heartbeat (computing)

What is a heartbeat in computing?
In computing, a heartbeat is a program that runs specialized scripts automatically whenever a system is initialized or rebooted. In systems running a heartbeat program, two or more nodes communicate with each other by exchanging packets called "heartbeats" at the rate of approximately 2 hertz (Hz) (twice per second). The name of the program comes from the regularity of the packet exchanges.
In simple terms, a heartbeat refers to a periodic communication packet between nodes. Also known as a status message, a heartbeat can be a broadcast, unicast or multicast packet of length about 150 bytes.
Both hardware and software send heartbeat signals to indicate that they are operating normally. So, a heartbeat is a signal to periodically check the status of services and determine their availability and reachability. Sometimes, nodes might send heartbeats to synchronize with the other parts of a computer system.
Heartbeat messages are sent from the originating node from the time it starts up and until it shuts down. Also, they are usually sent nonstop on a periodic basis (at regular intervals) to the order of seconds. If the destination node does not detect a heartbeat from the sending node (originator) during an anticipated arrival period, the destination might conclude that the originator is unavailable or has failed or has shut down. Originally designed for two-node Linux-based clusters, heartbeats are extensible to larger configurations.
Why do you need heartbeats?
The purpose of a heartbeat is to monitor the health of nodes in a network. Heartbeats are also meant to prevent cluster partitioning, which occurs in a cluster due to loss of communication between (one or more) nodes in that cluster. When a cluster partition is detected, the cluster resource services will limit the actions that can be performed on the nodes in the partition.
The heartbeat mechanism is vital for mission-critical systems where high availability and minimal downtime are must-haves. The mechanism provides a way to detect the failure, shutdown or unavailability of nodes belonging to a network cluster. Such detections enable the system to automatically adapt and rebalance by initiating a failover. It does this by using the remaining redundant nodes on the cluster to take over the load of the failed node or nodes, ensuring uninterrupted or near-uninterrupted service.
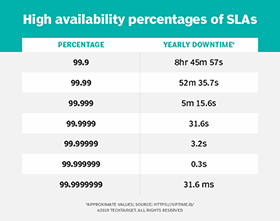
Heartbeats are also useful when there are specific and stringent service-level agreements (SLAs) regarding service uptime and availability. Security is another useful use case for heartbeats, particularly when there is a need to keep outsiders -- unauthorized and malicious users -- out of the services on a private enterprise server.
How do heartbeats work?
When the heartbeat function is configured, each cluster node sends heartbeat messages at specific intervals to other cluster nodes. It also anticipates receiving these messages from the other nodes and also at specific intervals. If a receiving node stops receiving heartbeats from another node for a few heartbeat intervals, it recognizes that a failure or shutdown has occurred on the sending node.
Heartbeat messages can be sent over TCP/IP networks, and also over storage area networks (SANs) and cluster repository disks. That said, the heartbeat function is usually configured to use specific paths between nodes. These paths allow heartbeats to monitor the health of networks, network interfaces and the cluster nodes.
The mechanism can be configured to ping all DNS-resolvable IP addresses for a particular hostname to ensure that all load-balanced services can be checked for availability. During configuration, monitors must be specified to identify the hostnames that the heartbeat is meant to check. Each monitor will run based on a user-defined schedule and different monitors can be configured with different heartbeat schedules.
For example, one monitor can be configured to run every five minutes, while another can run between the hours of 8:00 (8 a.m.) and 18:00 (6 p.m.). Users also define how long the heartbeat daemon running on a node should wait before assuming that something has gone wrong on another node.
Nodes and heartbeats in multinode systems
When a heartbeat is configured in a multinode system, one machine is designated as the primary node and the other as the secondary node. If the primary node fails or requires downtime, the secondary node can take over the primary role.
A script called "shoot the other node in the head (STONITH)" shuts down the primary node before the secondary node comes online. STONITH prevents "split-brain" operation, with the consequent risk of file corruption, that could occur if both nodes attempt to play the primary role at the same time.
Physical paths of heartbeats
Suppose a heartbeat is configured for a primary server and a backup server. The heartbeat daemon -- which is a program that runs in the background -- runs on the backup server and listens to the heartbeats coming from the primary server. If the backup server does not hear the heartbeat, it initiates a failover and takes control of the resource originally owned by the primary server.
The primary node is considered active as long as heartbeats are received on at least one of the physical connections. Usually, the mechanism is configured to work over a physical connection (e.g., a serial cable) between the two servers, although the backup server can also check for heartbeats from the primary server over a normal Ethernet network connection.
Using physical paths to connect the servers provide redundancy for heartbeat control messages, which is critical for no-single-point-of-failure configurations. The normal Ethernet network, which connects systems to each other on the network, is not the ideal path for sending heartbeats, because it adds extra traffic to the network. Also, an Ethernet connection is not as secure as say a serial connection to send heartbeats.
On the other hand, a new Ethernet network or crossover cable eliminates the distance limitation between servers, which is common to serial connections. Ethernet paths also allow the synchronization of file systems on the primary and backup servers.
Learn how VMware vSphere HA capabilities ease VM management and see how to prevent host isolation during network maintenance.