HPE Discover highlights AI factories, OpsRamp and Morpheus
AI factories, Morpheus and OpsRamp promise to become central parts of HPE's hybrid cloud strategy.

- Torsten Volk,
-
Omdia
Intelligence and advice powered by decades of global expertise and comprehensive coverage of the tech markets.
HPE Discover 2025 was all about transforming IT organizations from their current state to a state where they can harness AI capabilities for any project.
In his keynote at the conference, HPE CEO Antonio Neri called AI "the ultimate hybrid workload" and clearly stated HPE's key mission of providing organizations with the hardware, software and IT services to achieve operational excellence to run AI workloads anywhere.
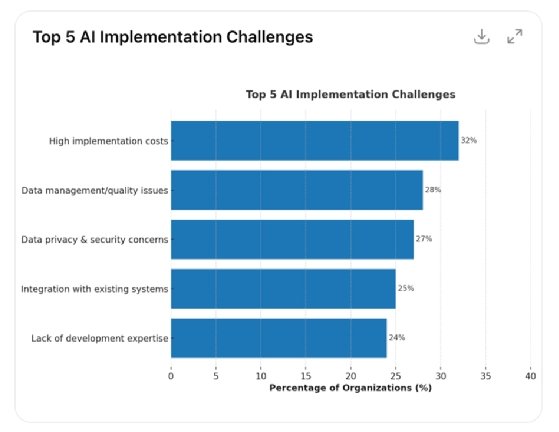
HPE aims to help enterprise customers address key AI-related challenges, including implementation cost, data quality and access, data privacy, system integrations and lack of available talent.
Organizations that can conclusively address these challenges are in a position to leverage AI without operational barriers whenever needed. HPE has identified the concept of "operational excellence" to achieve this.
Neri's keynote, and Discover 2025 overall, were laser-focused on operational excellence. AI development, management and operations tend to place a previously unknown strain on IT operations, relentlessly revealing gaps in centralized management, a lack of automation and orchestration, inconsistent workload configuration, and fragmented visibility across hybrid environments.
But how is HPE planning to get us there?
HPE CloudOps: Getting operations ready for AI
The AI factory concept, also championed by Nvidia and Dell, aims to bring together the software, hardware and services needed to develop, deploy and operate AI-driven application capabilities.
AI workloads often need to run at the location of the data for compliance and close to the end user to reduce latency. This means AI factories require a flexible hybrid operating model. A turnkey AI factory aims to enable organizations to scale AI projects across teams, business units and locations by providing the guardrails to ensure governance, maintain compliance and manage the AI lifecycle in a compliant and cost-effective manner.
The resulting high level of flexibility and scalability lays the foundation for providing developers with a unified API layer they can code against, without having to worry about differences in infrastructure, databases and application runtimes. This same set of unified APIs enables the operations team to deploy, update or scale the application without having to ask the development team for code and configuration changes.
HPE's new CloudOps Software suite aims to provide the control plane, observability and resiliency layers that are at the center of the AI factory, connecting the AI infrastructure layer to AI runtimes and workloads as needed.
HPE Morpheus: The control plane for the hybrid AI factory
HPE Morpheus, acquired in August 2024, is the hybrid cloud control plane for HPE's AI factory and one of three central parts of HPE's new CloudOps Software. It is great to see Morpheus' focus on truly simplifying operations across AWS, Azure and Google Cloud Platform, as this is where a lot of inefficiencies, compliance problems, reliability issues and cost overruns happen. Providing a unified interface for the policy-driven automation, orchestration and operations management aims to enable organizations to take advantage of their favorite services on each cloud, without adding significant operational overhead.
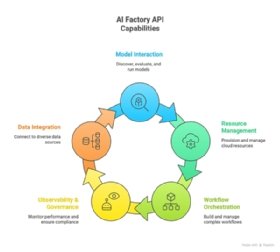
Morpheus lets platform engineers offer a universal set of developer APIs without developers having to worry about adjusting their deployment code and configuration for different deployment scenarios. Of course, this also means that DevOps engineers can add deployment automation code to their CI/CD pipeline without worrying about cloud-specific details.
While Morpheus is generally agnostic in that it supports most hypervisors, including Kubernetes and bare metal, it comes with its own KVM-based hypervisor. HPE aims to convince VMware customers of the advantage of its pricing model, based on CPU sockets instead of cores. As the number of cores per socket roughly doubles every three years, it makes intuitive sense that a per-socket pricing model keeps the VM cost predictable.
While the socket-based pricing model seems attractive, HPE will have to prove that Morpheus can successfully onboard and manage business-critical virtualization workloads at scale. This is no easy exercise, as the "secret sauce" of many virtualization deployments does not lie in the hypervisor itself, but in the management and tools surrounding it. Differences in network configurations, security policies or storage architecture can quickly cause issues in application performance, resilience or compliance.
Ultimately, combining the management, orchestration and automation of virtualized applications with those of cloud-native ones makes sense, as it can simplify operations, prevent errors and help with compliance reporting. At the same time, HPE needs to convince enterprise customers to take a leap of faith in the company's new hypervisor platform.
