SODA Foundation launches to unify open source data management
A new Linux Foundation-sponsored group will support open source data management and promote interoperability between applications and data sources, on premises or cloud-based.
Impediments to connecting and managing disparate data sources are many. The new SODA Foundation offers the promise of more interoperability in open source data management so users can connect to applications and data, whether on premises or in the cloud.
SODA stands for SODA Open Data Autonomy. The group was introduced at the Linux Foundation's Open Source Summit North America virtual conference on June 29.
The nascent foundation then held its own mini summit on July 2. Participating members and users outlined the goals and components that make up the open source data effort, which is an evolution of the Linux Foundation's OpenSDS (open software-defined storage) project that started in 2016. Among members of the group are Huawei, Fujitsu, NTT Communications and Sony.
The OpenSDS project leadership realized in recent years that managing storage is only part of the challenge for organizations, which also need to manage data wherever it resides.
Many data silos exist in his organization and others and it's not easy to bring them all together, said Yuji Yazawa, principal engineer at Toyota Motor Corporation and chair of the end user advisory committee for the SODA Foundation, during a recorded session at the Open Source Summit.
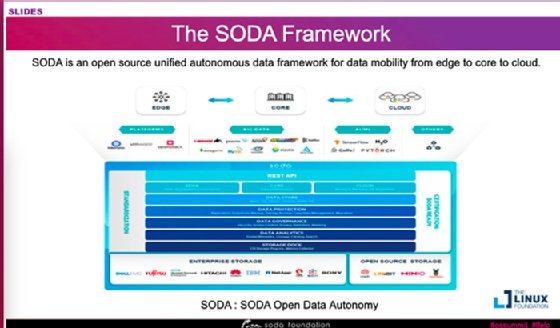
SODA is an open source unified autonomous framework for data mobility from edge to core to cloud.
Yuji YazawaPrincipal engineer, Toyota Motor Corporation
Yazawa noted that in his experiences at Toyota and previously at Yahoo Japan, the lack of standardized interfaces for data management tends to lead to lock-in. He said that's why he's interested in the SODA Foundation's mission to foster an ecosystem of open source data management tools and capabilities.
"SODA is an open source unified autonomous framework for data mobility from edge to core to cloud," Yazawa said.
Moving from OpenSDS to SODA Foundation
In a keynote session during the SODA Foundation mini summit, Rakesh Jain, co-chair of the SODA Foundation technical steering committee and senior technical staff member at IBM, outlined the open data fabric architecture approach that the group is taking.
The SODA Foundation integrates projects that provide core elements needed to enable a unified data framework, including an infrastructure manager, controller and multi-cloud plugins, Jain said.
He noted that the core projects enable users to access different data storage repositories including VMware on premises as well as public cloud with AWS, Azure and Google. There are also components for data lifecycle management, governance, security and analytics.
Beyond the core project, Jain noted that the SODA Foundation is fostering an ecosystem of projects that help to expand the idea of an open data fabric.
The SODA Foundation's open data framework integrates data and storage management components to help enable data mobility.
Creating a single data framework with the SODA Foundation
In the same keynote session, Sanil Divakaran, a member of the technical steering committee, noted that the foundation is aiming to define a single data network framework, in which any application can potentially connect to any data or storage back end in an interoperable approach.
Each type of application deployment approach, whether VMware virtual machines, Kubernetes and containers, or public cloud, has its own method of connecting to data storage back ends and enabling data management. SODA's open data framework enables an abstraction, so a user will transparently be able to connect and manage the different data sources, regardless of the underlying deployment approach.
"We want to provide key features like data lifecycle and data protection in a unified framework," Divakaran said. "So the application framework can focus on application business logic and the storage can simply focus on the storage, so we connect between the two and provide a unified interface."