MPP database (massively parallel processing database)

What is an MPP database (massively parallel processing database)?
An MPP, or massively parallel processing, database is a database that is optimized to be processed in parallel for many operations to be performed by many processing units at a time.
MPP is the coordinated processing of a program by multiple processors working on different parts of the program. Each processor has its own operating system (OS) and memory.
MPP databases are a type of data warehouse where multiple nodes (servers) take care of processing. In other words, the processing is split among multiple nodes. The processors communicate with each other to speed up responses to queries, especially queries related to complex searches on large data sets. Without MPP, large database performance would be suboptimal and running even simple queries would take a long time.
How MPP databases work
MPP databases use multicore processors, multiple processors and servers, and storage appliances equipped for parallel processing. That combination enables reading many pieces of data across many processing units at the same time for enhanced speed. This method is necessary because the frequencies of processors are hitting the limits of the technologies used and are slow to increase.

In splitting up processing among multiple nodes, one node acts as the leader node. This node communicates with all other compute nodes and instructs them. The compute nodes listen to the leader node and run queries. They also divide large tasks into smaller, more manageable tasks (chunks) and work on these tasks independently and simultaneously (i.e., in parallel) to speed up processing and deliver query results faster. Adding more processors to the database along with a high-bandwidth connection between the nodes further accelerates processing, which can provide huge performance and processing benefits for a large database.
In an MPP database, a node usually refers to a server. However, desktop PCs and virtual servers can also function as nodes. Each node may have one or more processing units and is considered a building block of an MPP database.
What are MPP databases used for?
MPP databases are most suitable for decision support systems, data warehouse applications, machine learning and simulations. Scientific computing applications, where a large amount of data must be accessed and queried, also benefit from MPP databases. Cloud computing and big data analysis are other common applications of MPP databases.
Applications where massive amounts of structured data must be centralized and available from a single location also use MPP databases. Such a data warehouse allows for easy data access regardless of a user's location. It also provides a single source of truth so everyone accesses the same data at any given time.
What are the benefits of an MPP database?
MPP speeds the performance of huge databases that deal with massive amounts of data. Adding more servers (nodes) reduces the time needed to perform complex searches on large data sets. MPP databases also offer near-unlimited scalability, allowing for further acceleration of query results and faster data access.
MPP databases are also cost-efficient. With these databases, tasks requiring more processing power don't require the fastest or most expensive hardware. Instead, nodes can be added to distribute the workload and speed up processing without appreciably increasing hardware costs. Also, when nodes are added, the entire cluster does not become unavailable.
Another advantage of an MPP database is high reliability. If one node fails, the other nodes continue to operate, minimizing the potential for a single point of failure. Finally, MPP databases are a good choice when detailed analyses or deep insights into large or complex data warehouses are required.
MPP vs. symmetrical multiprocessing system
A symmetrical multiprocessing system (SMP) refers to a type of computing architecture that uses multiple processors, with each processor having equal access to one computer's memory, software, and input/output (I/O) resources. In addition to sharing resources in a cluster configuration, the processors also share a common OS.
The sharing of memory facilitates fast computing since the processors can communicate and synchronize quickly. Even so, these processing speeds are only suitable for applications like email and small websites where high computing power (and speed) is not required. Also, the processors have their own cache memory, which might result in cache incoherency, generating more overhead, creating bottlenecks between the processors and main memory, and reducing the overall throughput of the processors.
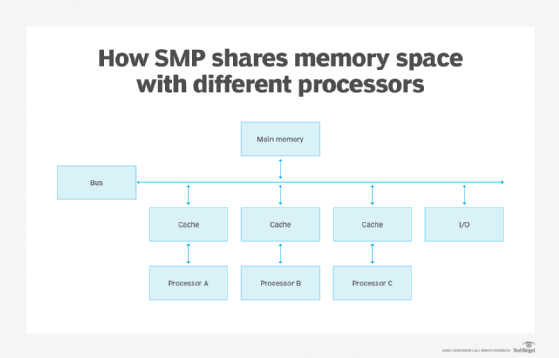
Almost all enterprises dealing with big data have databases that are massively parallel. An MPP system is considered better than a SMP system for applications that allow multiple databases to be searched in parallel. Using parallel processing, MPP databases offer faster search times than SMP databases.
SMP also provides limited scalability since all the processors share and work in the same memory within a single system. In contrast, MPP uses multiple processors that each work on a single computational problem in parallel. The number of processors can be easily increased depending on the problem type and size, making MPP databases more scalable than SMP systems.
Learn the difference between symmetrical multiprocessing system vs. massively parallel processing.







