The differences between cloud, fog and edge computing
Cloud, edge and fog computing all support modern applications. Cloud computing offers centralized resources, edge enables real-time processing and fog connects them hierarchically.

Modern distributed computing architectures support significant technological advances, such as AI and smart manufacturing. Each computing model is key to supporting advanced applications that transform the landscape.
Digital enterprises have sprawling virtual environments that demand a flexible and resilient infrastructure capable of keeping up with ever-increasing processing and storage requirements. Estimates predict connected devices will top 40 billion globally in the next five years. With a massive spending increase on AI application development, cloud providers are investing hundreds of billions of dollars in data center expansion.
Advanced digital applications require a flexible, efficient and reliable infrastructure. The underlying processing and storage models that facilitate this are cloud computing, edge computing and fog computing. Each has an important role in the infrastructure. Though often placed in opposition to each other, the models can be complementary.
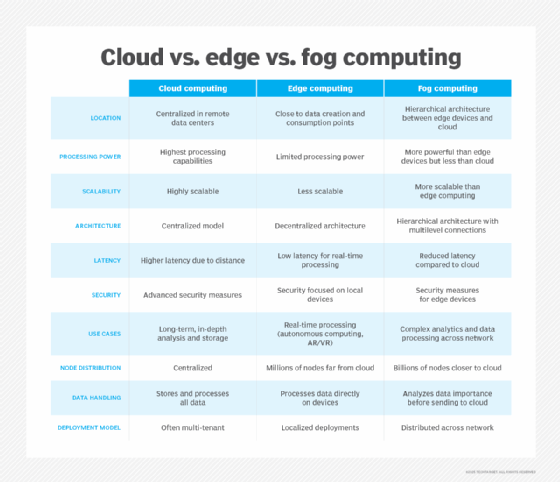
Cloud vs. edge vs. fog computing
All digital models have their origins in grid computing, a concept developed in the 1990s. Grid computing builds on the idea of aggregating computing resources for processing-intensive requirements in applications such as scientific research, game design and financial risk management. The digital computing models common in networking include the following:
- Cloud computing. Provides centralized resources with high scalability and processing power, ideal for long-term analysis and storage.
- Edge computing. Processes data directly at or near the source, useful for real-time applications with low latency requirements.
- Fog computing. Serves as an intermediary layer, analyzing data importance before transmitting to the cloud and providing distributed processing across the network.
Cloud computing
Cloud computing supports a wide range of services, including IaaS and SaaS. This enables cloud computing to provide compute and storage services as needed on a pay-per-use or subscription model, eliminating the need for clients to invest in capital equipment upfront.
Cloud computing emerged in the mid-2000s when online retailer Amazon launched the IaaS market with its Elastic Compute Cloud (EC2) service on demand. EC2 used excess capacity from its online commerce operations to deliver low-cost, high-volume virtualized compute services. Amazon did the same with storage through its Simple Storage Service offerings.
The benefits are clear; organizations can quickly increase processing and storage capacity. Cloud computing uses a consolidated computing model, which enables clients to access resources from a centralized environment. Cloud services can be private or multi-tenant, with clients sharing hardware resources.
Cloud computing security uses comprehensive measures such as encryption, access controls and continuous monitoring to protect data and applications stored in remote data centers. This enables businesses to use cloud services without compromising sensitive information.
Edge computing
Computing is increasingly distributed and requires more effective delivery of processing power for latency-sensitive applications. Edge computing plays a key role in accelerating application performance and improving efficiency.
Edge computing is where processing and storage occur close to the data creation and consumption point. Its hardware -- including edge servers and hyperconverged infrastructure appliances -- runs in secondary or tertiary data centers. Cloud providers often partner with third-party vendors or telecom operators to extend their services to the edge for localized processing.
Use cases for edge computing include applications that require real-time processing, such as autonomous vehicles, augmented and virtual reality, and smart cities.
Edge computing security features include encryption, authentication and physical safeguards to prevent unauthorized access while keeping sensitive information closer to its source rather than sending it to cloud servers.
Fog computing
Fog computing is essentially an extension of edge computing. It's a more distributed model that involves multiple levels of processing and storage. While fog computing provides the network infrastructure with computational processing between edge devices and cloud computing facilities, it isn't limited to the edge or the cloud. It supports use cases such as complex analytics and other data processing at decentralized points across the network.
Fog computing security creates multiple layers of protection across distributed processing nodes between edge devices and the cloud. It combines local authentication, encrypted data transmission and centralized monitoring to protect information as it travels through different levels of network infrastructure.
How these models align for advanced applications
Rather than assuming fog, edge and cloud computing are adversarial models, it's helpful to consider how they can work together. Each model has a unique role in supporting application use cases, which can be complementary in certain environments. Take the following example.
Cloud computing environments are often multi-tenant. While this keeps costs low, it also introduces questions around security and regulatory compliance. Due to the distance between data creation and consumption points, cloud computing isn't optimized to support applications with low-latency requirements. Enter edge computing.
Edge computing is a natural extension of cloud computing. It applies cloud services close to the data creation and consumption points to support real-time analytics. The nature of edge computing deployments aligns well with localized data residency requirements, therefore addressing security and privacy concerns.
However, data isn't always processed at the point of creation. Fog computing is useful in more intricate use cases where data processing takes place at different network junctures. It's important in large-scale applications that apply analysis across locations and devices, such as large-scale IoT implementations.
Amy Larsen DeCarlo has covered the IT industry for more than 30 years, as a journalist, editor and analyst. As a principal analyst at GlobalData, she covers managed security and cloud services.






