What is fog computing?
Fog computing is a decentralized computing infrastructure in which data, compute, storage and applications are located somewhere between the data source and the cloud. Like edge computing, fog computing brings the advantages and power of the cloud closer to where data is created and acted upon. Many people use the terms fog computing and edge computing interchangeably because both involve bringing intelligence and processing closer to where the data is created. This is often done to improve efficiency, though it might also be done for security and compliance reasons.
The fog metaphor comes from the meteorological term for a cloud close to the ground, just as fog concentrates on the edge of the network. The term is often associated with Cisco; the company's product line manager, Ginny Nichols, is believed to have coined the term. Cisco Fog Computing is a registered name; fog computing is open to the community at large.
How does fog computing work?
Fog networking complements -- doesn't replace -- cloud computing; fogging enables short-term analytics at the edge, while the cloud performs resource-intensive, longer-term analytics. Although edge devices and sensors are where data is generated and collected, they sometimes don't have the compute and storage resources to perform advanced analytics and machine learning tasks. Though cloud servers have the power to do this, they are often too far away to process the data and respond in a timely manner.
In addition, having all endpoints connecting to and sending raw data to the cloud over the internet can have privacy, security and legal implications, especially when dealing with sensitive data subject to regulations in different countries. Popular fog computing applications include smart grids, smart cities, smart buildings, vehicle networks and software-defined networks.
Fog computing vs. edge computing
According to the OpenFog Consortium started by Cisco, the key difference between edge and fog computing is where the intelligence and compute power are placed. In a strictly foggy environment, intelligence is at the local area network (LAN), and data is transmitted from endpoints to a fog gateway, where it's then transmitted to sources for processing and return transmission.
In edge computing, intelligence and power can be in either the endpoint or a gateway. Proponents of edge computing praise its reduction of points of failure because each device independently operates and determines which data to store locally and which data to send to a gateway or the cloud for further analysis. Proponents of fog computing over edge computing say it's more scalable and gives a better big-picture view of the network as multiple data points feed data into it.
It should be noted, however, that some network engineers consider fog computing to be simply a Cisco brand for one approach to edge computing.
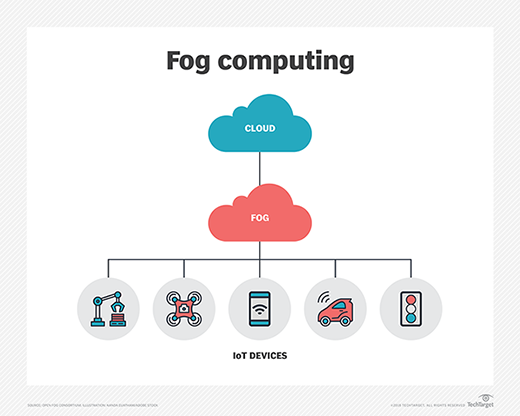
How and why is fog computing used?
There are any number of potential use cases for fog computing. One increasingly common use case for fog computing is traffic control. Because sensors -- such as those used to detect traffic -- are often connected to cellular networks, cities sometimes deploy computing resources near the cell tower. These computing capabilities enable real-time analytics of traffic data, thereby enabling traffic signals to respond in real time to changing conditions.
This basic concept is also being extended to autonomous vehicles. Autonomous vehicles essentially function as edge devices because of their vast onboard computing power. These vehicles must be able to ingest data from a huge number of sensors, perform real-time data analytics and then respond accordingly.
Because an autonomous vehicle is designed to function without the need for cloud connectivity, it's tempting to think of autonomous vehicles as not being connected devices. Even though an autonomous vehicle must be able to drive safely in the total absence of cloud connectivity, it's still possible to use connectivity when available. Some cities are considering how an autonomous vehicle might operate with the same computing resources used to control traffic lights. Such a vehicle might, for example, function as an edge device and use its own computing capabilities to relay real-time data to the system that ingests traffic data from other sources. The underlying computing platform can then use this data to operate traffic signals more effectively.
