native code

What is native code?
Native code is binary data compiled to run on a processor, such as an Intel x86-class processor. The code is written in all 1s and 0s that must conform to the processor's instruction set architecture (ISA). Native code provides instructions to the processor that describe what tasks to carry out. All instructions must be submitted to a processor as native code because it's the only language it can understand. Native code is also referred to as machine code or machine language.
Each CPU includes an ISA that specifies what the processor can do. The ISA is built into the CPU as part of its microarchitecture and serves as an interface between the computer's hardware and software. The ISA defines the set of commands that can be performed by the CPU. The machine code must be compiled or assembled specifically for the processor's architecture and ISA. Two of the most common types of ISAs are complex instruction set computer (CISC) and reduced instruction set computer (RISC).
Some computers include an emulator that makes it possible to run a program whose machine code wasn't created for that specific architecture. In such a case, the computer emulates the program's original target processor by running the program in emulation mode on the new processor. When emulation is used, the program usually runs more slowly than it would in native mode on the original processor. Alternatively, the program can be rewritten and recompiled so that it runs on the new processor in native mode.
How is native code generated?
The way in which machine code is generated varies from one environment to the next, depending on the nature of the software. The process often starts with a high-level programming language such C, C++, C#, Visual Basic (VB), Java, Python, Swift, Go, PHP or one of many others. The source code created in one of these languages is converted to machine code, either directly or through one or more intermediary steps.
One approach is to use a compiler to convert the source code to assembly code and then use an assembler to generate the machine code. The machine code might then be fed into a linker that produces an executable file containing the machine code. The graphic below provides an overview of the source code conversion process.
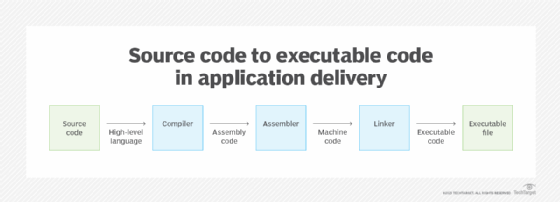
What other approaches generate machined code?
This isn't the only approach to generating machine code. The .NET Framework, for example, uses language-specific compilers to convert source code to Intermediate Language (IL), which is then submitted to the Common Language Runtime (CLR).
The CLR contains a just-in-time compiler (JIT) to convert IL code into machine code for the target platform. Together, the CLR and JIT compiler help to improve application performance, while offering numerous other benefits, such as support for custom attributes, structured exception handling, and explicit free threading for multithreaded and scalable applications.
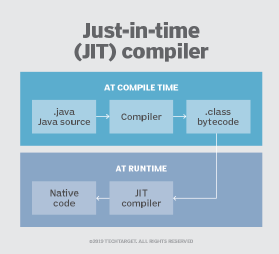
Java takes a similar approach to the .NET languages. From the Java source code, the compiler generates bytecode, which is then fed into the Java virtual machine (JVM) running on a target system. The JVM is part of the Java Runtime Environment (JRE). It interprets the bytecode and converts it to machine code specific to the target processor architecture. The JVM also includes a JIT compiler for processing the bytecode, which yields better application performance.
Not all software begins with a high-level programming language. Some start with an assembly language, which is considered a low-level language. Like a high-level language, an assembly language is written in plain text and is human readable.
Short descriptive words, known as mnemonics, are used to represent each instruction. For example, in the x86 assembly language, add means add, sub means subtract and inc means increase by one. An assembler is used to convert the assembly language to machine code.






