
Getty Images
NoSQL database types explained: Column-oriented databases
Learn about the uses of column-oriented databases and the large data model, data warehouses and high-performance querying benefits the NoSQL database brings to organizations.
Organizations need databases that can meet increasing demands for data storage and accommodate data variety efficiently. Column-oriented databases fit this description.
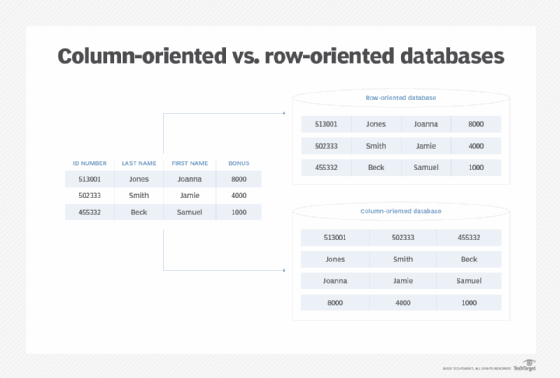
Columnar databases are a type of NoSQL database built for highly analytical, complex-query tasks. Unlike relational databases, columnar databases store their data by columns, rather than by rows. These columns are gathered to form subgroups.
The database does not have fixed key and column names. Columns within the same column family, or cluster of columns, can have a different number of rows and can accommodate different types of data and names.
Column-oriented databases are effective for large data models, such as data warehouses, or when there is a need for high performance or handling intensive querying.
How column-oriented databases work
Relational databases have a set schema and they function as tables of rows and columns. Wide-column databases also have rows and columns that are not fixed within a table; they have a dynamic schema. Each column is stored separately. Related columns form column families and the database stores column families separately.
The row key is the first column in each column family and serves as an identifier of a row. Each column after that has a column key (name) that identifies columns within rows and enables column queries. The value and the timestamp come after the column key, leaving a trace of when the data was entered or modified.
Not every column of a column family has the same number of rows. They might share their name but the database contains each column within one row and does not run across all rows.
Each column of a relational database has the same number of rows, but some of the fields have a null value or appear to be empty. In wide-column databases, empty rows simply do not exist for a particular column.
The column families reside in a keyspace. Each keyspace holds an entire NoSQL data store and has a similar role or importance that a schema has for a relational database. But NoSQL data stores have no set structure, so keyspaces represent a schemaless database containing the design of a data store and its own set of attributes.
Column family types
Column-oriented databases have two main family types:
- Standard column family is like a table. It contains a key-value pair where the key is the row key, and the values use their names as identifiers.
- Super column family represents an array of columns. Each super column has a name and a value mapping the super column out to several different columns. The database joins related super columns under a single row into super column families.
Advantages of column-oriented databases
Organizations that handle big data and invest in analytics should consider the strengths of column-oriented databases. They excel in efficiently storing and querying large data sets for the following reasons:
- Scalability. A column database's primary advantage is the ability to handle big data. Depending on the scale of the database, it can cover hundreds of different machines. Columnar databases support massively parallel processing, employing many processors to work on the same set of computations simultaneously.
- Compression. Compressing large amounts of data saves storage space.
- Very responsive. The load time is minimal and columnar databases perform queries quickly, making them practical for big data and analytics.
- Aggregation performance. Columnar databases can scan and aggregate large volumes of data in columns efficiently. Aggregations such as averages and sums are faster because the database engine reads only the necessary columns, not entire rows. Aggregations that need to read the entire column before updating a value -- such as a distinct count or sorting -- are generally much faster than row-oriented databases.
- Flexibility. In general, column-oriented databases are less flexible than row-oriented architectures for general-purpose database work. However, the columnar architecture is more adaptable in certain situations. For example, adding or removing columns as schemas evolve is generally easier than in a row-based system because only the affected column must change. In a traditional database, every row of data needs updates. Schema flexibility can be valuable when analytic requirements change frequently or evolve over time.
Disadvantages of column-oriented databases
Column-oriented databases have several downsides that users must navigate. In addition to having potential security vulnerabilities, they struggle to support the following:
- Online transactional processing. Column databases are not as efficient with online transactional processing as they are for online analytical processing (OLAP). They can analyze transactions, but struggle to update them. A common strategy is to have the column database hold the data required for business analysis and have a relational database store the data in the back end.
- Incremental data loading. Column-oriented databases can quickly retrieve data for analysis, even when processing complex queries. Incremental data loads are not impossible, but columnar databases do not perform them in the most efficient way. It must scan the columns to identify the right rows and then conduct another scan to locate the modified data that requires overwriting.
- Row-specific queries. The disadvantages of column databases all boil down to the same issue -- using the right type of database for the right purposes. Row-specific queries introduce an extra step of scanning the columns to identify the rows and then locating the data to retrieve. It takes more time to get to individual records scattered in multiple columns, rather than accessing grouped records in a single column. Frequent row-specific queries might cause performance issues by slowing down a column-oriented database, which defeats its purpose of providing information quickly.
