
What is Google Cloud?
Google Cloud is a suite of public cloud computing services offered by Google. The platform includes a range of hosted services for compute, storage, machine learning (ML), big data analytics, networking and application development that run on Google hardware.
Software developers, cloud administrators and other enterprise IT professionals can access Google Cloud services over the internet or through a dedicated network connection.
Differences between Google Cloud and Google Cloud Platform
Although the terms Google Cloud and Google Cloud Platform (GCP) are frequently used interchangeably, the following key distinctions set them apart:
Google Cloud is a general umbrella term that encompasses all of Google's cloud-based services. This includes GCP and products related to Google's ecosystem, such as Google Workspace -- formerly G Suite -- and Google Maps, which are readily available for users globally.
Google Cloud Platform specifically pertains to Google's suite of cloud computing services. This includes offerings such as App Engine, Cloud Storage, BigQuery and Looker Studio, which are designed for developers and businesses seeking to build, manage and analyze applications and data in the cloud.
While Google Cloud refers to the entire range of Google's cloud services, GCP focuses specifically on the infrastructure and tools for cloud computing.
Overview of Google Cloud offerings
Google Cloud offers services for compute, storage, networking, big data, ML and internet of things (IoT), as well as cloud management, security and developer tools. The cloud computing products in Google Cloud include the following:
- Google Compute Engine. Google Compute Engine is an infrastructure-as-a-service offering that provides users with virtual machine (VM) instances for workload hosting.
- Google App Engine. Google App Engine is a platform-as-a-service offering that gives software developers access to Google's scalable hosting. Developers can also use a software development kit to develop software products that run on App Engine.
- Google Cloud Storage. Google Cloud Storage is a cloud storage platform designed to store large, unstructured data sets. Google also offers database storage options, including Cloud Datastore for NoSQL nonrelational storage, Cloud SQL for MySQL fully relational storage and Google's native Cloud Bigtable database.
- Google Kubernetes Engine. GKE is a management and orchestration system for Docker container and container clusters that run within Google's public cloud services. GKE is based on Kubernetes, Google's open source container management system.
- Google Cloud's operations suite. Formerly Stackdriver, this set of integrated tools is for cloud monitoring, logging and reporting on the managed services driving applications and systems on Google Cloud.
- Serverless computing. Serverless computing provides tools and services for event-based workload execution, such as Cloud Run Functions for creating functions that handle cloud events, Cloud Run for managing and running containerized applications and Workflows to orchestrate serverless products and application programming interfaces (APIs).
- Databases. A suite of database products delivered as completely managed services, including Cloud Bigtable for large-scale, low-latency workloads; Firestore for documents; CloudSpanner as a highly scalable, highly reliable relational database; and CloudSQL as a fully managed database for MySQL, PostgreSQL and SQL Server.
Google Cloud offers application development and integration services. For example, Google Cloud Pub/Sub is a managed real-time messaging service that enables messages to be exchanged between applications. In addition, Google Cloud Endpoints enables developers to create services based on RESTful APIs and then make those services accessible to Apple iOS, Android and JavaScript clients.
Other offerings include Anycast domain name systems, direct network interconnections, load balancing, monitoring and logging services. Products such as Gmail and the generative AI Google chatbot Gemini also run on Google Cloud.
Higher-level services
Google continues to add higher-level services, such as those related to big data and ML, to its cloud platform. Google big data services include those for data processing and analytics, such as Google BigQuery for SQL-like queries made against multi-terabyte data sets. In addition, Google Cloud Dataflow is a data processing service intended for analytics; extract, transform and load; and real-time computational projects. The platform also includes Google Cloud Dataproc, which offers Apache Spark and Hadoop services for big data processing.
For artificial intelligence (AI), Google offers its Cloud Machine Learning Engine, a managed service that enables users to build and train ML models. Various APIs are also available for translating and analyzing speech, text, images and videos.
Google also provides services for IoT, including Google Cloud IoT Core. These managed services enable users to consume and manage data from IoT devices. The Edge Tensor Processing Unit provides dedicated hardware designed to accelerate ML and AI at the IoT edge.
Google Cloud provides the following tools to assist with data and workload migrations:
- Application Migration to the cloud.
- BigQuery Data Transfer Service to schedule and move data into BigQuery.
- Database Migration Service to enable easy migrations to Cloud SQL.
- Migrate for Anthos to help migrate VMs into containers on GKE.
- Migrate for Compute Engine to bring VMs and physical servers to Compute Engine.
- Storage Transfer Service to handle data transfers to Cloud Storage.
The Google Cloud suite of services is evolving, and Google periodically introduces, changes or discontinues services based on user demand or competitive pressures. Google's main competitors in the public cloud computing market are Amazon Web Services (AWS) and Microsoft Azure.

