Block, file and object storage interfaces enable integration
Explore the capabilities, as well as the strengths and weaknesses, of some storage vendors' products that support and integrate block, file and object interfaces.
IT shops used to buy SANs for block storage, NAS for file storage and cloud gateways for object storage. Now they can buy software-defined storage products that support all block, file and object storage interfaces. In this article, we take a look at some of these products, how they work and their strengths and weaknesses.
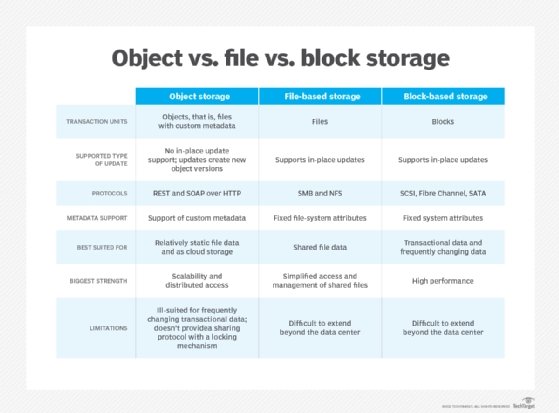
Block storage is the oldest type of storage. It was originally used to access hard disks in a local server, using hardware-based blocks, sectors and tracks. Later block storage systems used software when hard drives exceeded physical limits set by the BIOS and operating system.
When file servers were first developed in the late seventies, they made internal block storage available as file storage. They did that through storage protocols such as the Network File System (NFS) and Common Internet File System (CIFS) that presented a hierarchy of directories and files. As server-based data centers evolved, SANs presented block-based storage that could be used by multiple servers as an alternative to internal storage or direct-attached storage. Then NAS storage systems removed the middleman and presented file-based storage directly to end users instead of requiring a separate file server.
Object-based storage is a relatively new concept in the evolution of block, file and object storage. It treats each file as a separate object that contains the file itself, metadata and a unique identifier. The metadata holds information such as the type of file, date of creation and owner.
How object, block and file storage compare
Object storage
The advantage to an object-based system is that each file can be hosted on a variety of systems, either within the data center or in the cloud. It uses the unique identifier to keep track of files, letting end users access them regardless of whether they're physically located on a local file server, a storage system in the data center or in the cloud. This isn't a trivial task. Large organizations could have billions of objects stored in dozens of different systems around the world. Assigning and keeping track of the ID for each object consumes considerable resources.
Data storage systems have combined block and file functionality for years. Originally, object storage systems used either software or hardware gateways to provide access to proprietary cloud-based object storage on cloud services such as Amazon S3 and Microsoft Azure. As these services standardized on protocols such as S3 and OpenStack, object storage services started to become available from multiple cloud providers and on-site data center storage systems.
Object storage is virtualized, as the same file might be stored on any of a number of local or cloud systems. It all depends on when it was last accessed, the priority an administrator assigns it or a defined storage policy. When a user opens the file, it's usually moved back to local storage to ensure best performance as the file is modified and saved. After a period of inactivity, the file may be moved back to inexpensive cloud storage or, perhaps, from hot to warm to cold and then to cloud storage. Each move reduces the cost to store the file. If that file is accessed again, it can be moved back to local storage.
IT can also configure object storage to distribute objects across multiple silos of storage -- for example, to two or more geographic regions. That way, if one location is offline or slowed due to congestion, the files are still available. The object storage system keeps track of changes and ensures copies are synced.
An object storage gateway is similar to a software-defined-WAN because it's software-based and doesn't require specific hardware. A PC or server can run an object storage gateway. Integrating object storage into an existing SAN or NAS system doesn't require rearchitecting the system, only adding software to the existing virtualization system.
Object storage integration
There are enterprise storage systems available that combine SAN, NAS and object. Vendors include Dell EMC, Hewlett Packard Enterprise (HPE), Hitachi Vantara, IBM and NetApp. Because an object storage gateway is software, once object functionality is developed, it can be added to virtually any product in a storage manufacturer's lineup.
There are a number of enterprise storage systems available that combine SAN, NAS and object into one system.
Some vendors build a cloud gateway -- an object gateway -- into their storage, so a single box can encompass block, file and object storage. Others use a separate appliance that integrates with their storage controller. However, when a typical starter system is an equipment rack or two of controllers, storage nodes, disks and connecting hardware, it doesn't really matter if object storage is enabled through a 2U appliance. What does matter is the degree to which the object storage appliance is integrated with the rest of the storage management system. The degree of integration dictates whether the object store can be treated as part of the data center storage system. It also affects whether tiers of cloud storage can be treated as additional tiers for an auto-tiering system and whether a cloud volume can be easily configured for replication, deduplication, encryption and other features the system offers with local storage.
Let's see how various storage vendors and their products approach the issue of block, file and object storage integration. This isn't intended to be a comprehensive look at all such products or features.
Dell EMC
Dell EMC encompasses products from legacy Dell, EMC, Compellent, Isilon and Data Domain. They were all once separate companies and still have individual product development teams. Hence, each brand may have separate object storage features and strategies. Of course, this is true of HPE and its 3Par and Nimble platforms as well.