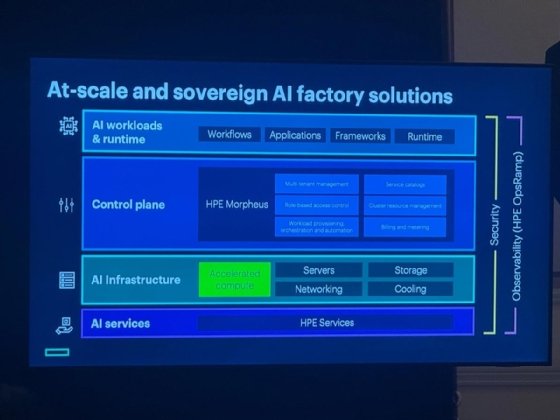
From a developer's perspective, Morpheus provides features such as self-service provisioning of infrastructure resources, including the underlying network, storage and compute hardware; deploying applications or AI models; automating workload orchestration across hybrid and multi-cloud environments; managing database instances; and monitoring resource usage. The ability to programmatically access all these lifecycle management capabilities is key to overall scalability as operators, virtualization admins, DevOps engineers, security engineers, site reliability engineers (SREs) and other staff roles can complete their specific tasks from their existing favorite tools or through the Morpheus GUI.
HPE clearly understood the flexible character of the Morpheus architecture and seems determined to continue to invest in this platform.
Ramping up with OpsRamp
Phanidhar Koganti, senior distinguished technologist at HPE's hybrid cloud business unit, said the company is "all about operational excellence."
Koganti, who previously served as an Amazon Elastic Compute Cloud principal of product, said, "At AWS, for example, if we didn't have enough visibility, we didn't release the product." He calls this "MVO" or minimum viable observability, which is as important of a release gate as the set of minimum viable product features. Proactively recognizing and preventing health and performance issues is a key ingredient of operational excellence, and this is what OpsRamp, the observability layer of the HPE CloudOps Software suite, focuses on.
One of OpsRamp's central slogans is "Smart decisions start with good data." OpsRamp aims to eliminate data silos by ingesting and consolidating full-stack telemetry data from over 3,000 enterprise sources, such as IT service management tools, infrastructure monitoring platforms, security platforms, public and private clouds, application management tools, AI models and network equipment.
Unifying these different telemetry data streams creates the foundation for the impactful use of data analytics and AI capabilities to ensure the health and performance of application stacks. The more comprehensive the context that an AI model has available, the more accurate its predictions, insights and recommendations will be.
Like Morpheus, OpsRamp offers role-based interfaces to make it as easy as possible for the different user personas to benefit from. DevOps engineers get visibility into the health and performance of the CI/CD pipeline, platform engineers can integrate observability templates into the organization's developer platforms, and SREs can enable proactive incident detection and automated remediation.
OpsRamp uses OpenTelemetry and eBPF to standardize and automate contextualized data collection. The automated mapping of business services to their underlying infrastructure enables the OpsRamp AI to prioritize issues based on their estimated application and business impact. In a next step, admins can automate routine operations tasks for routine tasks or remediation workflows.
Of course, there is a copilot based on generative AI that enables natural language queries for human admins to look for specific patterns in the entirety of the collected operations data. For example, an admin could ask questions like, "Which applications will experience downtime if I restart the following MongoDB database nodes now?" Or better, "When would be the best time for me to reboot the following MongoDB database nodes to minimize downtime?"
OpsRamp answers these questions using generative AI to query the service map that shows all applications that use a MongoDB instance running on the cluster in question. In addition, the AI can look at previous application downtime where the root cause was diagnosed as related to MongoDB. It might then find that as long as no more than one node is rebooted, the apps relying on this database do not experience any downtime. OpsRamp then provides this key insight and might ask the administrator if it should create and schedule a script that reboots the desired MongoDB nodes.
AI's ability to use large language models fine-tuned on historical data and "understanding" the vertical and horizontal interdependencies of applications, databases and business services is key for operational excellence, as it shifts the focus of IT operations staff toward proactively creating policies and automations, instead of spending the majority of their time on firefighting. The more historical operations data that is available and the more complete this data is, the more quickly OpsRamp can detect even subtle correlations, based on seemingly random co-occurrences of small irregularities that might lead to big problems that end up in downtime -- hours, days, weeks or even months down the road.
While Morpheus and OpsRamp seemed to be relatively minor acquisitions at the time, they have become the central backbone of HPE's AI factory platform. Both tools integrate with a wide range of software and hardware elements to prevent operational silos. Both tools are all about automating and proactively optimizing complex hybrid cloud environments. And both tools focus on appealing to a wide range of developer and operator personas. Together with Zerto, HPE's platform for ransomware resilience, data protection and disaster discovery, Morpheus and OpsRamp promise to become a central part of HPE's hybrid cloud strategy.
Torsten Volk is a principal analyst at Enterprise Strategy Group, now part of Omdia, covering application modernization, cloud-native applications, DevOps, hybrid cloud and observability.
Enterprise Strategy Group is part of Omdia. Its analysts have business relationships with technology providers.







