AWS rolled out AI Factories this week, entering a crowded market for hybrid cloud AI infrastructure against stiff competition.
AI Factories are similar to AWS Dedicated Local Zones, but bundle in AI-specific hardware, including UltraServers with AWS Trainium chips or Nvidia GPUs, along with access to AWS services such as SageMaker and Bedrock. They are also similar to products available from Oracle, HPE, Lenovo, Broadcom, IBM/Red Hat and Dell, to name a few.
"Effectively, AWS AI Factories operate like a private AWS region, letting customers leverage their own data center space and power capacity that they've already acquired," said AWS CEO Matt Garman during a keynote presentation at the annual AWS re:Invent conference this week. "It helps them with … maintaining the security and reliability that you get from AWS while also meeting stringent compliance and sovereignty requirements."
While it's clear that data sovereignty and cost concerns are driving some enterprises to set up AI infrastructure on-premises, it's less obvious how AWS will distinguish itself in this market, according to industry analysts.
"AWS is acknowledging that for many enterprises, data is hybrid, and AWS's announcement is a realization that enterprise customers are struggling with the dilemma, 'Do we bring the AI to the data, or the data to the AI?'" said Steven Dickens, CEO and principal analyst at HyperFrame Research. "But on-premises vendors such as Dell, Lenovo and HPE are all focused on on-premises AI factories and have been for two years."
Meanwhile, another analyst wondered whether AWS can match the professional services capacity of enterprise data center infrastructure competitors.
"You need boots on the ground to install and maintain hardware at customer data centers," said Larry Carvalho, principal consultant at RobustCloud. "Amazon does have partners that can install Outposts, but there may be some customers who would prefer to have Amazon own that responsibility for AI Factories."
AWS PR did not respond to requests for comment on AI Factories professional services capacity as of press time.
Matt Garman
Trainium challenges Nvidia on efficiency
Garman's keynote presentation Tuesday also touted the latest advances in AWS Trainium custom chips for AI model training and inference workloads, as well as its Project Rainier multi-campus cluster installation with Anthropic to train its next-generation Claude models. Trainium is already a multi-billion-dollar business for AWS, Garman said, and more than 1 million Trainium chips have been deployed to date.
"We named it Trainium because it's designed to be an awesome chip for AI training … but as it turns out, Trainium2 is actually the best system in the world currently for inference," Garman said. "Customers often ask me, 'How can I best take advantage of the benefits of Trainium?' And what I tell them is that you are probably already using it, and you just didn't know it. In fact, if you look at all the inference that's running in Amazon Bedrock today, the majority is actually powered by Trainium already."
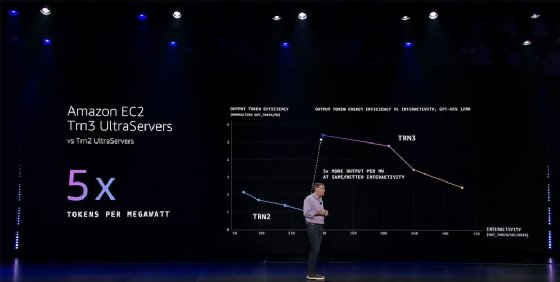
This week, AWS announced the general availability of its Trainium3 chip in UltraServers, highlighting improved efficiency over earlier versions, with support for up to five times more AI tokens per megawatt of power compared to Trainium2-based systems. Such hardware efficiency has become a key competitive factor for enterprise AI infrastructure vendors, including Cisco and Broadcom, as multi-campus data center clusters already require more power than city grids can supply.
Combined with other alternatives like AMD and Google TPU, Trainium may add up to become an obstacle to Nvidia's growth.
Larry CarvalhoPrincipal consultant, RobustCloud
Garman offered a "sneak peek" during his presentation of Trainium4, which will feature six times the performance, four times the memory bandwidth and four times the capacity of Trainium3.
AI chip competitors to Nvidia, which generally has a stranglehold on the enterprise market so far, are always welcome, Carvalho said. He and Dickens had been among analysts who pointed out the risks of Nvidia's dominance during the Cloud Native Computing Foundation's KubeCon + CloudNativeCon 2025.
"Nvidia still has an advantage due to the use of CUDA for a large percentage of AI workloads," Carvalho said. "However, combined with other alternatives like AMD and Google TPU, Trainium may add up to become an obstacle to Nvidia's growth."
Trainium and TPUs will appeal to customers seeking cost efficiency, but is unlikely to unseat Nvidia at the high end of GPUs optimized for performance, Dickens said.
In addition to scale and efficiency, Garman touted the resiliency of AWS AI infrastructure, including its GPU-based cloud hardware, where server reboots would present serious challenges for AI workloads.
"We've learned to operate GPUs at scale -- in fact, if you talk to anyone who's run large GPU clusters at any other provider, they'll tell you that AWS is by far the most stable at running a GPU cluster," he said. "We're much better at avoiding node failures … because we sweat the details, minor things like debugging BIOS to prevent GPU reboots."
AWS CEO Matt Garman presents efficiency gains in the latest version of Trainium-based EC2 instances during a keynote presentation at AWS re:Invent 2025.
Beth Pariseau, a senior news writer for Informa TechTarget, is an award-winning veteran of IT journalism covering DevOps. Have a tip? Email her or reach out @PariseauTT.