Benefits of Google Cloud
Google Cloud offers numerous benefits, making it an attractive choice for businesses and developers. Some key benefits of Google Cloud include the following:
- Flexible pricing. GCP provides significant cost savings by offering a flexible pricing model that enables businesses to pay only for the resources they use. It offers sustained use discounts and committed use contracts, which can further reduce costs for long-term projects. New customers also receive $300 in free credit to explore Google Cloud products and build a proof of concept.
- Helpful documentation. Google Cloud provides extensive documentation, including detailed guides, quick starts and tutorials to help users get started with various services. Each document is structured with an overview and a hands-on guide that walks the user through the feature or service.
- Scaling. With Google Cloud, it's easy to scale resources up or down based on demand. This is especially helpful for businesses with fluctuating traffic, as it ensures the resources aren't over-provisioned and extra resources are always available.
- Advanced data analytics and ML. Google Cloud provides strong data analytics and machine learning capabilities. For example, tools such as BigQuery enable data analysis, while services including AutoML and TensorFlow make it easier for developers to build and deploy ML models.
- Security and compliance. Google Cloud employs a multilayered security approach, including data encryption both in transit and at rest. The company regularly updates its security protocols, conducts routine checks and trains staff to ensure strong data protection. In the event of a breach, users are quickly notified and managed access features enable tracking of revisions and activities. Tools such as BeyondCorp and Confidential Computing protect data, minimize risk and assist businesses in maintaining compliance with industry regulations.
- Live migration. Google Cloud's live migration feature enables VMs to move between physical hosts without downtime, ensuring high availability and reliability. This is ideal for businesses that require consistent uptime and performance.
Challenges of Google Cloud
Along with its many benefits, Google Cloud also faces some challenges in the competitive cloud market.
Key challenges of Google Cloud include the following:
- Cost management and optimization. Google Cloud's pricing structure can be complex, making it difficult for businesses to budget and manage cloud computing costs accurately. Since a VM doesn't include all necessary components, such as storage and bandwidth, quotes can be misleading if businesses aren't aware of all the resources they will be using. To optimize spending, businesses should assess their storage needs thoroughly, utilize lifecycle management to transition data to more affordable or archival classes, and monitor usage regularly.
- Limited support options for enterprise tools. While Google Cloud is a strong contender in AI, ML and big data, it can lack the same extensive support for enterprise software integrations and legacy tools as platforms such as AWS and Azure.
- Compliance and data governance complexities. As with any cloud vendor, ensuring data governance and compliance in Google Cloud can be complex. Organizations must align data with regulatory and internal policies, including access controls and privacy regulations. Additionally, businesses should understand Google's security frameworks, document data practices and conduct regular audits to maintain compliance.
- Limited customization. GCP caters to a broad range of users, which can result in less granular control over certain services compared to more highly customizable platforms.
Google Cloud use cases
Google Cloud supports a wide range of use cases across various industries. The following are some notable applications of Google Cloud:
- Application hosting and development. The Google Cloud platform is used extensively in application development and hosting. With tools such as Google App Engine and Google Kubernetes, users can build scalable apps, deploy web applications and manage containerized applications effectively.
- Data storage and management. Organizations use Google Cloud for secure and scalable data storage. The platform offers tools such as BigQuery and Cloud Dataflow for data analytics and management, enabling businesses to efficiently store, analyze and derive insights from large data sets.
- Hybrid and multi-cloud options. Google Cloud supports hybrid cloud environments, enabling organizations to integrate on-premises infrastructure with cloud resources seamlessly. This flexibility enables businesses to optimize their cloud strategy and also avoid the risk of vendor lock-in.
- Google Distributed Cloud. GDC extends Google's cloud services to locations outside traditional data centers, enabling businesses to deploy and manage applications closer to their data sources. In 2024, Google launched its first distributed cloud-edge air-gapped appliance. GDC meets data residency, compliance and low-latency requirements while integrating seamlessly with Google Cloud services.
- IoT. GCP facilitates the development of IoT applications by providing workflows that securely connect, manage and ingest data from multiple devices. This enables businesses to harness real-time data to support various use cases, including smart manufacturing, connected vehicles and predictive maintenance.
Google Cloud pricing options
Like other public cloud offerings, most Google Cloud services follow a pay-as-you-go model with no upfront payments; users only pay for the cloud resources they consume. Specific terms and rates, however, vary from service to service.
Discounts are available for some services with long-term commitments. For example, committed use discounts on Compute Engine resources such as instance types or graphics processing units can yield discounts of up to 50%, with discounts of up to 70% for memory-optimized machine types. Google Cloud adopters should consult with Google sales staff and in-house cloud architects and use cloud pricing estimation tools, such as Google Cloud pricing calculator, to estimate the pricing of prospective cloud deployments.
