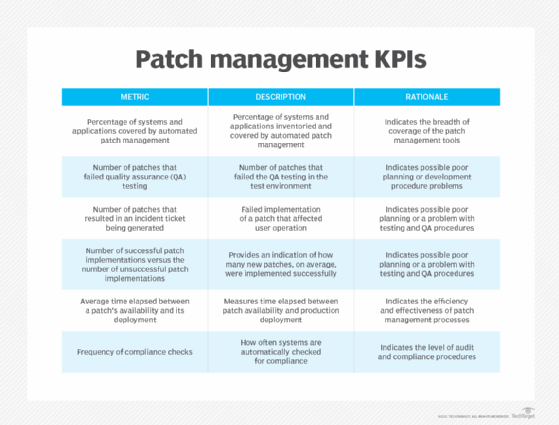
The most common method to stay on top of patch management results is to use the patch management tool's reporting feature, which records the results of each update in an automatically generated report. The historical reports can be reviewed to see if any past lessons learned should be implemented into the patch management policy. Details in a report can include the following:
- An inventory and count of the devices and applications detected on the corporate network.
- Number of installed patches.
- Number of missing patches.
- Names of systems that remain vulnerable and to what extent.
- Patches that have been approved and scheduled.
- Patches waiting to be approved.
Using this information, IT managers can track the performance of existing procedures and make adjustments to remove bottlenecks or improve turnaround times.
9. Establish rollback and disaster recovery procedures
An implemented patch can result in unintended consequences on a production network even if the proper patch testing procedures are followed. Mandating that rollback and disaster recovery procedure steps be created and followed is an absolute must. This lets patch install teams quickly roll back or implement recovery workarounds with a lower risk of human error.
10. Work collaboratively with IT teams
The impact of a patch on infrastructure components can affect multiple IT teams. Communication is critical as these external teams might provide insights that could otherwise go unnoticed and result in a patch that affects other parts of the infrastructure. Establishing regularly scheduled change management meetings where representatives from each team meet and discuss patch plans, timelines and details is a great way to bridge the collaboration gap.
Rapid implementation matters more than ever
Given the numerous threats that exist today, combined with the average enterprise's ever-increasing reliance on technology to conduct business, the risk of failing to rapidly identify, patch and monitor the results of performance and security updates is growing by the day. Great care and consideration should be taken to implement patch management strategies that help keep systems performing safe and optimally now and long into the future.
Andrew Froehlich is founder of InfraMomentum, an enterprise IT research and analyst firm, and president of West Gate Networks, an IT consulting company. He has been involved in enterprise IT for more than 20 years.






