Windows event log
What is the Windows event log?
The Windows event log is a detailed and chronological record of system, security and application notifications stored by the Windows operating system that network administrators use to diagnose system problems and predict future issues.
The operating system (OS) and applications use these event logs to record important hardware and software actions the administrator can use to troubleshoot issues with the OS. The Windows OS tracks specific events in its log files, such as application installations, security management, system setup operations on initial startup, and problems or errors.
Microsoft first offered the Windows event log the release of Windows Vista and Windows Server 2008. It has been included in all subsequent versions of Windows.
The elements of a Windows event log
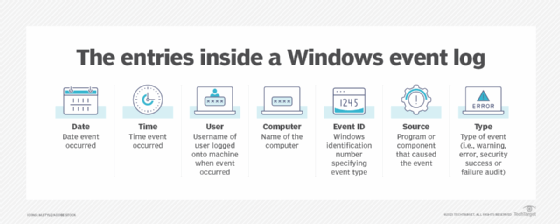
Each event in a log entry contains the following information:
- Level. Severity of event, including information, critical, warning, error, verbose.
- Date. Date an event occurred.
- Time. Time an event occurred.
- Source. Program or component that caused the event.
- Event ID. A Windows identification number that specifies the event type.
- Task category. Recorded event log type.
- User. Username of the user logged onto the machine when the event occurred.
- Computer. Name of the computer.
Here are some examples of how log entries are displayed.
| Level | Date | Time | Source | Event ID | Task Category |
| Information | 5/16/2018 | 8:41:15 AM | Service Control Manager | 7036 | None |
| Warning | 5/11/2018 | 10:29:47 AM | Kernel-Event Tracing | 1 | Logging |
| Error | 5/16/2018 | 8:41:15 AM | Service Control Manager | 7001 | None |
| Critical | 5/11/2018 | 8:55:02 AM | Kernel-Power | 41 | (63) |
Information stored in Windows event logs
The Windows operating system records events in five areas -- application, security, setup, system and forwarded events:
- Application events. These relate to incidents with the software installed on the local computer. If an application crashes, then the Windows event log will create an application log entry about the issue containing the application name and information on why it crashed.
- Security events. These store information based on the Windows system's audit policies. Typical events logs stored include login attempts and resource access. For example the Windows security log stores a record when the computer attempts to verify account credentials when a user tries to log on to a machine.
- Setup events. These include enterprise-focused events relating to the control of domains, such as the location of logs after a disk configuration. This log will also keep track of occurrences involving Active Directory on domain controllers.
- System events. These relate to incidents on Windows-specific systems, such as the status of device drivers.
- Forwarded events. These arrive from other machines on the same network when an administrator wants to use a computer that gathers multiple logs.
Using the Event Viewer
In Windows, the event logs are stored in the C:\WINDOWS\system32\config\ folder. They are created for each system access, operating system blip, security modification, hardware malfunction and driver issue.
The role of the Event Viewer tool is to scan through those text log files and gather and present them in an intuitive user interface (UI), similar to how a database reporting tool would.
The following steps can be taken to check the events logs through the Event Viewer:
- Press the Windows key + R on the keyboard to open the Run window.
- Enter eventvwr in the Run dialog box and press OK.
- Expand the Windows Logs menu in the Event Viewer window.
- Notice the different types of event logs found under the Windows Logs menu, including application logs, security logs, setup logs, system logs and forwarded events.
- Click on one of the event logs to search for and view the recorded events under it.
Windows events severity levels
Windows categorizes every event with a severity level. The levels in order of severity are information, verbose, warning, error and critical.
- Information. Most logs consist of information-based events. Logs with this entry usually mean the event occurred without incident or issue. An example of a system-based information event is Event 42, Kernel-Power, which indicates the system is entering sleep mode.
- Verbose. These events represent progress or success messages for a specific event.
- Warning. Warning level events are based on particular events, such as a lack of storage space. Warning messages can bring attention to potential issues that might not require immediate action. Event 51, Disk is an example of a system-based warning related to a paging error on the machine's drive.
- Error. An error level indicates a device may have failed to load or operate expectedly. Event 5719, NETLOGON is an example of a system error when a computer cannot configure a secure session with a domain controller. The error level's severity is low and doesn't require instant troubleshooting.
- Critical. Critical level events indicate the most severe problems. Event ID 41, Kernel-Power is an example of a critical system event when a machine reboots without a clean shutdown.
Other tools to view Windows event logs
Microsoft also provides the wevtutil command-line utility in the System32 folder that retrieves event logs; runs queries; and exports, archives and clears logs.
A few popular third-party utilities that also work with Windows event logs include the following:
- SolarWinds Security Event Manager (SEM). This tool provide a centralized log collection, real-time event correlation and remediation, file integrity monitoring and threat detection through an intuitive dashboard and user interface. It also automatically collects logs from servers, applications and network devices.
- Site24X7. This powerful Windows event log management tool from ManageEngine can identify anomalies in Windows event logs, logs from custom programs and logs from services. It can also send immediate notifications when errors arise.
- Sumo Logic log management and log analytics. This log management software offers real-time analytics, custom dashboards, and machine learning for both cloud-based and on-prem applications.
- Datadog. Datadog's cloud monitoring tool with log management capabilities offers dashboards, alarms, search and filtering in addition to log management features.
Using PowerShell to query events
Microsoft builds Windows event logs in Extensible Markup Language (XML) format with an EVTX extension. XML provides more granular information and a consistent format for structured data.
Administrators can build complicated XML queries with the Get-WinEvent PowerShell cmdlet to add or exclude events from a query.
Logs provide insightful information about a system's internal operations. Discover and investigate the function of Windows log monitoring in the enterprise.







