Top 10 edge computing use cases and examples
The move to edge computing will increase over the next few years. Here, we list the areas where it's proving to deliver high value.

The use of edge computing in the enterprise is dramatically expanding as companies and consumers connect more devices to the internet, as superfast 5G network services expand their reach and as organizations pursue opportunities enabled by the technology.
Statistics back that up: According to the "2021 IoT and Edge Commercial Adoption Survey" from the Eclipse Foundation, 54% of organizations are either using or planning to use edge computing technologies within 12 months, with another 30% planning to evaluate edge deployments within the next two years.
Additionally, 30% expect to spend between $100,000 to $1 million on those initiatives, and 16% plan to spend more than $1 million.
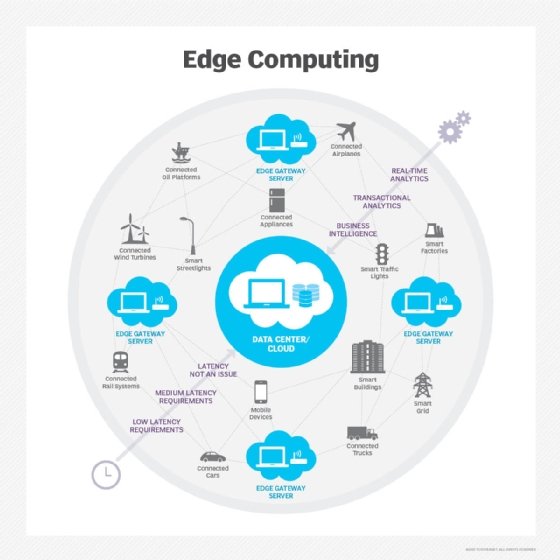
Even more telling, perhaps, is the growing number of executives paying attention to edge computing, which puts the processing power needed for artificial intelligence, machine learning and other analytics programs close to data-generating endpoints. The 2021 survey found that executives drive 35% of those spending decisions, up from 18% in the 2019 survey. This indicates that edge computing, and more broadly the IoT ecosystems in which edge fits, are becoming strategic objectives.
Notable edge computing use cases include the following:
1. Autonomous vehicles
Autonomous vehicles are a prime edge computing use case, as they can only operate safely and reliably when they're able to analyze in real time all the data required to drive. Real-time analysis in the cloud, however, can be problematic; the volume of data generated by autonomous vehicles and the corresponding potential for latency -- or even a lack of needed connectivity -- when sending data to the cloud could mean unsafe delays. The volume of data that these vehicles amass is staggering. Industry estimates on data generation vary significantly, but they all put data generation in the terabytes.
Morgan Stanley Global Telecom researchers, for example, have estimated that autonomous vehicles could produce upward of 40 TB of data an hour. Certainly, 5G will be able to handle more capacity than the existing 4G network, but it's still not capable of guaranteeing the ability to transmit all that data to the cloud for processing as fast as needed for self-driving vehicles. Consequently, onboard computing power and edge data centers are needed for mission-critical processing for navigation, vehicle-to-vehicle communications and integration with emerging smart cities.
2. Smart cities
Civic authorities are also using edge computing to create smart communities and run their roadways with capabilities such as intelligent traffic controls. Edge supports a host of areas within this broad category. It helps civic authorities, such as traffic agencies, public transformation departments and private transportation companies better manage their vehicle fleets and overall traffic flow by enabling rapid adjustments based on real-time, on-the-ground conditions. For example, edge computing platforms deployed to process vehicle data can determine which areas are experiencing congestion and then reroute vehicles to lighten traffic.
Additionally, civic authorities -- such as city workers and regional planners -- can deploy edge devices to process data coming from sensors on power grids, public infrastructure, public facilities, private buildings and other locales to instantly assess needs and speed response.
3. Stronger security
Edge computing can strengthen security both in commercial and consumer deployments. Organizations can use edge computing to enable video monitoring and biometric scanning as well as other surveillance and authorization measures, where analyzing data in real time is needed to confirm that only authorized individuals and approved activities are taking place.
Companies, for example, can use a biometric security product with optical technologies to perform iris scans with edge devices instantly analyzing those images to confirm matches of workers with authorized access. Meanwhile, consumer security products, such as video doorbells and security cameras, likewise benefit from the real-time analysis that edge computing -- often in the form of fog nodes deployed in the home network -- delivers.
