Data architecture vs. information architecture: How they differ
Data architecture and information architecture are distinct but related disciplines that work in tandem to support an enterprise's data and business strategies.

Many people believe data architecture and information architecture are one and the same. But this misconception among data management leaders and their teams results in poorly designed architectures that can't handle either data or information effectively.
The problem starts with confusion between data and information, which are related but different. Data is numbers, characters or other types of values collected in IT systems and business applications. Information is data in context.
Without context, a raw number is meaningless, but with it, the number could represent the amount of a customer's order, total monthly sales in a geographic region or a manufacturing plant's weekly production level, to cite a few examples. Further context would reveal more about the who, what, when, where and how of that number, providing additional information to track and analyze.
As a result, an organization needs both a data architecture and an information architecture to support business processes and decision-making. To help corporate teams create a solid architectural framework, here's how the two architectures -- and the roles of data architects and information architects -- differ and relate to one another.
Data architecture vs. information architecture
An information architecture defines a framework for using the information an enterprise generates to make decisions and manage business operations. The primary building blocks of an information architecture are the organization's applications, business processes and analytics systems, as well as its internal information workflows and external ones with customers, suppliers and business partners.
Business requirements are used to develop a blueprint for the information architecture, which includes a combination of conceptual data models, logical data models and business process models. Enterprise applications, whether developed internally or purchased from vendors, must be configured to support information delivery based on these models. Taxonomies and ontologies are also key components of information architectures, and UX design and usability testing are often incorporated into the development process to optimize navigation and information retrieval.
A data architecture provides the foundation for the information architecture by documenting how the required data is collected, stored, integrated and managed. In a modern data architecture, data is ingested and stored in file systems, databases and other data platforms that span cloud, on-premises and hybrid environments. The traditional building blocks of a data architecture are a data warehouse, an operational data store and BI systems. More sophisticated data architectures add technologies such as data lakes, data lakehouses, NoSQL databases, AI and machine learning platforms, and real-time analytics systems.
A best-in-class data architecture implements data governance processes with supporting data quality and master data management initiatives. It also requires a data integration framework that enables a combination of integration capabilities, such as the following:
- Traditional extract, transform and load (ETL) processes.
- ELT methods that reverse the load and transform steps, an alternative approach often used in big data systems.
- Data pipelines, data streaming and API connectors.
Like information architecture, data architecture has close ties to the data modeling process. In this case, that involves creating physical data models based on conceptual and logical ones developed earlier in the process.
How are data architecture and information architecture related?
An effective data architecture needs an information architecture and vice versa.
For example, the data and business process models that an information architecture is based on define a company's customers and partners, as well as how the business interacts with them in marketing, sales and support activities. The data architecture translates these models into database designs and the data elements used to collect, store and update relevant data. It also includes processes for cleansing, transforming, curating and governing data to produce useful information.
Oversimplifying how data is transformed into information is a big shortcoming in data architectures. All too often, IT and data management teams think data simply needs to be moved or piped from source to target systems, failing to recognize the need for different data contexts to support specific applications.
Without the right context, analytics and reporting tools won't provide the correct insights. Even worse, end users might export the data to spreadsheets in an attempt to create useful information. Doing so could provide the context they need, but it's an unproductive use of their time that also creates information silos.
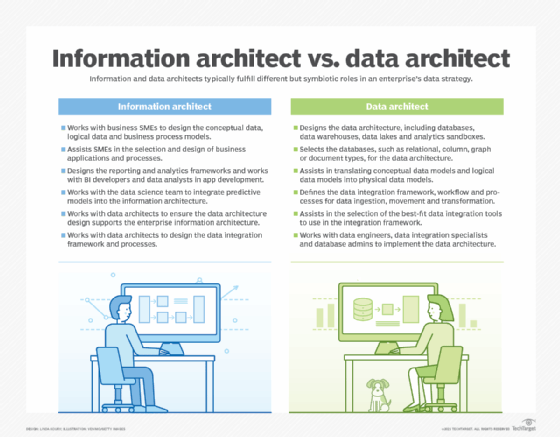
What information architects do
Information architects must understand the business and the information it needs. They then ensure that the required information is available in business applications and analytics and reporting systems.
An information architect's responsibilities typically include the following:
- Works with business subject matter experts (SMEs) to design the conceptual and logical data models and the business process models that underpin the information architecture.
- Assists SMEs in selecting and configuring business applications and designing business processes.
- Designs the framework for analytics and reporting platforms.
- Works with BI developers and data analysts to create analytics and reporting applications.
- Works with data scientists to support predictive modeling, machine learning and AI initiatives and to integrate the analytical models they create into the information architecture.
- Works with data architects to ensure the data architecture design supports the information architecture and to design the data integration framework.
What data architects do
Data architects gather business requirements for data based on an enterprise's current operations and long-term roadmap. In addition to planning technology deployments, they create data flow diagrams, documents that map data usage to business processes and other artifacts that describe a data architecture conceptually. They also identify areas where data issues are constraining operations, reducing productivity or inhibiting business growth so the problems can be resolved.
A data architect's responsibilities typically include the following:
- Designs the data architecture's technology framework, including data platforms and a combination of BI, AI and advanced analytics systems.
- Selects the types of databases, such as relational, columnar, graph or document technologies, and other data platforms that are the best fit for the data architecture.
- Assists data modelers in translating conceptual and logical data models into physical data models.
- Designs the data integration framework along with workflows and processes to enable data ingestion, movement and transformation.
- Assists in selecting the best-fit data integration tools to use in the integration framework.
- Works with data engineers, data integration specialists, database administrators and other members of the data management team to implement the data architecture.
Data strategy's reliance on data and information architectures
A comprehensive data strategy sets out a vision for how data will enable a company's business strategy and support its ongoing operations. Rather than being viewed as a byproduct of business activities, data is recognized as a corporate asset that must be managed effectively if the organization is to be successful. A data strategy includes timelines, resource plans and financial justifications for the investments required to achieve its objectives. Together, information and data architectures serve as the blueprints for implementing the data strategy.
All three must evolve in tandem with the evolution of the business and the market it's in. Technology changes also influence how they're maintained and updated. A key to success is recognizing that change must be built into the fabric of the data strategy and both the data architecture and information architecture. Managing it effectively provides an ongoing opportunity to increase the use of data and information in an organization -- and, ultimately, their business value.
Editor's note: This article was originally published in 2021. TechTarget editors updated it in December 2025 for timeliness and to add new information.
Rick Sherman, who died in January 2023, was founder and managing partner of Athena Solutions, a BI, data warehousing and data management consulting firm. He had more than 40 years of professional experience in those fields.






