Fog computing vs. edge computing: What's the difference?
Fog computing vs. edge computing -- while many IT professionals use the terms synonymously, others make subtle but important distinctions between them.
The decentralization of computing is changing the way businesses collect, store, process and move data. Rather than housing everything in one central data center, emerging architectures are putting compute and storage resources outside of the data center and closer to the points where data is collected. The basic ideas are called fog computing and edge computing. But the terminology spawned by this paradigm shift can sometimes be confusing. Let's detail the concepts and take a closer look at their differences.
What are fog and edge computing?
Fog and edge computing share an almost identical concept: to move computing and storage away from the confines of a centralized data center and distribute those resources to one or more additional locations across the wider networked environment. Ideally, the decentralized resources will be closer to the point where work is being performed. This work could be data collection or user request processing.
Why does this matter? It's all about networks. A network can only handle a finite amount of data over time (bandwidth), and it takes finite time to move data across large geographic distances (latency). As businesses increasingly rely on ever-greater volumes of data to serve a larger global audience, networks struggle to handle the load, and users must wait longer for responses. The traditional way that businesses handle computing is slowly grinding to a halt. System and network architects have long sought a way to alleviate this burden from the network.
How do fog and edge computing work?
In a traditional computing approach, data that is collected at a remote location is then moved to a central data center where the data can be stored and processed -- usually for analytical purposes. But there is no rule that requires storage and computing to be centralized; that's just the approach that's evolved over decades.
Edge and fog computing seek to place storage and computing resources much closer to, or even at, the location where data is generated. This effectively reduces or eliminates the need to move high volumes of raw data across large distances through a network. The hardware and software used to perform computing tasks are essentially the same. For example, if a facility generates data and that data is processed directly at the edge on the facility site, there's no need to rely on the internet.
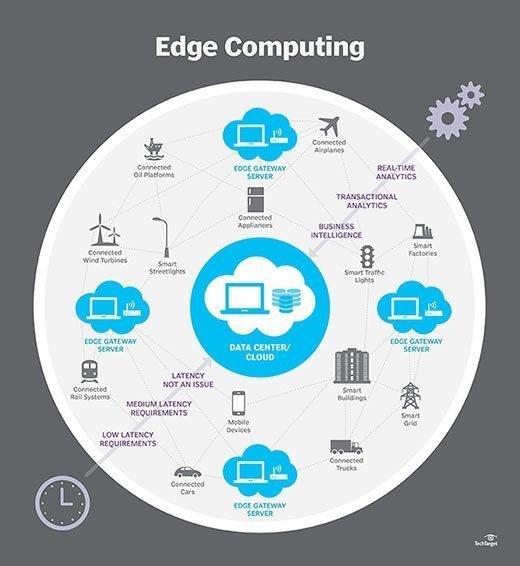
As a more detailed example, consider a remote factory with myriad machines outfitted with countless IoT devices used to monitor and control an array of physical conditions and operational parameters across the entire factory installation. In a traditional environment, all of that IoT device data would need to be moved across a WAN -- such as the internet -- to the business center, where the data can be processed and analyzed. By putting storage and compute resources in or near that factory, the data can be processed and analyzed more efficiently, typically without the congestion and disruptions of the internet, and only the analytical results need be available to the principal data center.
It's here that the notion of edge and fog computing start to diverge. Fog takes on a broader meaning and can involve storage and compute resources involved in any number of locations and interconnections. For example, if a factory sends data to a nearby colocated data center for processing or even to the local region of a cloud provider, that can also be interpreted as distributed computing and termed fog rather than the more precise idea of a physical edge.
What are the benefits of fog and edge computing?
There are four broad benefits to both fog and edge computing:
- Reduced latency and improved response time. The time needed to move large volumes of data is dramatically reduced or even eliminated, enabling better time to value for large data sets. If a business must make critical decisions or responses about that data, such as conditions at a major industrial facility, the reduced latency improves response times and avoids network disruptions.
