What is a clustered network-attached storage (NAS) system?
A clustered network-attached storage (NAS) system is a scale-out storage platform made up of multiple NAS nodes networked together into a single cluster. The platform pools the storage resources within the cluster and presents them as a unified file system.
To achieve such horizontal scaling across numerous devices, the platform uses a distributed file system that runs concurrently on every NAS node in the cluster. All the nodes in the cluster are active and can see all the files in that cluster. The file system enables each node to access all files from any of the clustered nodes, regardless of the physical location of the file.
The need for clustered NAS systems
Traditional standalone NAS systems, which comprise a single storage device, are frequently unable to keep up with today's massive data volume growth. A single NAS device can only use a limited amount of CPU, memory and storage space, which limits storage scalability. To increase capacity, new NAS devices need to be purchased.
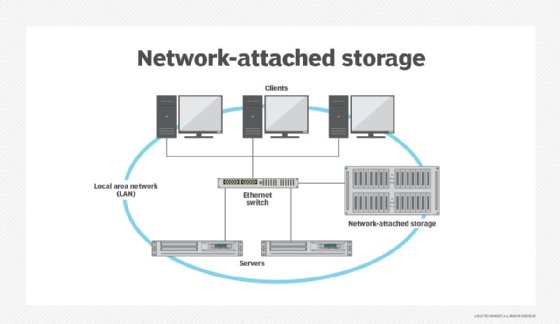
Clustered NAS effectively addresses the limitations of traditional NAS. With clustered NAS systems, storage capacity can be increased by adding storage nodes, while performance can be improved by adding controllers or enhancing current controllers' processing power.
A clustered NAS system automatically migrates existing data to newer, larger-capacity devices because of the use of a distributed file system that runs simultaneously on multiple nodes and allows all the nodes to see all the data. Also, if a device in a cluster fails, a failover feature ensures that the failure doesn't disrupt the entire cluster.
Key features of clustered NAS systems
The number and location of the nodes in a clustered NAS system are transparent to the users and applications accessing files. In addition, data and metadata can be striped across both the storage nodes and the underpinning block storage subsystems -- direct-attached storage (DAS) or storage area network (SAN). By striping the data across all the storage nodes and subsystems, clustered NAS facilitates access to the network file system from all the clustered nodes, regardless of the location of the data.
Modern clustered NAS systems can be scaled out to include numerous nodes and provide petabytes (PB) of raw capacity and ample processing power. For example, the NetApp Fabric-Attached Storage (FAS) arrays -- FAS8700/FAS9000 series -- can support up to 24 nodes in a cluster (12 high availability pairs) and up to 176 PB of raw capacity for a cluster in either a 4U or 8U controller chassis form factor.

Clustered NAS systems also provide transparent data replication and fault tolerance. If one or more nodes fail, the system continues to function without data loss. The clustered systems also independently perform load balancing among nodes without human intervention. A single image and mount point effectively provide a way to easily add nodes to increase storage capacity and space for failover.
There is no fixed configuration for NAS clusters, with each vendor taking a different approach to how the controllers and storage devices are deployed. However, they all rely on a distributed file system to present the data on an operating system (OS) to manage the volumes and protect the data. The file system and OS work together to deliver unified file services. In some cases, the file systems and OSes are combined into a single software layer, such as Dell EMC's PowerScale OneFS OS.
PowerScale OneFS is built for scale-out NAS to support demanding file-based workloads and massive scalability. This OS can run on any hardware and can be deployed in the data center, at the edge and in the public cloud.
Clustered NAS components
A clustered NAS system includes these core components:
- NAS nodes. The NAS nodes are the servers that contain hardware -- storage drives, processors and RAM -- and software to facilitate data storage and file sharing. The drives may be organized into RAID arrays.
- Storage software. The software is installed on the node hardware along with a lightweight OS. A distributed file system is an important element of the storage layer of the clustered NAS system. This system runs on multiple nodes and allows each node to see and access the files from all other nodes in the cluster.
- Networking protocol. Standard protocols, like TCP/IP, are used to combine files into packets to be sent over the network. This is required to enable the NAS nodes to communicate and transfer data.
Clustered NAS use cases
Clustered NAS is particularly useful in environments where data volumes are growing quickly, especially unstructured data volumes. Traditional NAS systems have scalability and failover limitations, but clustered NAS overcomes those limitations by providing horizontal scaling, data striping and a distributed file system.
