dimension table

What is a dimension table?
In data warehousing, a dimension table is a database table that stores attributes describing the facts in a fact table. A dimension table is the physical implementation of a dimension as it is defined in a dimensional model.
A dimensional model provides a blueprint for how to structure a data warehouse to maximize query performance. Dimensions lie at the core of this model, providing reference information about a set of measurable, related events. These events are known as facts and are stored in one or more fact tables. The descriptive information in a warehouse's dimensions make it possible to filter and categorize the facts and their measures to extract meaningful answers to business questions.
A data warehouse implements a dimension's descriptive attributes as columns in a dimension table. Figure 1 shows an example of a simple data warehouse with four dimension tables (blue) and one fact table (green). The fact table references all four of the dimension tables through foreign key relationships. This includes three references to the date dimension to accommodate the different dates associated with each sale.
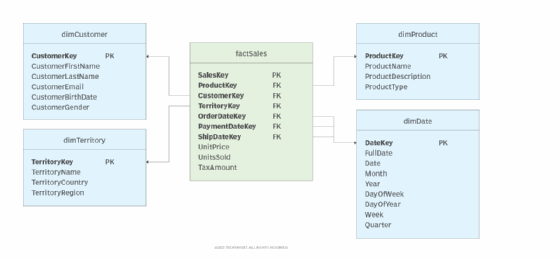
Because of the relationships between the fact table and dimension tables, the dimensions' attributes can be used to describe the events in the sales fact table and make sense of that data. To this end, the dimensions provide information about the customers, products, territories and dates involved in the sales. From this information, organizations can retrieve the information they need to make informed business decisions.
For example, the dimensions make it possible to generate a report that shows how many North American customers between the ages 35 and 45 purchased laser printers in 2022. In addition, some dimension tables, such as dimDate, contain hierarchical data that can be broken down into more granular segments. Someone viewing the report could look at the annual totals to see figures about quarterly, monthly, weekly or daily sales.
The dimension table structure
A dimension table is a table in a database, such as those found in MySQL, SQL Server or PostgreSQL. Like most database tables, the dimension table contains multiple columns and rows. Normally one column is the primary key, which uniquely identifies each row, and the other columns correspond to the attributes defined in the dimension, as determined by the data model.
A fact table in a data warehouse is configured with multiple foreign keys that reference the primary keys of the related dimension tables.

The table also provides measures for quantifying the fact data. The table's relationships to the dimensions make it possible to "slice and dice" the data by various attribute combinations to answer specific business questions.
A dimension table can use a natural key or surrogate key for its primary key. Surrogate keys are often recommended over natural keys because they are simpler values (usually integers). Surrogate keys make the join operations between the fact and dimension tables more efficient than more complex natural keys. They're also preferable when integrating source data from multiple sources. Usually the underlying platform manages and generates surrogate keys automatically.
Most dimension tables are denormalized to maximize performance to support the type of read-intensive workloads typical of a data warehouse as opposed to transactional workloads that continuously read and write data and require highly normalized structures. Denormalization helps make data analysis easier and more efficient to carry out.
Star and snowflake schemas
Denormalization plays a particularly important role in a data warehouse that uses a star schema, such as the one shown in Figure 2. In this configuration, a central fact table directly references multiple related dimension tables without requiring any sort of bridge tables to facilitate complex joins. The use of denormalized dimension tables reduces query complexity and overheard because fewer joins are required to retrieve data from the fact and dimension tables, resulting in better performance.
Another common approach to dimensional modeling is the snowflake schema, which extends the star schema by linking one or more of the dimension tables to other dimensions to create more normalized structures. For example, the dimProduct table in Figure 1 can be normalized by moving the product type data to a separate dimension table, with both dimensions joined through the table's primary key, as shown in Figure 2.
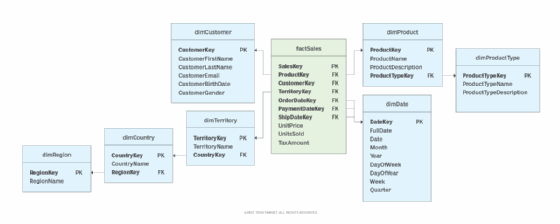
The dimTerritory dimension is also normalized in the layout. But this time, a country dimension and region dimension were added, with the tables referenced through their primary keys. Some snowflake schemas might also normalize the dimDate dimension, depending on how the data is used.
Normalizing the dimension tables in a snowflake configuration reduces the redundancy found in hierarchical data. An example is the territory dimension originally included the hierarchy regions > countries > territories. As a result, region and country data were often repeated. In a snowflake schema, the three levels of the hierarchy are normalized across the three tables.
Because the snowflake schema normalizes the data, there is less repetitive data and less storage is required. However, querying the data becomes more complex because there are more joins, which can impact performance.
Evaluate data warehouse deployment options and use cases. Explore the differences between dimension tables vs. fact tables. Check out the pros and cons of on-premises vs. cloud data warehouses.