- Improved compliance and security. Moving raw data across a public network can place that data at risk and potentially compromise the organization's compliance posture. Retaining data on-site or vastly reducing the distance that data needs to travel can shrink the potential attack surface for data snooping or theft. In addition, minimizing the amount of raw data exposed to a public network can potentially improve compliance, as long as the data is adequately secured at the edge or in fog nodes.
- Reduced costs and bandwidth. The bandwidth needs for large data sets are increasing faster than the general network capacity. High bandwidth requirements can impose a significant cost on the business. Avoiding high bandwidth needs can save internet costs.
- Greater autonomy and reduced disruption. Limiting WAN requirements can also avoid potential disruptions caused by WAN congestion and outages. If an edge facility stores and analyzes data on-site, it can continue to function even in an internet outage. For fog installations that might use outside sites for storage and computing, shorter WAN distances can reduce the effect of WAN disruptions
What are the drawbacks of fog and edge computing?
In spite of the advantages, however, there are several general disadvantages that fog and edge users can encounter:
- Increased complexity. A key benefit of traditional data center computing is that core resources and services are all in one place. Fog and edge computing undo this traditional paradigm and distribute resources and services to remote locations at and near the point where data is generated. This distributed computing architecture results in an environment that is more complex to design, implement and maintain.
- Security concerns. Security is not native to fog and edge technologies. Although security can be enhanced with fog and edge computing, better security is far from certain. Distributed computing architectures must address all aspects of security from data protection and encryption, to access and authentication, to physical security.
- Decentralized management. You can't manage what you can't see. Managing remote devices can pose problems for management tools, and it's important that any management tools support the presence of distributed infrastructures. This might ultimately involve multiple tools, such as cloud management tools, IoT configuration and management tools, and conventional data center management tools suited for remote or distributed infrastructures. Regardless of the actual tool set, the provisioning and management process will be more involved and time-consuming than with traditional centralized workflows.
How does fog computing differ from edge computing?
Fog computing vs. edge computing -- the difference between these two IoT-related concepts depends largely on whom you ask. Here, we break down three ways you might hear these emerging terms used and how the terms differ.
1. One and the same term. Many IT pros use the terms fog and edge computing broadly and interchangeably to refer to the distribution of compute and storage resources at or near the periphery of the network.
A decentralized edge or fog model enables data to be processed at or near its point of origin rather than at a distant, in-house data center or cloud. This results in lower latency for mobile and IoT devices and less network congestion overall.
2. Separate, but related terms. Other users employ more precise definitions that distinguish between fog computing and edge computing.
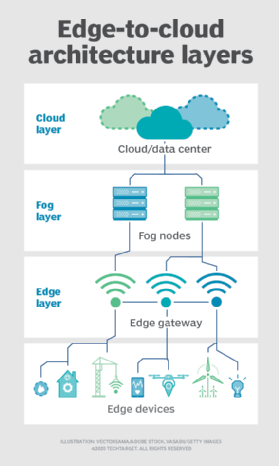
The OpenFog Consortium -- an industry group that includes Cisco, Intel, Microsoft and Princeton University and is now part of the Industrial Internet Consortium -- argues that fog refers to a broad IT architecture that creates a complex web of dynamic interconnections. These interconnections can extend from edge devices to the cloud; shared local compute and storage resources, such as IoT gateways; and other edge devices.
According to OpenFog, fog computing, which is also called fog networking and fogging, standardizes cloud extension out to the edge, encompassing all the space and activity between the two.
Edge computing, in this case, is more limited in scope, as it refers to individual, predefined instances of computational processing that happen at or near network endpoints. With this paradigm, edge computing can't create direct network connections between two endpoints or between an endpoint and an IoT gateway on its own; for that, it needs fog.
In OpenFog's view, fog computing always uses edge computing. Edge computing, however, might or might not use fog computing. Also, by definition, fog includes the cloud, while edge doesn't.
3. Terms depend on location. Still other IT pros say the use of fog computing vs. edge computing depends specifically on the location of the distributed compute and storage resources. If processing capabilities are embedded directly in a connected endpoint, they call that edge computing. But, if intelligence resides in a separate network node stationed between an endpoint and the cloud, such as a local node or IoT gateway, then it's fog.