Another key use case of clustered NAS involves users accessing the same files. A clustered NAS system can add processing power without having to add more storage nodes, and the distributed file system ensures that all nodes can see all files, making it easy for multiple users to share workflows and files.
The scalability provided by clustered NAS makes it easy for organizations to share data across multiple locations. They can also unify the data to improve process efficiencies and minimize project lags.
Other use cases of clustered NAS include the following:
- Email systems.
- Online data storage.
- Rich media data delivery.
- High-performance databases.
- High-performance caching of reference data.

What are the main benefits of clustered NAS storage?
Traditional NAS systems have served organizations well over the years, but the rapid growth of data -- especially unstructured data -- has forced decision-makers to look for more effective ways to provide storage that can meet the demands of rapidly evolving workloads.
Clustered NAS provides scale-out storage capacity that can deliver the performance and additional storage volume needed to support many data-hungry workloads, including those that require a high degree of concurrency. A clustered NAS system uses load balancing to spread the data across storage nodes and present those nodes as a single repository, helping to simplify user access and application delivery.
A clustered NAS system also offers more flexibility than traditional NAS. If an organization needs more compute or storage resources, administrators can add nodes to the cluster or beef up the individual nodes, often with the ability to scale compute (performance) and storage (capacity) resources independently. They can also remove components from the cluster as workload requirements change. Most contemporary scale-out NAS systems include built-in mechanisms that make it quick and easy to modify the cluster infrastructure and configuration.
A cluster's nodes can also be set up in a failover configuration that protects against data loss and extended downtime in the event of component failure. For example, a six-node cluster might be organized into three sets, with each set including two nodes deployed in an active/passive configuration. If a node fails, it automatically fails over to the passive node within that set.
Some clustered NAS solutions include strong security features, like volume encryption. Encrypting data helps protect its integrity, regardless of its volume.
Clustered NAS vendors
Many storage vendors offer clustered NAS products, including the following:
- Dell. Dell's Fluid File System clustered NAS system is based on up to four NAS appliances, each with a pair of controllers and storage arrays to enable dynamic increase in capacity. The product uses a distributed file system to create a single interface to the data. It also provides administrative functions and a web-based NAS management console for storage management.
- IBM. IBM's Spectrum NAS is a software-defined storage and massively scalable clustered NAS product line. It creates storage clusters out of bare-metal servers, with each node in the cluster functioning as a self-sustained server. The file system spans over the entire cluster, providing a flexible, easily manageable storage environment.
- NetApp. NetApp's FAS9500, FAS8700 and FAS8300 series of FAS appliances enable organizations to scale performance and capacity on demand. These device families can satisfy high-throughput demands and are based on the NetApp snapshot technology for high stability, scalability and data recoverability.
Many other vendors also offer high-performance clustered NAS products, including economical systems for small and medium-sized businesses from TerraMaster, Synology, StoneFly and QNAP.
Clustered NAS vs. virtualization
Although clustering appears similar to file virtualization, the key difference is that, with a few exceptions, the system nodes in a clustered NAS must be from the same vendor and part of the same product line from that vendor.
For example, an organization can create a cluster made up of Dell's PowerStore T appliances or PowerStore X appliances, but a single cluster cannot contain both types of Dell appliances. However, administrators can typically configure a cluster's nodes with different types of storage devices or with different capacities, unless two nodes are set up in a failover configuration.
Also, the main purpose of NAS clustering is to create a scalable storage solution where multiple NAS nodes work together as a single storage unit to provide additional capacity. Virtualization is typically used to create virtual instances of servers -- virtual machines -- on a physical server.
Maximize the potential of your rackmount NAS appliance by setting up admin accounts, assigning permissions, managing network access, performing a diagnostic check and configuring advanced settings. Check out this step-by-step configuration guide on how to set up a NAS.
Continue Reading About What is a clustered network-attached storage (NAS) system?
Dig Deeper on Primary storage devices
-
![]()
Build a cloud-ready, global distributed file system
By: Kurt Marko
-
![]()
Qumulo hybrid cloud NAS provides special effects for Cinesite
By: Antony Adshead
-
![]()
High-performance object storage challenges in the modern data center
By: George Crump
-
![]()
Isilon’s multi-dot upgrade to OneFS 8.2.2 masks big changes
By: Yann Serra