Google Cloud competitors
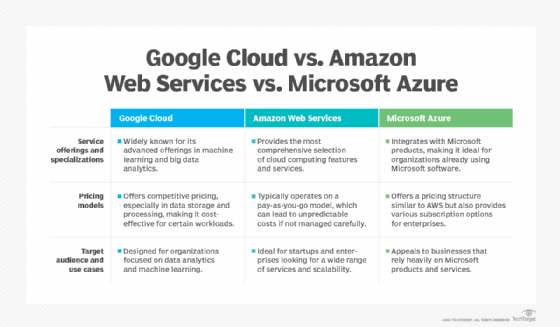
Google Cloud faces strong competition from other public cloud providers -- mainly AWS and Microsoft Azure. The following are the key differences among AWS, Azure and Google Cloud:
AWS
- AWS is the oldest and most mature public cloud that emerged as a public service in 2006.
- It typically offers the broadest range of general tools and services and possesses the largest market share by appealing to a broad customer base ranging from individual developers to major enterprises to government agencies.
- AWS offers essential services such as computing, storage, databases, ML and analytics, catering to various applications and industries.
- AWS employs a pay-as-you-go pricing model and various pricing tiers along with discounts for long-term commitments.
Microsoft Azure
- Microsoft Azure appeared in 2010 and has proven particularly attractive to Windows and Microsoft-based environments. This has made it easier to transition workloads from data centers to Azure, and even build hybrid environments.
- Azure is the second-largest public cloud, often catering to larger enterprise users.
- Its pricing is competitive and often aligns closely with AWS. It provides discounts for enterprise agreements and offers a free tier for certain services, making it accessible for startups and small businesses.
- Azure is favored by enterprises, especially those with existing investments in Microsoft technologies.
Google Cloud
- Google Cloud also appeared in 2010 and is currently the smallest of the three major public clouds. However, it has developed a strong reputation for its compute, network, big data and ML and AI services.
- Google Cloud is known for its straightforward pricing structure and sustained use discounts, which automatically apply as usage increases.
- Google Cloud is often preferred by organizations focused on data analytics and ML. It can be a popular option among tech-savvy companies and startups as they prioritize cutting-edge technology.
However, the differences among providers are eroding, as all three public clouds are evolving to offer similar suites of services and capabilities. For example, Google Cloud's Config Connector used for app modernization is matched by AWS Controllers for Kubernetes and Azure Service Operator. There are only a handful of Google Cloud services not matched by an AWS and/or Azure analog. As examples, Google Cloud's Binary Authorization service for container security and the Error Reporting tool for software developers currently have no matching services from AWS or Azure.
Cloud adopters should carefully investigate and experiment with the suite of services each cloud provider offers before committing to a particular platform. However, multi-cloud environments are increasingly common among enterprise users.
Google Cloud certification paths
Public clouds offer hundreds of individual services, enabling users to assemble comprehensive cloud infrastructures capable of deploying, securing and monitoring complex enterprise workloads. Effective use of cloud services depends on the users' knowledge and expertise surrounding those offerings. This has driven the need for cloud training and certification, and Google offers training programs and certifications related to Google Cloud.
Training options offer free or low-cost onramps to Google Cloud services and approaches. Cloud users can explore a range of training options, including the following:
- Cloud infrastructure.
- Application development.
- Kubernetes, hybrid and multi-cloud.
- Data engineering and analytics.
- API management.
- Networking and security.
- Machine learning and AI.
- Cloud business leadership.
- Google Workspace.
Google also promotes and endorses certifications for cloud users who choose to validate their expertise on a professional level. Certification paths are typical for cloud professionals as part of ongoing professional development or as a requirement for professional cloud employment. Employers also use certifications as vital benchmarks for measuring prospective candidates' capabilities and knowledge levels for cloud-related jobs. Google currently offers the following three levels of Google Cloud certification:
- Foundational certification. This introductory certification conveys a wide range of basic knowledge and concepts of Google Cloud resources, tools and services. It's suited to new or non-technical cloud users with little experience with Google Cloud.
- Associate certification. This main practical certification for Google Cloud enables users to focus on issues such as deployment, monitoring and maintenance of workloads running in Google Cloud. This certification is suited for cloud engineer roles.
- Professional certifications. These top-tier certifications validate advanced concepts and skills in design, execution and management within Google Cloud. Participants seeking a professional certification should have at least three years of industry experience, including at least one year of hands-on experience with Google Cloud. Professional certifications currently cover the following nine specializations: Cloud Architect, Cloud Database Engineer, Cloud Developer, Data Engineer, Cloud DevOps Engineer, Cloud Security Engineer, Cloud Network Engineer, Google Professional Workspace Administrator and Machine Learning Engineer.
Google Cloud Storage and Google Drive are the two primary storage options offered by Google. Compare their key differences including storage types, space and features to determine which is best suited for your business needs.
Continue Reading About What is Google Cloud?
Dig Deeper on Cloud infrastructure design and management
-
![]()
Google GCP Solutions Architect Certification Exam Dump and Braindump
By: Cameron McKenzie
-
![]()
Google Professional Cloud Architect Sample Questions
By: Cameron McKenzie
-
![]()
Google Cloud Architect Certification Practice Exams
By: Cameron McKenzie
-
![]()
GCP Google Cloud Developer Certification Sample Questions
By: Cameron McKenzie