What are the benefits of fog computing?
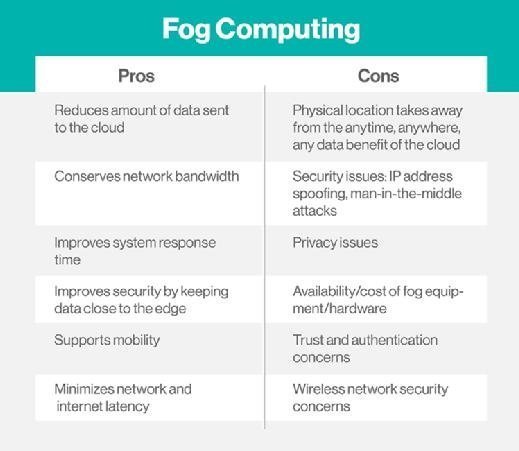
Like any other technology, fog computing has its pros and cons. Some of the advantages to fog computing include the following:
- Bandwidth conservation. Fog computing reduces the volume of data that is sent to the cloud, thereby reducing bandwidth consumption and related costs.
- Improved response time. Because the initial data processing occurs near the data, latency is reduced, and overall responsiveness is improved. The goal is to provide millisecond-level responsiveness, enabling data to be processed in near-real time.
- Network-agnostic. Although fog computing generally places compute resources at the LAN level -- as opposed to the device level, which is the case with edge computing -- the network could be considered part of the fog computing architecture. At the same time, though, fog computing is network-agnostic in the sense that the network can be wired, Wi-Fi or even 5G.
What are the disadvantages of fog computing?
Of course, fog computing also has its disadvantages, some of which include the following:
- Physical location. Because fog computing is tied to a physical location, it undermines some of the "anytime/anywhere" benefits associated with cloud computing.
- Potential security issues. Under the right circumstances, fog computing can be subject to security issues, such as Internet Protocol (IP) address spoofing or man in the middle (MitM) attacks.
- Startup costs. Fog computing is a solution that utilizes both edge and cloud resources, which means that there are associated hardware costs.
- Ambiguous concept. Even though fog computing has been around for several years, there is still some ambiguity around the definition of fog computing with various vendors defining fog computing differently.
Fog computing and the Internet of Things
Because cloud computing is not viable for many internet of things (IoT) applications, fog computing is often used. Its distributed approach addresses the needs of IoT and industrial IoT (IIoT), as well as the immense amount of data smart sensors and IoT devices generate, which would be costly and time-consuming to send to the cloud for processing and analysis. Fog computing reduces the bandwidth needed and reduces the back-and-forth communication between sensors and the cloud, which can negatively affect IoT performance.
Fog computing and 5G
Fog computing is a computing architecture in which a series of nodes receives data from IoT devices in real time. These nodes perform real-time processing of the data that they receive, with millisecond response time. The nodes periodically send analytical summary information to the cloud. A cloud-based application then analyzes the data that has been received from the various nodes with the goal of providing actionable insight.
This architecture requires more than just computing capabilities. It requires high-speed connectivity between IoT devices and nodes. Remember, the goal is to be able to process data in a matter of milliseconds. Of course, the connectivity options vary by use case. An IoT sensor on a factory floor, for example, can likely use a wired connection. However, a mobile resource, such as an autonomous vehicle, or an isolated resource, such as a wind turbine in the middle of a field, will require an alternate form of connectivity. 5G is an especially compelling option because it provides the high-speed connectivity that is required for data to be analyzed in near-real time.
What is the history of fog computing?
In 2015, Cisco partnered with Microsoft, Dell, Intel, Arm and Princeton University to form the OpenFog Consortium. Other organizations, including General Electric (GE), Foxconn and Hitachi, also contributed to this consortium. The consortium's primary goals were to both promote and standardize fog computing. The consortium merged with the Industrial Internet Consortium (IIC) in 2019.







