sharding
What is sharding?
Sharding is a type of database partitioning that separates large databases into smaller, faster, more easily managed parts. These smaller parts are called data shards. The word shard means "a small part of a whole."
Horizontal and vertical sharding
Sharding involves splitting and distributing one logical data set across multiple databases that share nothing and can be deployed across multiple servers. To achieve sharding, the rows or columns of a larger database table are split into multiple smaller tables.

Once a logical shard is stored on another node, it is known as a physical shard. One physical shard can hold multiple logical shards. The shards are autonomous and don't share the same data or computing resources. That's why they exemplify a shared-nothing architecture. At the same time, the data in all the shards represents a logical data set.
Sharding can either be horizontal or vertical:
- Horizontal sharding. When each new table has the same schema but unique rows, it is known as horizontal sharding. In this type of sharding, more machines are added to an existing stack to spread out the load, increase processing speed and support more traffic. This method is most effective when queries return a subset of rows that are often grouped together.
- Vertical sharding. When each new table has a schema that is a faithful subset of the original table's schema, it is known as vertical sharding. It is effective when queries usually return only a subset of columns of the data.
The following illustrates how new tables look when both horizontal and vertical sharding are performed on the same original data set.
Original data set
| Student ID | Name | Age | Major | Hometown |
| 1 | Amy | 21 | Economics | Austin |
| 2 | Jack | 20 | History | San Francisco |
| 3 | Matthew | 22 | Political Science | New York City |
| 4 | Priya | 19 | Biology | Gary |
| 5 | Ahmed | 19 | Philosophy | Boston |
Horizontal shards
Shard 1
| Student ID | Name | Age | Major | Hometown |
| 1 | Amy | 21 | Economics | Austin |
| 2 | Jack | 20 | History | San Francisco |
Shard 2
| Student ID | Name | Age | Major | Hometown |
| 3 | Matthew | 22 | Political Science | New York City |
| 4 | Priya | 19 | Biology | Gary |
| 5 | Ahmed | 19 | Philosophy | Boston |
Vertical Shards
Shard 1
| Student ID | Name | Age |
| 1 | Amy | 21 |
| 2 | Jack | 20 |
Shard 2
| Student ID | Major |
| 1 | Economics |
| 2 | History |
Shard 3
| Student ID | Hometown |
| 1 | Austin |
| 2 | San Francisco |
Benefits of sharding
Sharding is common in scalable database architectures. Since shards are smaller, faster and easier to manage, they help boost database scalability, performance and administration. Sharding also reduces the transaction cost of the database.
Horizontal scaling, which is also known as scaling out, helps create a more flexible database design, which is especially useful for parallel processing. It provides near-limitless scalability for intense workloads and big data requirements. With horizontal sharding, users can optimally use all the compute resources across a cluster for every query. This sharding method also speeds up query resolution, since each machine has to scan fewer rows when responding to a query.

Vertical sharding increases RAM or storage capacity and improves central processing unit (CPU) capacity. It thus increases the power of a single machine or server.
Sharded databases also offer higher availability and mitigate the impact of outages because, during an outage, only those portions of an application that rely on the missing chunks of data become unusable. A sharded database also replicates backup shards to additional nodes to further minimize damage due to an outage. In contrast, an application running without sharded databases may be completely unavailable following an outage.
Another advantage of sharding is that it increases the read/write throughput when such operations are confined to a single shard.
Difference between sharding and partitioning
Although sharding and partitioning both break up a large database into smaller databases, there is a difference between the two methods.
After a database is sharded, the data in the new tables is spread across multiple systems, but with partitioning, that is not the case. Partitioning groups data subsets within a single database instance.
Types of sharding architectures
The following are the key types of sharding architectures.
