Part of:Understand and implement edge storage technology
Computational storage may ease edge storage efforts
Before diving into storage at the edge, ensure your organization can meet the technology's lofty space and resource requirements. Computational storage can help.
More companies than ever are turning to edge computing to deploy data-intensive workloads that include AI to predictive analytics to the internet of things. Edge computing brings IT resources closer to where the data is generated, rather than transporting raw data to a centralized data center.
Unfortunately, the edge model has several limitations. IT teams must find ways to get beyond common roadblocks to deliver the compute and storage resources necessary to support their workloads. One of the most promising fixes is computational storage, which incorporates processing capabilities directly into storage systems to remove I/O bottlenecks and reduce application latencies. This makes it possible to process greater amounts of data in an edge environment.
Computing at the edge
Edge computing is a distributed architecture that moves data center resources to the network's periphery for processing and storage. In many cases, this means locating those resources in a branch or satellite office. By bringing data and applications closer together, edge computing can reduce network traffic, streamline computing operations and improve performance of mission-critical workloads. This eliminates many of the bandwidth and throughput issues that come with a centralized data center.
Despite these benefits, edge computing also presents several challenges, such as managing security, orchestrating distributed systems and mapping data between the data center and edge environments. One of the biggest issues is overcoming the limitations of the compute and storage resources themselves, such as space and resource requirements. These limitations can make it difficult to maximize the performance of data-intensive workloads, especially as they become more complex and data volumes continue to grow.
By its very nature, an edge environment is often constrained by available space, making it difficult to host the equipment needed to support today's modern workloads. Available space might be restricted to a closet or corner of an office -- with limitations on size, power and cooling -- offering little in comparison to a full-blown data center.
It's also rare for edge environments to be equipped with the type of high-powered compute resources that populate a data center. Although it's possible to push state-of-the-art servers out to the edge, IT budgets are seldom so accommodating, especially when organizations must still support mission-critical workloads in their data centers.
Because of these restraints, IT teams have had a difficult time getting the workload performance they need in their edge environments. But this hasn't stopped them from trying. Some teams have implemented all-flash storage arrays, NVMe, GPU accelerators and other advanced technologies. Although these have helped some, they're not enough to address performance to the degree necessary to effectively support many of today's more robust workloads.
Computational storage represents a huge gain for data-intensive workloads running on the edge.
A big reason for this is that conventional compute/storage architectures are inherently limited by the bandwidth of the I/O ports that stand between storage devices and compute resources. As data is processed, it must pass through these links, which are only as fast as the technologies that support them. By extension, the more data that must move between storage and memory, the greater the resulting bottleneck.
This is where computational storage enters the scene. It removes the bottleneck by bringing compute and storage resources closer together to minimize data movement, resulting in lower latencies and faster applications.
Computational storage to the rescue
Traditional compute/storage architectures require time and resources just to move data from one system to the other, resulting in higher latencies and poorer application performance. In contrast, computational storage takes an in-situ approach to data processing, moving at least some of the operations from the compute resources to inside the storage system. Here, data can be processed faster and more efficiently, not only because of less data movement, but because of the extensive use of parallel processing.
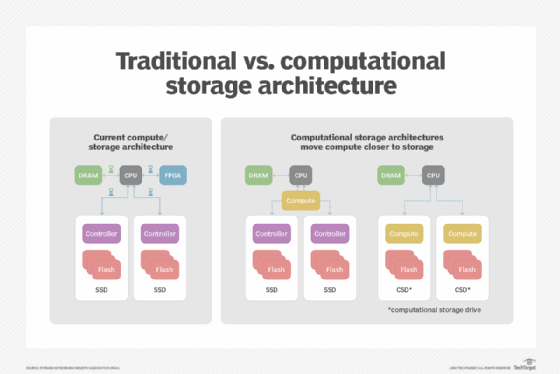
How computational storage stacks up against a traditional architecture Source: Storage Networking Industry Association (SNIA)
The storage system preprocesses the data on behalf of the compute system so that only a subset of data is eventually sent to memory. By minimizing data movement, you can achieve lower application latencies and reduce the load on compute resources, freeing them up for other operations.
Computational storage represents a huge gain for data-intensive workloads running on the edge, especially those that can't afford the delays that come with increased latencies. For example, an organization might implement an AI application that continuously analyzes data streaming into its storage systems. At times, there might be as much as several terabytes coming in per hour.
The application's goal is to provide business stakeholders with automatically generated reports that include near real-time insights into current operations. Not surprisingly, the data in the reports represents only a fraction of the total amount of raw data.
In a traditional compute-storage model, the data must constantly move from storage to memory as new data becomes available, putting a continuous strain on the I/O ports and compute resources. Under such circumstances, the reports could easily be late or include stale data. However, if the analytics are performed in situ, the compute resources need only the aggregated totals to generate the reports, leading to faster and more efficient operations. This also minimizes the impact on network bandwidth and compute resources, freeing them up for other loads.
The brave new world of computational storage
Several vendors now offer computational storage systems, including Samsung, NGD Systems, ScaleFlux and Eideticom. This is still a young industry, and it's left to the vendor to determine how best to implement computational storage, which could make system integration a somewhat messy prospect.
In an effort to increase acceptance of computational storage, the Storage Networking Industry Association is creating standards that address the interoperability of computational devices and define interface standards for deploying, provisioning, managing and securing devices.
Computational storage could benefit any data-intensive, latency-sensitive workload running in an edge environment. Much of the focus in edge computing is on IoT data, however, the source of the data is not the primary concern when it comes to computational storage. The amount of data, how frequently it's updated and what you need to do with that data is of primary concern. When assessing the value of computational storage, organizations must take it on a case-by-case basis, deciding whether the performance gains are worth the costs of a new storage tool.