The EMC VMAX, recently rebranded PowerMax, storage line offers the CloudArray enabler. It lets you hook together a VMAX storage system and a CloudArray gateway appliance with internal storage and the ability to connect to a variety of cloud storage vendors. Cloud storage is presented alongside physical storage within the overall data center storage system.
After a storage system is configured and cloud volumes added, it can migrate data from the data center to the cloud and back, and automatically move data across storage tiers based on policy. Virtually any function used within the data center or between data centers, such as file or volume replication, can be used with the cloud as well. This means that block storage volumes or files in the data center can be replicated to the cloud as object stores and vice versa. There's effectively no barrier between the three types of storage.
Hitachi Vantara
Hitachi Content Platform can connect to a variety of object stores, whether it's Ceph running on hardware in the same or another data center, Amazon S3, Commvault, or other public and private cloud vendors. All of the features available through the Hitachi Vantara storage system are also available with cloud volumes, including synchronization among multiple volumes at the object, file, block and volume level; auto-tiering; compression; and encryption, with a single pane of management across all tiers.
HPE 3Par and Nimble
HPE Cloud Volumes are available on several HPE storage systems, including Nimble Storage systems. They support multiple cloud services, including AWS S3 and Azure. Because connections are implemented through HPE services, there's a cost per month from HPE in addition to what the cloud vendor charges.
The plus side to the implementation is that connecting to storage is simplified compared with connecting directly to the vendor. The HPE services make connecting the block and file storage in the local data center to object stores in the cloud easier. They act as an intermediary, providing mapping of block storage volumes and NFS and CIFS file stores to object stores in the cloud, which can be complex to set up.
IBM
IBM offers both proprietary cloud storage -- IBM Cloud based on the RESTful API -- and functionality that connects to its own and other clouds. This lets IBM's block and files storage systems in the data center extend their functionality to the cloud for resiliency and availability, using IBM's own cloud offering or public cloud options. IBM's orchestration service can simplify the provisioning, deploying, maintaining and migrating of workloads and affiliated storage, whether from the data center to the cloud, one cloud to another or the cloud back to data center.
Cloud costs
Many cloud vendors would have you believe that you can store your data in their cloud for less than the cost of running your "obsolete" storage hardware in the data center. Actual costs of on-site storage include power, cooling, floor space, software updates, support subscriptions, replacement costs for failing hardware and management costs that represent both your administrator's time in keeping everything running and the time spent upgrading software and hardware. However, these costs may not be relevant when comparing on-site storage to cloud storage.
An amortized storage system, especially one used for archiving or as the lowest tier in an auto-tiering system, may have a higher operating cost for power and cooling than a new system, but whether this affects the bottom line will depend on the local cost of electricity. In many locations, replacing an existing storage system to save power will never have an ROI -- the cost of power is such a small fraction of the cost of a new array that it will never pay off. In other locations, such as the New York City metropolitan area, limitations on total available power in a building, cooling and the size of the data center, as well as the cost of electricity, may make such replacements cost effective.
By integrating block, file and object storage through an existing controller or a separate appliance available from Dell, Hitachi Vantara, HPE or NetApp, storage admins can gain flexibility in making the best use of their existing storage and integrating it with block storage. They can do that either using an existing storage array in the data center or cloud storage from companies like Amazon and Google. By breaking down the barriers between block, file and object storage, storage admins can eke out the last usable capacity of an old block-based storage array and then migrate the data to a file store when the block-based array is retired. They can move the same data to the cloud, seamlessly and with little effort.
The same goes for management costs -- a smaller company with a storage administrator who isn't overloaded can better afford to dedicate some of the administrator's time to storage admin than buying a new array.
NetApp
NetApp's StorageGRID Webscale software provides integration between NetApp on-site storage and cloud storage, such as S3. This allows data in on-site block and file storage to be replicated to the cloud, adding resiliency and availability to the on-site data center hardware.
As with systems from other vendors, the StorageGRID system is a separate appliance, but it's integrated into the overall NetApp ecology, providing the same features and functionality available in the company's local storage products. By extending the services available with on-site data center hardware using block and file storage to the cloud through its object storage gateway, the NetApp system gains a third tier of storage for adding redundancy and availability to on-site storage.
Bottom line on block, file and object storage
The basics of integrated block, file and object storage are similar for all the products in this market. Whether an object gateway is integrated into an existing storage controller or added as a separate appliance, the system translates between the three types of storage. It also lets the data be stored locally on block storage or a file storage system and in the cloud as an object. This provides the cost efficiency, flexibility, redundancy and resiliency that are possible with the cloud.
The features differ from vendor to vendor, including whether they offer synchronous or asynchronous replication, how many geographical sites are supported for distributed object storage, the migration tools provided to move data from block storage to file storage to object storage and back and how the automated tiering software works with deduplication. The good news is that most vendors offer object storage functionality that integrates well with their existing block and file systems.