Key-based sharding
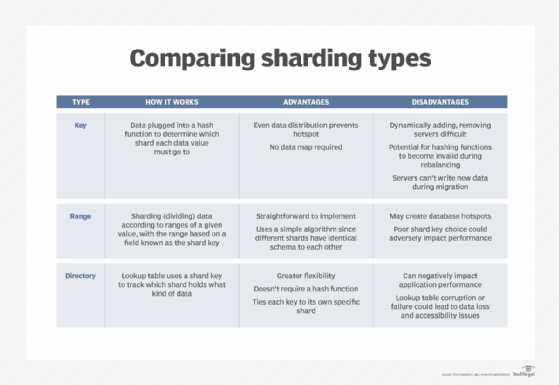
In key-based sharding, which is also known as hash-based sharding, the data is plugged into a hash function to determine which shard each data value must go to.
A hash function takes a piece of input data and generates a discrete output value known as the hash value. In key-based sharding, the hash value is the shard ID, which determines in which shard the data is stored. The values entered into the hash function all come from the same column, known as the shard key, to ensure that entries are placed consistently and with the appropriate accompanying data in the correct shards.
This key is static -- i.e., its values don't change over time. If they do, it could slow down performance.
To understand key-based sharding, consider this example.
Column 1 in a large database
| Column 1 |
| MN |
| OP |
| AB |
| CD |
Once the column passes through the hash function, hash values are generated based on the shard ID. The columns with similar hash values are stored in the same shard.
| Column 1 | Hash Values |
| MN | 2 |
| OP | 1 |
| AB | 2 |
| CD | 1 |
So, the two shards might look like the following.
Shard 1
| Column 1 | Column 1 |
| OP | Value 1 |
| CD | Value 2 |
Shard 2
| Column 1 | Column 1 |
| MN | Value 3 |
| AB | Value 4 |
Advantages of key-based sharding
- suitable for distributing data evenly to prevent hotspots; and
- no need to maintain a data map, since data is distributed algorithmically.
Disadvantages of key-based sharding
- difficult to dynamically add or remove additional servers to the database;
- during data rebalancing, both new and old hashing functions could become invalid; and
- during migration, servers cannot write any new data, which may lead to application downtime.
What is range-based sharding?
As the name suggests, range-based sharding involves sharding data according to the ranges of a given value. The range is based on a field, which is known as the shard key.
For example, with a database that stores information about students' marks, shards can be used to classify the data based on different ranges of marks.
| Student | Marks |
| Adam | 89 |
| Ben | 95 |
| Catherine | 54 |
| David | 33 |
| Elizabeth | 68 |
| Ali | 76 |
Shard 1. Students with marks between 0 and 60
| Student | Marks |
| Catherine | 54 |
| David | 33 |
Shard 2. Students with marks between 60 and 85
| Student | Marks |
| Elizabeth | 68 |
| Ali | 76 |
Shard 3. Students with marks between 85 and 100
| Student | Marks |
| Adam | 89 |
| Ben | 95 |
Advantages of range-based sharding
- straightforward implementation; and
- simple algorithm since different shards have identical schema to each other, as well as the original database.
Disadvantages of range-based sharding
- may create database hotspots, since data could be unevenly distributed; and
- a poor choice of shard key could create unbalanced shards and adversely impact performance.
What is directory-based sharding?
In directory-based sharding, a lookup table is created and maintained. It uses a shard key to track which shard holds what kind of data.
Consider a database that holds student information.
| Section | Student First Name | Student Last Name |
| C | Alex | Hales |
| B | Ben | Davies |
| A | Craig | Hall |
| D | David | Copperfield |
The Section column below is defined as a shard key. Data from the shard key is written to the lookup table with the shard that each respective row should be written to.
| Section (Shard Key) | Shard ID |
| A | S1 |
| B | S2 |
| C | S3 |
| D | S4 |
Shard S1
| A | Craig | Hall |
Shard S2
| B | Ben | Davies |
Shard S3
| C | Alex | Hales |
Shard S4
| D | David | Copperfield |
Advantages of directory-based sharding
- provides greater flexibility in terms of dynamically assigning data to shards;
- superior to key-based sharding because it doesn't require a hash function; and
- superior to range-based sharding since it ties each key to its own specific shard.
Disadvantages of directory-based sharding
- can have a negative impact on application performance because it requires connection to the lookup table before every query or write; and
- corruption or failure of the lookup table could lead to data loss or accessibility issues.