- Security. Columnar databases are slightly more vulnerable to some security issues than other types of databases because they rely on data compression -- especially of commonly repeated values -- to improve performance. Compression can conflict with encryption. Encryption might be less effective if compression occurs first because patterns in the compressed data might remain. However, encrypting the data first can limit the performance benefits from compression. One mitigating factor for potential vulnerabilities is that the most sensitive data, such as unique identifiers, are less likely to effectively compress.
Use cases for column-oriented databases
Column-oriented databases have potential applications across data warehouses, AI and machine learning (ML):
- Data warehouses. The classic data warehouse architecture improves the performance of aggregations and analytic queries over historical data with relational databases. A column-oriented database improves efficiency because it only reads columns relevant to a query, reducing the I/O overhead considerably and speeding up queries.
- Business intelligence. On the server, BI tools often run similarly to data warehouses and have similar advantages to column-oriented databases. Many modern BI applications are desktop applications for data and business analysts. The compression of column-oriented architectures enables the storage and processing of large volumes of data in memory, offering analytics capabilities that were previously only available on powerful servers.
- Machine learning. Excellent analytics performance is a general ML advantage, but some scenarios benefit from features of column-oriented architectures. For example, columnar databases enable efficient analysis of trends and patterns across specific columns such as timestamps and metrics because they can handle large volumes of sequential data. They can focus on the relationships between specific columns of data, which helps identify anomalies.
- AI. The data architecture commonly associated with AI is a vector database. However, column-oriented databases have uses in important stages in the data preparation workflow for AI. It is common for data engineers to create new data features for AI systems to train on. Examples include calculating the average, median, minimum or maximum values, or ratios between values. Many data sets have numerous missing values or sparse data. Column stores perform exceptionally well in such scenarios.
- IoT. IoT devices continuously generate streams of data, often in structured formats such as sensor readings for temperature, humidity, location or device status. Each metric can be a separate column in a database, making column-oriented systems a natural choice.
Column-oriented database examples
The increasing demand for high-performance analytics on large data sets increases the demand for columnar databases. The choice between open source and commercial columnar databases often depends on budget, required features, in-house expertise and specific uses. Many organizations use a mix of both; they might use open source tools for some applications and commercial systems for others.
Here are a few examples of the most popular systems, both open source and commercially licensed, typically used for the most common use cases. Tools were selected using insight from G2 review rankings, research from IT Market Strategy and additional market research by TechTarget editors. This unranked list is in alphabetical order.
Amazon Redshift is a fully managed, cloud-based columnar database that organizations often use for data warehousing. Redshift is for large-scale analytics and business intelligence use cases. It handles complex queries across petabyte-scale data sets using massively parallel processing. A key advantage of Redshift is that it integrates seamlessly with the AWS ecosystem of services and applications, and it supports high-speed queries, fast data compression that reduces storage size by up to 35%, and elastic scaling. Amazon offers pay-as-you-go pricing, which can be cost-effective and helps make Redshift a popular system for use alongside other databases. It often acts as a cost-efficient store for older, less-frequently-accessed data in data warehousing, reporting and analytics scenarios.
Apache Cassandra has on-premises, cloud and hybrid deployment configurations. Its open source license offers community support through Planet Cassandra, which has resources from monthly global meetups to regular onboarding meetings for new users. However, the learning curve for initial setup and optimization is steep. The highly scalable and fault-tolerant system can handle large volumes of data distributed across multiple nodes. Cassandra has tunable consistency levels to customize the tradeoff between data that is consistent across all servers or available for use with very low latency. It's popular for IoT scenarios with streaming data and its reduced cost of ownership.
ClickHouse is an open source columnar system initially developed by the Russian internet giant Yandex. It excels at OLAP and features a highly available, high-performance architecture for mission-critical analytics in real-time advertising, spot-pricing and telecommunications. ClickHouse can handle large-scale data sets with real-time data ingestion and fast query performance. Limitations include the lack of native full-text search and a more limited community and ecosystem than Apache Cassandra, a drawback for open source software.
Microsoft Azure Cosmos DB is a multimodel architecture, which means it can support various data models, such as document, key-value and graph databases. Column-oriented is one of the most important and commonly used configurations. The cloud-based database offers multiple APIs for developers, including SQL, MongoDB and Cassandra. To support global applications, Cosmos automates replication and has tunable consistency levels. It's a popular choice for web applications, especially mission-critical ones across multiple regions.
Donald Farmer is a data strategist with 30+ years of experience, including as a product team leader at Microsoft and Qlik. He advises global clients on data, analytics, AI and innovation strategy, with expertise spanning from tech giants to startups. He lives in an experimental woodland home near Seattle.
Alex Williams is an independent IT consultant and owner of Hosting Data UK. He has almost a decade of experience as a developer and is knowledgeable in IT systems, cybersecurity, data management, internet privacy and finance.