4. Healthcare
Healthcare data is coming from numerous medical devices, including those in doctor's offices, in hospitals and from consumer wearables bought by patients themselves. But all that data doesn't need to be moved to centralized servers for analysis and storage -- a process that could create bandwidth congestion and an explosion in storage needs.
Instead, edge devices can ingest and analyze data coming from endpoint medical devices to determine what data can be discarded, what should be retained and, more critically, what requires immediate action. Consider, for example, data from a cardiac device; an edge device could hold a program designed to aggregate normal readings for reporting but instantly alert to an abnormal one that requires emergency attention. Edge computing also plays a critical role in medical care delivery, such as robot-assisted surgery, where real-time data analysis is essential.
5. Manufacturing and industrial processes
Industrial IoT has added millions of connected devices in manufacturing plants and other such industries to gather data on production lines, equipment performance and finished products. However, all the data doesn't need to be handled in centralized servers -- every temperature reading from every connected thermometer isn't important. In some cases, moving data to the centralized servers -- whether in the cloud or on premises -- could be prohibitively expensive or impossible because of a facility's remote location. In such cases, edge computing brings needed processing power to where it's required, and those edge devices can be programmed to either transfer aggregate data back to central systems and/or initiate required actions at the endpoint.
Moreover, edge computing delivers the speed required for manufacturing and industrial operations, where automated assembly lines move rapidly and require real-time interventions to address problems. Edge computing is often used to support predictive maintenance efforts, energy efficiency initiatives, custom production runs, smart manufacturing and intelligent operations. Industrial executives are also using edge as part of an IoT ecosystem to monitor, analyze and manage energy use in their factories, plants and offices. Energy utilities themselves can use edge for monitoring and managing their own equipment in the field.
6. Virtual and augmented reality
Similar to other use cases, virtual reality (VR) and augmented reality (AR) both require the real-time processing of large data sets because any lag in analysis would delay subsequent actions. That would mean delayed images and instructions in the case of VR and AR, creating a poor -- or in some cases even an unsafe -- user experience at a time when use of these technologies is greatly expanding.
Workers use these technologies to guide them through their tasks and to learn new processes. Students use them to learn complex concepts. Individuals use them for entertainment and skills enhancement. Businesses apply the technologies to enable unique and customized experiences, such as personalized shopping displays. Edge computing enables those various experiences when bandwidth limitations, costs and/or privacy concerns make using centralized processing power a poor choice.
7. Enhanced workplace safety
U.S. private industry employers reported 2.1 million nonfatal workplace injuries in 2020, according to the federal Bureau of Labor Statistics (BLS). There were 5,333 deaths due to work-related injuries in 2019, the most recent BLS figures. But industry is using a combination of technologies -- such as endpoint sensors, computer vision and artificial intelligence, as well as edge devices -- to power workplace safety applications.
For example, companies can use locational data from on-site employees to enforce the social distancing requirements brought on by the COVID-19 pandemic, alerting them if they move and stay too close together. Because such locational data has no value beyond that moment, the information can be collected and processed on the edge rather than moved and stored in the corporate data center.
8. Streaming services and content delivery
Similar to the use of edge with augmented and virtual reality use cases, edge computing supports the low-latency requirements of video streaming and content delivery. Furthermore, it enables a good user experience for both existing and emerging features such as search functions, content suggestions, personalized experiences and interactive capabilities.
In fact, with over-the-top streaming platforms becoming the standard means for distributing content, media companies are using edge computing to deliver original content, live events and regional content with a flawless user experience -- as consumers now expect.
9. Enhanced customer services
Businesses across industries, from banking to retail, are exploring how they can use edge computing to deliver hyperpersonalized experiences and targeted ads to customers. They're also developing ways to use edge computing to support new services, such as AR-enabled interactive shopping.
10. Smart homes
The volume of data being generated and transmitted by households has exploded as homes have gone high-tech, with everything from AI-enabled virtual assistants -- such as Amazon's Alexa -- to connected security systems to smart speakers all adding traffic to the available bandwidth. Edge computing located within the home could ease the strain on service provider networks, ensure real-time response and boost privacy by keeping more of the household's data close and out of third-party systems.